VATEX-QA
收藏eric-xw.github.io2024-11-05 收录
下载链接:
https://eric-xw.github.io/vatex-website/index.html
下载链接
链接失效反馈官方服务:
资源简介:
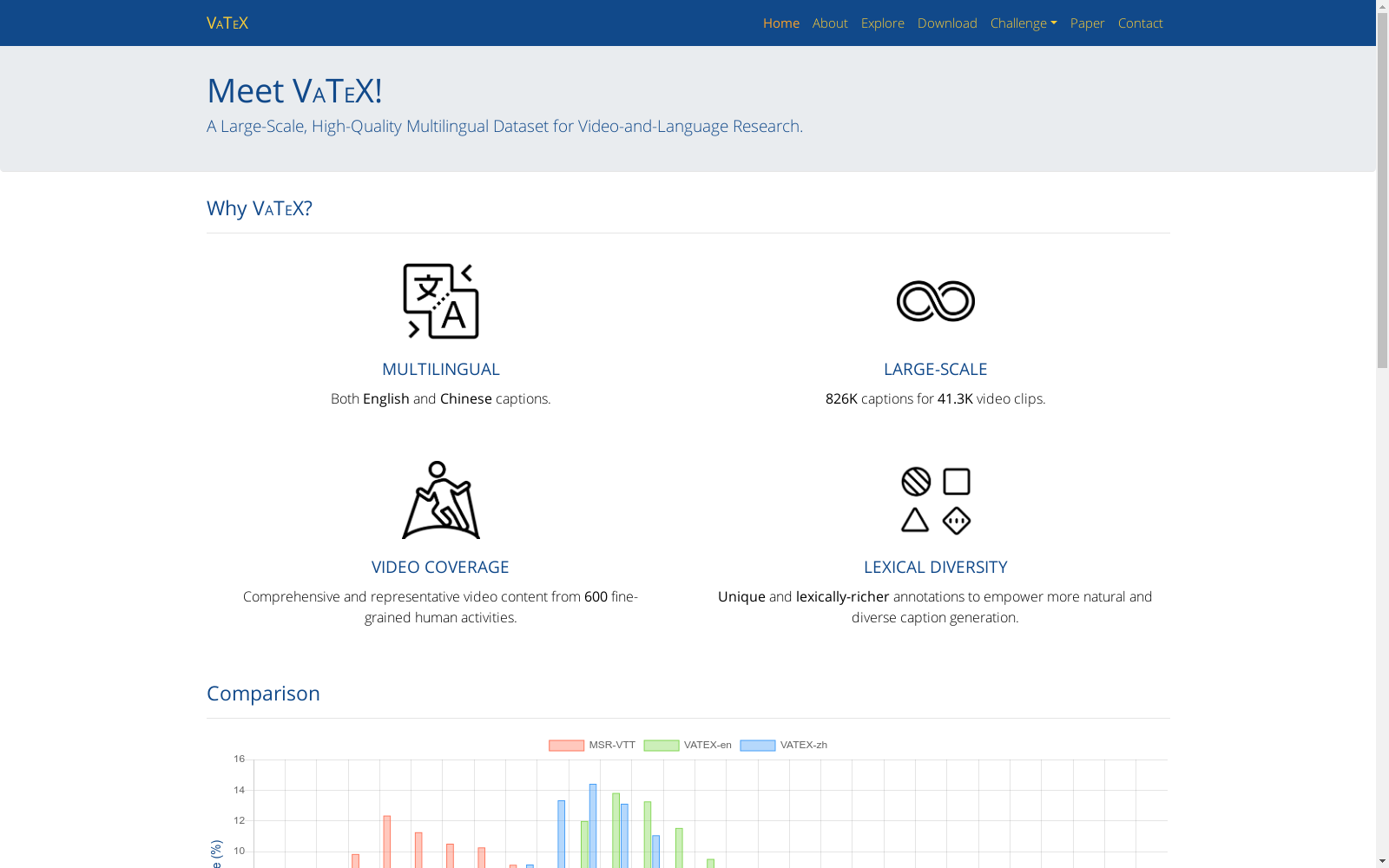
VATEX-QA是一个多语言视频问答数据集,包含来自VATEX数据集的视频片段和相应的多语言问答对。该数据集旨在促进多语言视频理解的研究。
VATEX-QA is a multilingual video question answering dataset that contains video clips sourced from the VATEX dataset and their corresponding multilingual question-answer pairs. This dataset aims to advance research in multilingual video understanding.
