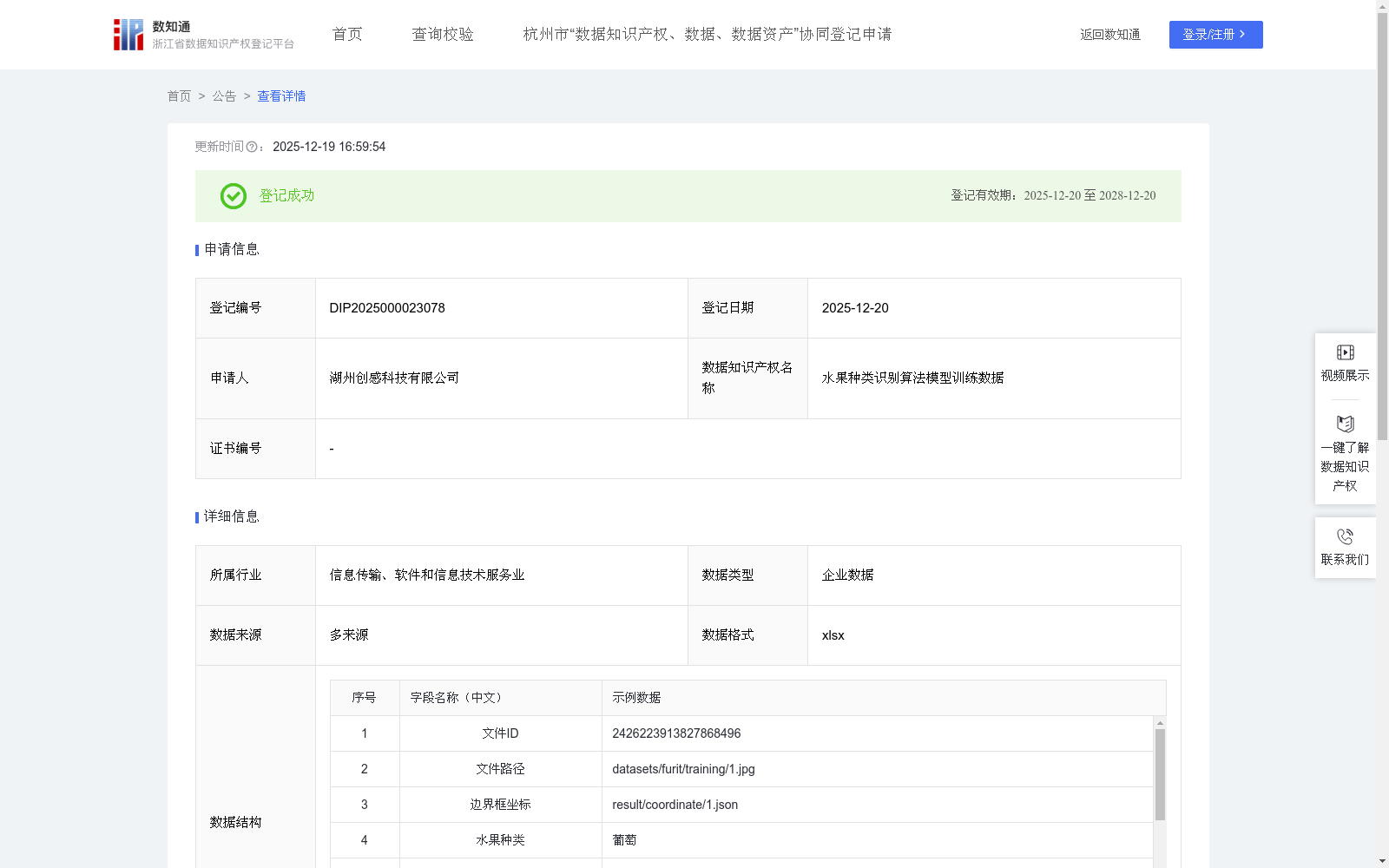
水果种类识别算法模型训练数据
收藏浙江省数据知识产权登记平台2025-12-19 更新2025-12-20 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/8416774
下载链接
链接失效反馈官方服务:
资源简介:
水果种类识别算法模型在自动化程度持续提升的食品供应链体系中,对保障水果分类的精准性与高效性发挥着不可或缺的作用。依托YOLOv10深度学习框架构建的水果种类检测系统,具备对不同品类水果进行实时识别与精准区分和水果质量判断的的能力,这一特性对于显著提升分类作业的速率与准确度、降低人工操作成本、并推动整体物流环节的优化具有重要现实意义。该模型的核心应用场景在多个领域均可使用:自动化采摘环节、加工包装流程、库存动态管理、零售终端识别、全流程质量管控及消费者科普教育等领域。总体而言,水果种类识别算法模型的深度应用,成功实现了对水果品类的快速识别与精准判定,有效提升了食品产业链各环节的运营效率与产品品质。通过相关技术的持续迭代升级与应用场景的不断拓展,模型可针对不同场景进行结合调整,为食品供应链的智能化转型与高质量发展提供有力支撑。1、数据采集:通过多种途径获取得到原始训练数据,这些数据包含了各种水果在不同场景、不同角度、不同光照条件下的图像,以及相应的标注信息。确保数据的多样性从而为提升模型的泛化能力做准备。
2、文件预处理:通过Labelimg标注工具对每张图片进行标注,把数据集进行分类为训练集、验证集和测试集。生成每个文件的ID,记录水果图片的文件路径。
3、模型训练:针对对应的YOLOv10模型训练过程中,将模型不断调整权重,固定学习率和批量大小的值,设置好权重衰减防止模型过度拟合,提高泛化能力;鉴于图片有存在多个水果的原因,识别得到的的边界框坐标存放于“result/coordinate/”文件夹中,以json文件格式进行保存,并获得定位损失;识别结果有水果的种类及对应个数和水果质量等信息,以json格式保存于"result/words_result/"文件夹中,并获得分类损失。在训练过程中,模型的训练精度随着训练进度会逐步上升。
4、模型评估:使用测试集对模型进行评估,计算模型在不同的样本数据下识别的训练精度、召回率、F1值、以及实时性能评估等性能指标,确保了模型的准确性与适应性。
5、模型应用:将最终训练后得到的模型应用到实际具体的项目中。在实际应用中,再对模型的实时性能、检测的准确性和处理速度进行检测和评估,确保满足应用需求,以达到快速、准确识别的效果。
Fruit species recognition algorithm models play an indispensable role in ensuring the accuracy and efficiency of fruit classification within the increasingly automated food supply chain system. A fruit species detection system built on the YOLOv10 deep learning framework enables real-time recognition, precise differentiation of various fruit categories, and fruit quality assessment. This capability holds significant practical value for substantially increasing the speed and accuracy of classification tasks, reducing labor costs, and promoting optimization of the overall logistics chain. The core application scenarios of this model span multiple fields: automated harvesting, processing and packaging, dynamic inventory management, retail terminal recognition, full-process quality control, and consumer science popularization and education. Overall, the in-depth application of fruit species recognition algorithm models has successfully achieved rapid and accurate identification of fruit categories, effectively improving operational efficiency and product quality across all links of the food industry chain. With continuous iterative upgrades of related technologies and expanding application scenarios, the model can be adjusted and adapted to different scenarios, providing strong support for the intelligent transformation and high-quality development of the food supply chain.
