MagpieLM-SFT-Data-v0.1
收藏Hugging Face2024-09-18 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/Magpie-Align/MagpieLM-SFT-Data-v0.1
下载链接
链接失效反馈官方服务:
资源简介:
该数据集由Magpie团队生成,用于监督微调。数据集包含550,000个高质量的Magpie指令,分为400,000个通用指令和150,000个推理指令。这些指令来自不同的来源,包括Magpie-Align/Magpie-Air-DPO-100K-v0.1、Magpie-Align/Magpie-Pro-MT-300K-v0.1(仅第一轮)和Magpie-Align/Magpie-Reasoning-150K。生成的响应使用了google/gemma-2-9b-it模型。数据集的许可证遵循Meta Llama 3.1社区许可证和Gemma许可证。
创建时间:
2024-09-11
原始信息汇总
MagpieLM-SFT-Data-v0.1 数据集概述
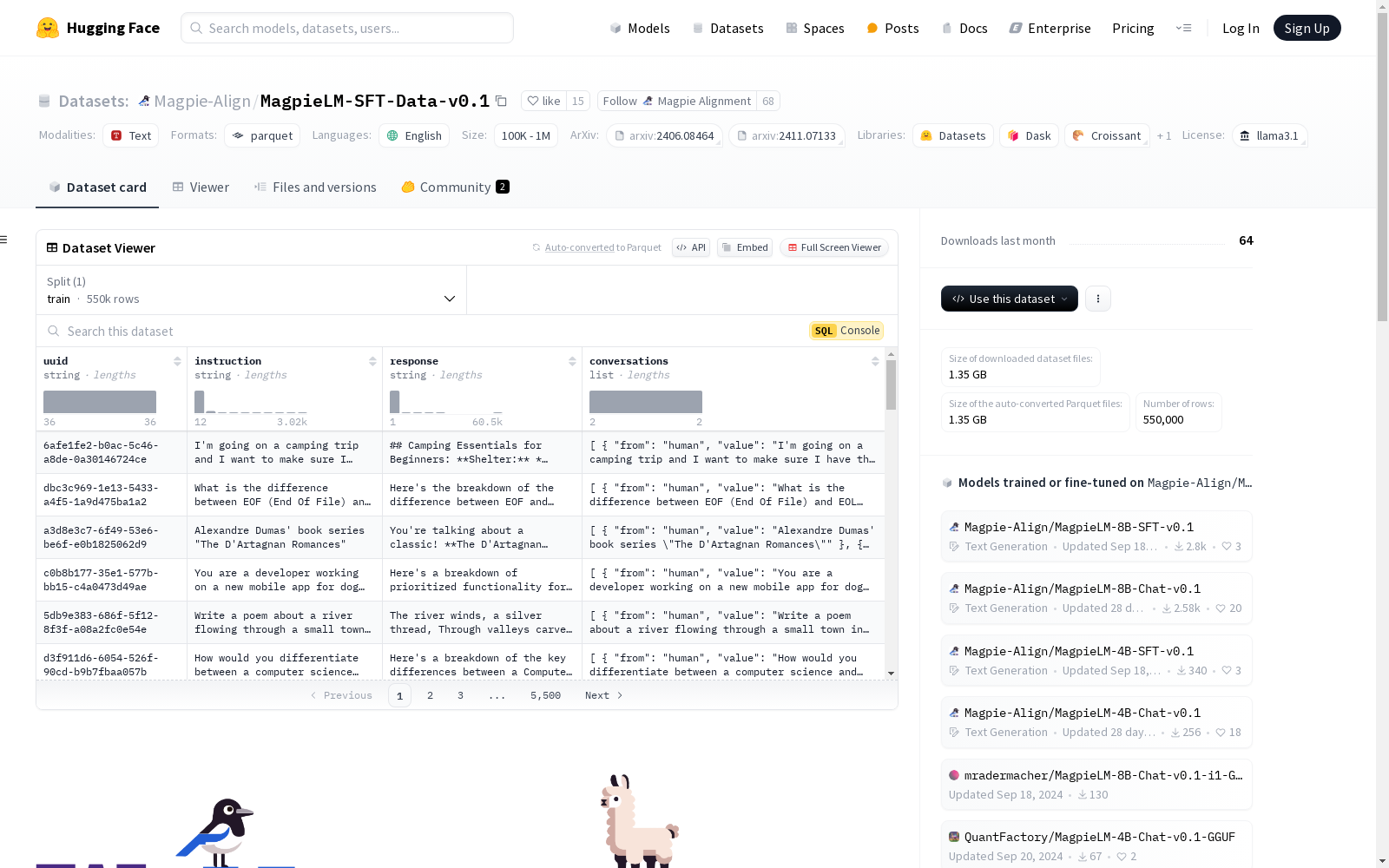
数据集信息
- 特征:
uuid: 字符串类型instruction: 字符串类型response: 字符串类型conversations: 列表类型,包含以下子特征:from: 字符串类型value: 字符串类型
- 分割:
train: 包含 550,000 个样本,占用 2,384,521,782 字节
- 下载大小: 1,351,764,157 字节
- 数据集大小: 2,384,521,782 字节
配置
- 默认配置:
data_files:train: 数据文件路径为data/train-*
数据集详情
- 生成目的: 用于监督微调
- 训练模型: 用于训练 Magpie-Align/MagpieLM-4B-SFT-v0.1
- 数据来源:
- 100K 来自 Magpie-Align/Magpie-Air-DPO-100K-v0.1
- 300K 来自 Magpie-Align/Magpie-Pro-MT-300K-v0.1(仅第一轮)
- 150K 来自 Magpie-Align/Magpie-Reasoning-150K
- 响应生成模型: 使用 google/gemma-2-9b-it 生成响应
- 许可证: 遵循 Meta Llama 3.1 Community License 和 Gemma License
引用
-
论文:
@article{xu2024magpie, title={Magpie: Alignment Data Synthesis from Scratch by Prompting Aligned LLMs with Nothing}, author={Zhangchen Xu and Fengqing Jiang and Luyao Niu and Yuntian Deng and Radha Poovendran and Yejin Choi and Bill Yuchen Lin}, year={2024}, eprint={2406.08464}, archivePrefix={arXiv}, primaryClass={cs.CL} }
联系
- Zhangchen Xu: [zxu9 at uw dot edu]
- Bill Yuchen Lin: [yuchenlin1995 at gmail dot com]
搜集汇总
数据集介绍
构建方式
