paper-review-pair-reason
收藏Hugging Face2025-04-05 更新2025-04-07 收录
下载链接:
https://huggingface.co/datasets/pawin205/paper-review-pair-reason
下载链接
链接失效反馈官方服务:
资源简介:
该数据集包含多个特征字段,如标题、摘要、评论、来源等。它还包括了会话内容及其角色,以及评论中的句子序列。此外,数据集还包含了针对不同评价标准的计数和分数,例如批评、例子、重要性和相关性等。数据集分为训练集和验证集,总共包含数十万条数据。
This dataset includes multiple feature fields such as title, abstract, comment, and source. It also covers conversation content and their corresponding roles, as well as the sentence sequences within the comments. Additionally, the dataset contains counts and scores for various evaluation criteria, including criticism, examples, importance, and relevance. The dataset is divided into training and validation sets, with a total of hundreds of thousands of data entries.
创建时间:
2025-04-05
搜集汇总
数据集介绍
构建方式
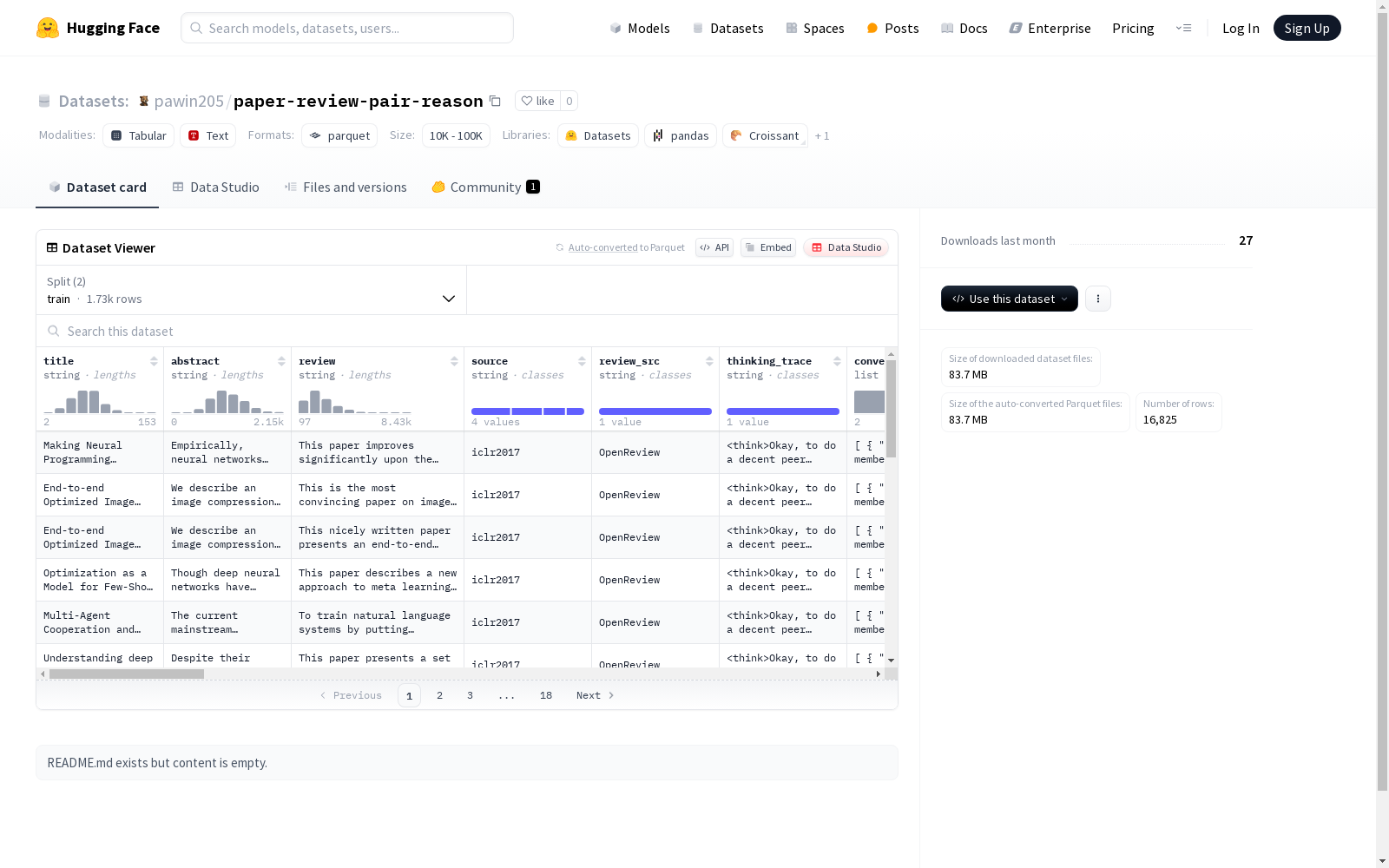
在学术论文评审领域,paper-review-pair-reason数据集的构建采用了系统化的方法,通过收集论文标题、摘要、审稿意见及审稿过程中的思维轨迹等多维度数据。数据集涵盖了1729条训练样本和15096条验证样本,每条记录均包含结构化审稿标准统计量,如批评、建议、重要性评估等九类量化指标,并通过reward_value等字段实现审稿质量的数值化评估。
特点
该数据集最显著的特征在于其精细的审稿要素解构能力,不仅包含原始审稿文本和对话记录,更通过criteria_count结构体实现审稿要素的量化统计。review_sentences字段完整保留了审稿意见的句子级结构,而thinking_trace字段则揭示了审稿人的决策逻辑,为研究学术评审认知过程提供了独特视角。各类has_*二元指标与标准化评分相结合,构建了多维度的审稿质量评估体系。