提供机构:
eric-xw.github.io
搜集汇总
数据集介绍
构建方式
VATEX-QA数据集的构建基于VATEX视频数据集,通过从大量视频片段中提取关键帧和相应的文本描述,进而生成视频问答对。该过程涉及多模态数据的融合,包括视觉信息和自然语言处理技术,确保问答对的准确性和多样性。
特点
VATEX-QA数据集以其丰富的多模态信息和高质量的问答对著称。它不仅涵盖了广泛的视频内容,还通过精细的标注确保了问答对的准确性和相关性。此外,该数据集支持多种语言的问答,增强了其在全球范围内的应用潜力。
使用方法
VATEX-QA数据集适用于多种视频理解任务,如视频问答、视频摘要和多模态学习。研究者可以通过该数据集训练和评估模型,以提高视频内容的理解和交互能力。使用时,建议结合具体的任务需求,选择合适的子集和预处理方法,以最大化数据集的价值。
背景与挑战
背景概述
VATEX-QA数据集是在视频理解和问答领域的一项重要贡献,由北京大学和微软亚洲研究院于2019年共同发布。该数据集旨在解决视频内容理解中的复杂问题,通过提供丰富的视频片段和相应的自然语言问答对,推动了视频问答技术的发展。VATEX-QA的构建基于VATEX数据集,后者是一个包含10万个视频片段的多语言视频数据集。VATEX-QA的发布不仅填补了视频问答领域数据集的空白,还为研究者提供了一个标准化的测试平台,促进了相关算法的创新和性能提升。
当前挑战
VATEX-QA数据集在构建过程中面临了多重挑战。首先,视频内容的多样性和复杂性使得标注工作异常困难,需要高度专业化的知识和技能。其次,问答对的生成需要确保问题与视频内容的高度相关性,这要求标注者具备深入的视频理解和语言表达能力。此外,数据集的规模和多样性也带来了存储和处理上的技术难题,如何在保证数据质量的同时高效地管理和利用这些数据,是研究者需要解决的关键问题。最后,跨语言问答的实现也是一个重要挑战,如何在不同语言之间保持问答的准确性和一致性,是该数据集未来发展的重要方向。
发展历史
创建时间与更新
VATEX-QA数据集于2019年首次发布,旨在为视频问答任务提供一个全面且多样化的基准。该数据集的最新版本于2021年更新,引入了更多的视频资源和复杂问答对,以适应日益增长的模型需求。
重要里程碑
VATEX-QA数据集的发布标志着视频问答领域的一个重要里程碑。其初始版本包含了10,000个视频片段和对应的问答对,极大地推动了视频理解技术的发展。2021年的更新进一步扩展了数据集的规模和多样性,增加了多语言支持和更复杂的问答任务,为研究者提供了更丰富的资源。此外,VATEX-QA还引入了跨模态检索任务,促进了视频与文本之间的深度融合研究。
当前发展情况
当前,VATEX-QA数据集已成为视频问答和跨模态研究的核心资源之一。其丰富的视频内容和多样的问答任务,为深度学习模型提供了宝贵的训练数据。研究者们利用该数据集开发了多种先进的视频问答模型,显著提升了视频内容的理解和推理能力。此外,VATEX-QA的多语言特性也为全球范围内的跨文化研究提供了支持,推动了视频问答技术在不同语言环境下的应用和发展。
发展历程
- VATEX-QA数据集首次发表,由北京大学和微软亚洲研究院联合发布,旨在推动视频问答领域的研究。
- VATEX-QA数据集首次应用于多个国际会议和竞赛中,如CVPR和ACM Multimedia,展示了其在视频理解任务中的潜力。
- VATEX-QA数据集的扩展版本发布,增加了更多的视频和问答对,进一步丰富了数据集的内容和多样性。
- VATEX-QA数据集被广泛应用于多个研究项目和学术论文中,成为视频问答领域的重要基准数据集之一。
常用场景
经典使用场景
在视频理解领域,VATEX-QA数据集以其丰富的多语言视频问答任务而著称。该数据集包含了大量从VATEX视频数据集中提取的视频片段,每个片段都配有相应的中英文问答对。研究者们利用这一数据集进行跨语言视频问答模型的训练与评估,旨在提升模型在不同语言环境下的理解和推理能力。通过这一数据集,研究者们能够探索如何有效地将视觉信息与语言信息相结合,从而实现更为精准的视频内容理解。
衍生相关工作
基于VATEX-QA数据集,研究者们开展了一系列相关工作。例如,有研究提出了基于多模态融合的跨语言视频问答模型,通过结合视觉和语言信息,显著提升了问答的准确性。此外,还有工作探讨了如何利用VATEX-QA进行多语言视频内容的自动标注和分类,为视频内容的智能化管理提供了新的方法。这些衍生工作不仅丰富了视频理解领域的研究内容,也为实际应用中的多语言视频处理技术提供了理论支持和技术方案。
数据集最近研究
最新研究方向
在视频理解领域,VATEX-QA数据集的最新研究方向主要集中在多模态问答系统的构建与优化。该数据集结合了视频内容与自然语言处理技术,旨在提升系统对视频内容的理解和问答能力。研究者们通过引入更复杂的视觉特征提取方法和多层次的语义融合策略,致力于解决视频问答中的多义性和上下文依赖问题。此外,跨模态信息检索和生成模型的应用也成为热点,以期在实际应用中提供更为精准和全面的视频问答服务。这些研究不仅推动了视频理解技术的发展,也为智能视频分析和交互提供了新的可能性。
相关研究论文
- 1VATEX: A Large-Scale, High-Quality Multilingual Dataset for Video-and-Language ResearchUniversity of Rochester, University of California, Santa Barbara · 2019年
- 2Video Question Answering via Gradually Refined Attention over Appearance and Motion SemanticsTsinghua University, University of California, Santa Barbara · 2020年
- 3DualVGR: Dual Video Graph Reasoning for Video Question AnsweringTsinghua University, University of California, Santa Barbara · 2021年
- 4Cross-Modal Self-Attention Network for Referring Video Object SegmentationUniversity of California, Santa Barbara, Tsinghua University · 2020年
- 5Hierarchical Modular Network for Video CaptioningTsinghua University, University of California, Santa Barbara · 2021年
以上内容由遇见数据集搜集并总结生成