1. Data Collection: Original training data is obtained through multiple channels, including images of various fruits captured under different scenarios, angles, and lighting conditions, along with corresponding annotation information. Data diversity is ensured to prepare for improving the model's generalization ability.
2. Data Preprocessing: Each image is annotated using the LabelImg annotation tool, and the dataset is divided into training, validation, and test sets. Unique IDs are generated for each file, and the file paths of the fruit images are recorded.
3. Model Training: During the training process of the corresponding YOLOv10 model, the model's weights are continuously adjusted, with fixed learning rate and batch size values, and weight decay is set to prevent overfitting and improve generalization ability. Since images may contain multiple fruits, the detected bounding box coordinates are stored in the "result/coordinate/" folder in JSON format, and the localization loss is calculated. Information such as fruit species, their corresponding quantities, and fruit quality are saved in JSON format in the "result/words_result/" folder, and the classification loss is obtained. During training, the model's training accuracy gradually increases as the training progresses.
4. Model Evaluation: The test set is used to evaluate the model, and performance indicators such as training accuracy, recall, F1-score, and real-time performance under different sample data are calculated to ensure the model's accuracy and adaptability.
5. Model Application: The finally trained model is applied to actual specific projects. In practical applications, the model's real-time performance, detection accuracy, and processing speed are further tested and evaluated to ensure it meets application requirements and achieves rapid and accurate recognition effects.
提供机构:
湖州创感科技有限公司
创建时间:
2025-09-25
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集是用于训练水果种类识别算法模型的训练数据,规模为5296条,以xlsx格式存储,包含文件路径、边界框坐标、水果种类及模型训练参数等详细字段,支持基于YOLOv10框架的深度学习。数据集旨在提升水果分类的精准性和效率,应用于自动化采摘、包装、库存管理等食品供应链场景,通过多样化的图像数据和标注信息增强模型泛化能力。
以上内容由遇见数据集搜集并总结生成