使用方法
研究者可通过加载train/val分割直接使用该数据集,其丰富的结构化字段支持多种分析维度。对于审稿过程研究,可聚焦conversations字段分析对话序列;若研究评审标准,criteria_count结构体提供可直接计算的统计量;reward_value等评分字段则适用于构建审稿质量预测模型。数据集的句子级审稿意见和思维轨迹记录特别适合自然语言处理与认知科学交叉研究。
背景与挑战
背景概述
paper-review-pair-reason数据集聚焦于学术论文与审稿意见之间的关联分析,由前沿研究机构在自然语言处理与学术出版交叉领域构建。该数据集通过结构化存储论文标题、摘要、审稿意见及思维轨迹等多元特征,旨在揭示审稿过程中的逻辑推理模式与评价标准分布。其创新性体现在对审稿意见的细粒度标注体系,涵盖批评、建议、方法论证等九大维度,为学术文本挖掘与智能审稿系统开发提供了重要基准。
当前挑战
该数据集面临的核心挑战在于审稿意见的多维度语义解析,需同步处理非结构化文本的意图识别与结构化指标的量化映射。构建过程中,细粒度标注体系导致标注一致性难以保障,不同审稿人的表述差异增加了语义归一化难度。同时,审稿意见与论文内容间的隐含逻辑关联,要求模型具备跨文本推理能力,这对现有自然语言处理技术提出了更高要求。数据规模与质量平衡也是关键挑战,需确保样本覆盖不同学科领域与审稿风格。
常用场景
经典使用场景
在学术论文评审领域,paper-review-pair-reason数据集为研究论文与审稿意见之间的关联性提供了丰富的分析素材。该数据集通过结构化存储论文标题、摘要、审稿意见及审稿过程中的思维轨迹,为研究者深入理解审稿行为模式与论文质量评估标准之间的内在联系奠定了数据基础。其多维度标注体系尤其适合探究不同审稿标准对论文评价的影响机制。
实际应用
在实际应用中,该数据集可支撑智能审稿辅助系统的开发,通过分析历史审稿数据中的thinking_trace字段,帮助新审稿人快速掌握评审要点。出版机构可利用criticism和suggestion_and_solution等字段构建论文修改建议自动生成系统。教育领域则可基于conversations字段开发学术写作指导工具,提升研究生的论文撰写能力。
衍生相关工作
基于该数据集的特征设计,已有研究开发出审稿意见预测模型,通过has_praise等二分类特征预测论文接收概率。部分工作利用review_sentences序列数据构建了审稿意见生成系统。还有学者结合thinking_trace字段开发了评审推理过程可视化工具,这些衍生研究显著提升了学术评审的透明度和可解释性。
以上内容由遇见数据集搜集并总结生成


