arxiv-latex
收藏Hugging Face2026-06-30 更新2026-07-01 收录
下载链接:
https://huggingface.co/datasets/scholarweave/arxiv-latex
下载链接
链接失效反馈官方服务:
资源简介:
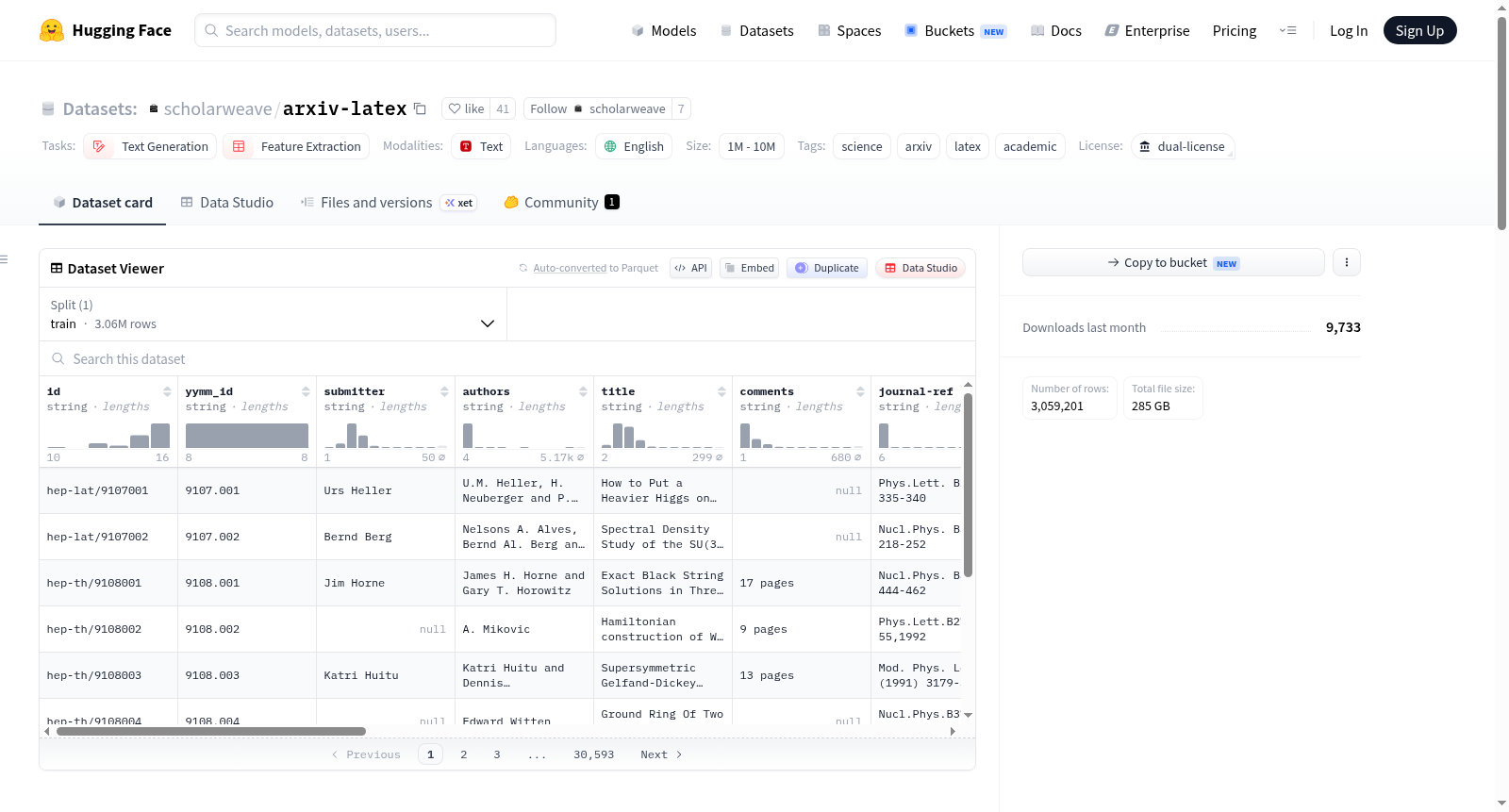
arXiv LaTeX源数据集是一个结构化的学术文献数据集,提供了arXiv平台上所有论文的LaTeX源代码及其对齐的官方元数据,以易于查询的Parquet文件格式存储。该数据集旨在解决研究人员直接处理arXiv原始数据时面临的高昂网络出口成本(完整下载费用超过450美元)和复杂的计算处理流程(原始数据为嵌套的.tar.gz压缩包)两大难题。通过作为开放镜像,在AWS us-east-1区域内完成数据摄取和处理,本数据集为用户提供了可直接下载使用的清洁、结构化数据。数据集每月更新一次,包含超过100万篇论文。每条数据记录代表一篇论文,包含以下字段:论文标识符(id, yymm_id)、提交者(submitter)、作者(authors, authors_parsed)、标题(title)、评论(comments)、期刊引用(journal-ref)、数字对象标识符(doi)、报告号(report-no)、arXiv分类(categories)、许可协议(license)、摘要(abstract)、版本历史(versions)、更新日期(update_date)以及核心的、经过解析和编译的LaTeX源代码(latex)。该数据集适用于文本生成、特征提取等自然语言处理任务,特别是在科学和学术文本分析领域。数据集的策展遵循arXiv的使用条款,单个论文内容的版权和许可由原作者保留。
The arXiv LaTeX source dataset is a structured academic literature dataset that provides LaTeX source code and aligned official metadata for all papers on the arXiv platform, stored in an easily queryable Parquet file format. It aims to address two major challenges researchers face when directly handling raw arXiv data: high network egress costs (over $450 for a full download) and complex computational processing workflows (the original data is nested .tar.gz archives). As an open mirror, the data ingestion and processing are completed in the AWS us-east-1 region, offering users clean, structured data ready for direct download. The dataset is updated monthly and contains over 1 million papers. Each data record represents a paper and includes fields such as paper identifiers (id, yymm_id), submitter, authors (authors, authors_parsed), title, comments, journal references (journal-ref), digital object identifier (doi), report numbers (report-no), arXiv categories, license, abstract, version history (versions), update date, and the core parsed and compiled LaTeX source code (latex). It is suitable for natural language processing tasks like text generation and feature extraction, particularly in scientific and academic text analysis. The curation of the dataset follows arXivs terms of use, with copyright and licensing of individual paper content retained by the original authors.
