ExAnte
收藏arXiv2025-05-26 更新2025-05-28 收录
下载链接:
https://huggingface.co/datasets/yachuanliu/ExAnte
下载链接
链接失效反馈官方服务:
资源简介:
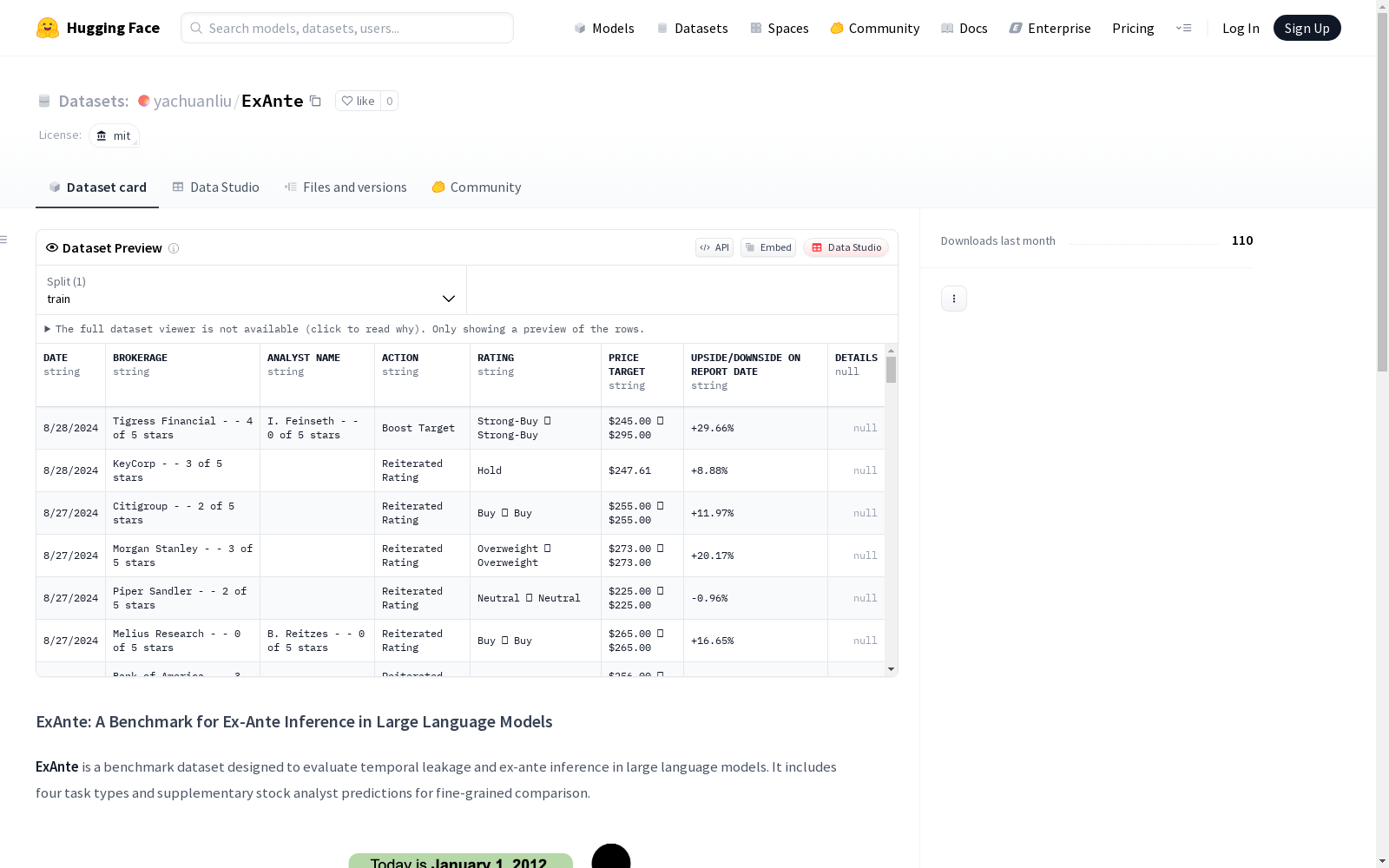
ExAnte数据集是第一个系统评估大型语言模型(LLMs)的预先推理能力的数据集。它涵盖了维基百科、股市数据、科学出版物和问答(QA),并明确区分了截止日期前后的事件。数据集旨在评估模型在没有未来事件信息的情况下进行推理的能力,这对于历史模拟、金融预测和研究趋势预测等实时敏感任务至关重要。
提供机构:
密歇根大学
创建时间:
2025-05-26
搜集汇总
数据集介绍
构建方式
ExAnte数据集的构建基于严格的时间截断原则,旨在评估大型语言模型在时间敏感任务中的推理能力。数据集涵盖股票预测、维基百科事件预测、科学出版物预测和问答任务,通过精心设计的查询和验证机制确保模型仅使用截止时间前的知识。数据收集过程包括从雅虎财经获取历史股价、维基百科的高频访问页面以及顶级计算机科学会议的出版物信息,确保数据的多样性和代表性。
使用方法
使用ExAnte需遵循三阶段流程:首先通过标准提示策略(零样本、思维链等)获取模型响应;其次利用数据集提供的验证机制检测时间泄漏(如比对生成事实与维基百科历史版本);最后结合泄漏率和质量指标进行综合评估。对于股票预测等数值任务,需额外计算预测值与人类分析师基准的误差。建议采用自验证提示策略,并可通过独立验证模式降低上下文偏差。数据集的Hugging Face版本提供标准化接口支持多模型评估。
背景与挑战
背景概述
ExAnte数据集由密歇根大学的研究团队于2025年提出,旨在评估大语言模型(LLMs)在时间约束下的推理能力,即模型在无法获取未来事件信息的情况下进行分析和预测的能力。该数据集由Yachuan Liu等人开发,涵盖了股票预测、维基百科事件预测、科学出版物预测和问答任务等多个领域,旨在解决LLMs在处理时间敏感任务时存在的“时间泄漏”问题。ExAnte的提出填补了现有自然语言处理基准在时间推理评估方面的空白,对金融预测、历史模拟和科研趋势分析等领域具有重要意义。
当前挑战