MagpieLM-SFT-Data-v0.1数据集的构建过程基于高质量指令的筛选与响应生成。首先,研究团队从多个现有数据集中精选了55万条多样化的指令,涵盖400K通用任务和150K推理任务。这些指令分别来源于Magpie-Air-DPO-100K-v0.1、Magpie-Pro-MT-300K-v0.1和Magpie-Reasoning-150K数据集。随后,利用google/gemma-2-9b-it模型生成相应的响应,确保数据集的多样性和高质量。
特点
MagpieLM-SFT-Data-v0.1数据集的特点在于其广泛的指令覆盖范围和高响应质量。数据集包含55万条指令,涵盖通用任务和复杂推理任务,确保了任务的多样性。每条指令均配有由gemma-2-9b-it模型生成的响应,保证了数据的高质量。此外,数据集的结构清晰,包含uuid、instruction、response和conversations等字段,便于模型训练和评估。
使用方法
MagpieLM-SFT-Data-v0.1数据集主要用于监督微调任务,特别适用于训练和评估大型语言模型。用户可以通过HuggingFace平台下载数据集,并利用其提供的train拆分进行模型训练。数据集的结构设计便于直接输入模型进行指令微调,同时也可用于研究指令生成与响应质量之间的关系。使用该数据集时,需遵循Meta Llama 3.1社区许可证和Gemma许可证的相关规定。
背景与挑战
背景概述
MagpieLM-SFT-Data-v0.1数据集由Magpie团队于2024年创建,旨在为监督微调提供高质量的训练数据。该数据集的核心研究问题在于通过多样化的任务类别(包括400K通用任务和150K推理任务)来提升语言模型在指令微调中的表现。数据集的主要贡献者包括Zhangchen Xu、Fengqing Jiang等研究人员,他们通过整合多个高质量数据源,如Magpie-Air-DPO-100K-v0.1和Magpie-Reasoning-150K,并结合Google的Gemma-2-9B模型生成响应,推动了指令微调领域的研究进展。该数据集的研究成果已在arXiv上发表,并得到了广泛关注。
当前挑战
MagpieLM-SFT-Data-v0.1数据集在构建过程中面临多重挑战。首先,如何从海量数据中筛选出高质量的指令数据,确保其多样性和代表性,是一个关键问题。其次,尽管使用了强大的Gemma-2-9B模型生成响应,但如何确保生成的响应与指令高度对齐,仍然是一个技术难点。此外,数据集在整合不同来源的数据时,需解决数据格式和语义一致性问题。这些挑战不仅影响了数据集的构建效率,也对后续模型的微调效果产生了深远影响。
常用场景
经典使用场景
MagpieLM-SFT-Data-v0.1数据集主要用于监督微调任务,特别是在自然语言处理领域中的指令微调。该数据集包含了55万条高质量的指令数据,涵盖了多种任务类别,包括通用任务和推理任务。研究人员可以利用这些数据来训练和优化大型语言模型,使其在特定任务上表现更加出色。
解决学术问题
该数据集解决了指令微调中的关键问题,即如何通过高质量的指令数据来提升模型的泛化能力和推理能力。通过结合不同来源的指令数据,MagpieLM-SFT-Data-v0.1为研究人员提供了一个多样化的训练集,帮助他们在模型训练过程中避免过拟合,并提升模型在实际应用中的表现。
衍生相关工作
MagpieLM-SFT-Data-v0.1数据集衍生了一系列相关研究工作,特别是在指令微调和模型对齐领域。例如,基于该数据集的研究成果《Stronger Models are NOT Stronger Teachers for Instruction Tuning》揭示了在指令微调过程中,更强的模型并不总是更好的教师。这一发现为后续的模型训练策略提供了新的思路,推动了该领域的进一步发展。
以上内容由遇见数据集搜集并总结生成