创建时间:
2026-06-18
原始信息汇总
数据集名称
arXiv LaTeX Source Dataset
数据集来源
- 地址:https://huggingface.co/datasets/scholarweave/arxiv-latex
- 简介:包含arXiv所有LaTeX源文件的完整语料库,经过预解析、格式化并与官方元数据对齐,以Parquet文件格式提供。
构建目的
解决使用arXiv论文数据时的两大难题:
- 网络出口成本:arXiv的S3存储桶(
s3://arxiv)配置为“请求者付费”,从us-east-1区域外下载完整语料(超过5TB,300万篇论文)需支付高额出口费用(每GB $0.09,一次完整下载花费超过$450)。 - 计算复杂性:原始S3数据嵌套在数百个
.tar归档中,提取、解析LaTeX代码并与JSON元数据快照匹配需要复杂的本地处理流水线。
此数据集作为开放镜像,在us-east-1区域内免费传输数据,预处理后直接提供干净的Parquet文件,无需用户支付出口费用或自行编写提取代码。
数据更新与清单
- 更新周期:每月从arXiv S3同步最新出版物和修订。
- 清单文件:维护一个XML清单文件
arxiv_parquet_manifest.xml(https://huggingface.co/datasets/scholarweave/arxiv/raw/main/arxiv_parquet_manifest.xml),映射每个Parquet分区文件的大小、MD5校验和、处理时间戳、论文ID范围及生成该文件所解包的S3.tar文件列表,支持崩溃恢复、验证和增量同步。
数据集规模
- 大小类别:1M < n < 10M(百万级论文数)
- 配置文件:
default,包含训练集(train),数据文件为arxiv_part_*.parquet
数据模式(Schema)
每一行代表一篇论文,包含元数据和解析后的LaTeX源代码:
| 列名 | 类型 | 描述 |
|---|---|---|
id |
string |
arXiv论文标识符(例如 0704.0001 或 hep-th/9901001) |
yymm_id |
string |
映射为 YYMM 格式的标准化ID,用于按时间排序 |
submitter |
string |
上传论文的用户名 |
authors |
string |
原始作者字符串 |
title |
string |
论文标题 |
comments |
string |
提交者评论或期刊参考文献 |
journal-ref |
string |
官方期刊出版引用(如已发表) |
doi |
string |
数字对象标识符(DOI) |
report-no |
string |
报告或文档系列编号 |
categories |
string |
空格分隔的arXiv类别(例如 cs.CL math.PR) |
license |
string |
论文所采用的许可协议 |
abstract |
string |
论文摘要 |
versions |
list<struct> |
版本结构列表,包含每个版本的创建时间戳 |
update_date |
string |
arXiv最后修改论文记录的日期 |
authors_parsed |
list<list<string>> |
结构化拆分后的作者姓名(按姓氏、名字、后缀组织) |
latex |
large_string |
解析后编译的LaTeX源代码,所有源文件(.tex、.bib、.sty 等)合并为一个可读的Markdown风格树结构 |
许可与版权
- 许可协议:双许可证(详见
LICENSE文件) - 数据来源:镜像自arXiv,遵守arXiv使用条款
- 论文版权:各论文内容的版权和许可归其作者所有,对应
license列中的标识符。
任务与语言
- 任务类别:文本生成、特征提取
- 语言:英语
- 标签:科学(science)、arxiv、latex、学术(academic)
搜集汇总
数据集介绍
构建方式
该数据集通过直接从AWS S3存储桶中位于us-east-1区域的arXiv源文件进行数据摄取,免除了高昂的网络出口费用。数据摄取过程包括解压嵌套的.tar和.gz压缩包,解析LaTeX源代码,并与官方的元数据快照进行对齐,最终将处理后的结构化数据导出为Parquet格式文件。项目维护了一个中央XML清单文件用于追踪每个分区文件的大小、MD5校验和、处理时间戳以及论文ID范围,支持断点续传和增量同步,每月更新一次最新论文和修订版本。