ExAnte数据集面临的核心挑战包括:1) 时间泄漏问题:即使明确设置了时间截断点,LLMs仍可能利用其内部化的未来知识生成输出,导致预测失真;2) 多领域适应性:数据集涵盖股票市场、维基百科事件、科学出版物等多个领域,要求模型能够跨领域处理时间约束下的推理任务;3) 评估指标设计:需要精确量化模型对截断时间后信息的依赖程度,同时确保评估不会因模型生成低质量或规避性回答而失效。在构建过程中,研究人员还需解决数据时间标注的准确性、事件可预测性的界定以及跨时间维度的知识验证等挑战。
常用场景
经典使用场景
ExAnte数据集在评估大型语言模型(LLMs)的时间推理能力方面具有经典应用场景。该数据集通过设定严格的时间截断点,要求模型在回答时间敏感查询时仅使用截断点之前的信息,从而模拟真实世界中未来信息不可获取的情境。这一场景特别适用于金融预测、历史事件模拟和科学研究趋势分析等领域,其中模型必须避免依赖未来知识进行推理。
解决学术问题
ExAnte数据集解决了LLMs在时间推理中的关键学术问题,即模型难以严格遵循时间截断约束,常常无意中利用未来信息进行推理。通过引入泄漏率这一量化指标,该数据集为评估模型在时间敏感任务中的表现提供了标准化框架。其意义在于揭示了现有模型在动态约束知识检索方面的局限性,为改进时间推理能力的研究奠定了基础。
实际应用
在实际应用中,ExAnte数据集可优化金融模型的回溯测试,防止未来信息泄露导致的预测偏差;辅助历史事件模拟系统(如战争推演)避免掺杂后世知识;还能提升科研趋势预测的可靠性,确保模型仅基于截断时间前的文献进行分析。这些应用对时间敏感性要求高的领域具有重要价值。
数据集最近研究
最新研究方向
近年来,ExAnte数据集在大型语言模型(LLMs)的时间推理能力评估领域引起了广泛关注。该数据集专注于评估模型在严格时间约束下的推理能力,即模型必须在不使用未来信息的情况下进行分析和预测。这一研究方向与金融预测、历史模拟和科学研究趋势预测等时间敏感应用密切相关。当前的研究热点包括如何通过提示策略(如指令引导、思维链和自我验证)减少模型的时间泄漏现象,以及探索模型架构和训练方法的改进以增强时间推理能力。ExAnte的引入为评估和改进LLMs在时间敏感任务中的可靠性提供了重要基准,推动了该领域的前沿发展。
相关研究论文
- 1ExAnte: A Benchmark for Ex-Ante Inference in Large Language Models密歇根大学 · 2025年
以上内容由遇见数据集搜集并总结生成