特点
数据集以每一行代表一篇论文的表格形式呈现,提供了丰富的信息字段,包括论文标识符、提交者、作者、标题、摘要、分类、版本历史等元数据,以及核心的parsed LaTeX源代码。所有LaTeX源文件(如.tex、.bib、.sty)被整合为单一可读的Markdown风格树状结构,极大降低了学术文本处理的复杂性。数据规模达到百万级,覆盖arXiv全部LaTeX文档历史,支持文本生成和特征提取等自然语言处理任务。
使用方法
用户可直接从HuggingFace平台下载Parquet格式的数据文件,无需自行编写数据摄取管道或承担昂贵的网络传输费用。数据集支持通过Python生态中的Pandas或Dask等库加载,每条记录包含完整的LaTeX源码和结构化元数据,适用于大规模语料分析、科学论文的语言模型预训练、学术文本挖掘以及特征工程等研究方向。研究人员和开发者能够高效地查询和利用这些清理过的结构化数据。
背景与挑战
背景概述
在学术文本挖掘与自然语言处理领域,大规模、结构化且易于获取的科研文献语料库是推动研究进展的关键基础。arXiv作为物理学、数学、计算机科学等学科最重要的预印本数据库,其海量的LaTeX源码蕴含着丰富的数学公式、专业术语及排版结构,为科学知识抽取、机器翻译及学术写作辅助等任务提供了独特的研究资源。然而,由于网络传输成本高昂和原始数据格式复杂,研究者难以直接利用这一宝库。为此,该数据集由ScholarWeave团队于2024年创建,旨在解决上述瓶颈。通过将arXiv超过300万篇论文的LaTeX源码解析并整理为可直接查询的Parquet格式,该数据集大幅降低了获取成本,显著促进了计算语言学和科学信息学领域的研究进展。
当前挑战
该数据集所解决的领域核心挑战在于,大规模学术文献语料库的构建与应用长期受制于两个主要因素。其一,从数据获取角度看,arXiv的源文件存储在AWS S3中,且采用请求者付费模式,下载完整5TB语料需支付超过450美元的传输费用,这对于资源有限的学术机构构成显著障碍。其二,从数据处理角度看,原始数据封装在数百个嵌套的tar归档中,提取需复杂的本地解析流水线,计算负担沉重。构建过程本身也面临技术挑战,包括在us-east-1区域内实现免费的数据同步、高效地将LaTeX源码与元数据对齐,以及设计支持断点续传和增量更新的清单机制,以确保数据的一致性和可用性。
常用场景
经典使用场景
在自然语言处理与科学文献挖掘的交汇领域,arXiv LaTeX 源数据集为研究大规模学术文本的语义结构提供了得天独厚的实验平台。通过该数据集,研究者能够直接获取超过三百万篇学术论文的原始 LaTeX 源码,从而深入探索科学写作的排版逻辑、数学公式的语义编码以及多模态内容(如文本、公式、图表)的联合表示。经典的使用方式包括预训练科学领域语言模型、构建数学符号与自然语言的跨模态转换系统,以及开展细粒度的学术文档结构解析——例如从 LaTeX 章节标题中自动提取论文的组织框架。该数据集的出现使得从原始排版代码中学习科学知识成为可能,为理解学术交流的潜在规律开辟了新路径。
衍生相关工作
基于该数据集已经催生了一系列经典的研究工作,其中尤以科学文档的深度表示学习领域最为活跃。例如,有工作利用 LaTeX 源码中的结构化信息训练出能够感知文档逻辑树的分层编码器,显著提升了科学论文摘要的生成质量;另外的研究者通过解析大型数学公式的 TeX 标记,构建了跨语言符号推理数据集,用于训练数学表达式与自然语言之间的映射模型。还有团队借鉴该数据集的集合方式,开发出自动化 LaTeX 代码审阅工具,能够检测常见语法错误或排版不一致。这些衍生工作不仅验证了原始数据集的有效性,更推动了从文本分析向知识推理的范式转变,为构建全面理解科学文献的智能系统奠定了坚实基础。
数据集最近研究
最新研究方向
该数据集聚焦于大规模学术文献LaTeX源码的结构化解析与开放共享,旨在破解长期以来因网络传输成本高昂与数据预处理壁垒所引发的科研资源不平等问题。通过将海量学术论文的底层排版语言转化为可直接查询的Parquet格式,arXiv-LaTeX Source Dataset为自然语言处理、机器学习预训练以及学术知识图谱构建开辟了崭新的数据通途。近期研究前沿中,该资源正被广泛应用于科学论文生成模型(如基于LaTeX语义的文本生成)、跨领域文献知识推理、以及学术写作辅助工具的训练与优化。其整合的元数据与源码对齐机制,更是推动了科学语言理解与自动化排版分析迈向更高效、更精准的新阶段,对于促进全球学术资源的开放获取与深度挖掘具有里程碑意义。
以上内容由遇见数据集搜集并总结生成


