Omnidata
收藏arXiv2021-10-11 更新2024-06-21 收录
下载链接:
https://omnidata.vision
下载链接
链接失效反馈官方服务:
资源简介:
Omnidata数据集是由瑞士联邦理工学院和加州大学伯克利分校合作创建的,旨在从真实世界的3D扫描中生成多任务中层视觉数据集。该数据集包含约1450万张图像,涵盖多种视觉任务,如深度估计、表面法线估计和语义分割等。创建过程涉及使用Blender等工具对3D扫描数据进行参数化采样和渲染。Omnidata数据集的应用领域广泛,旨在解决计算机视觉中的多任务学习问题,提高模型在真实世界场景中的性能。
The Omnidata Dataset was co-created by ETH Zurich and the University of California, Berkeley, aiming to generate a multi-task mid-level vision dataset from real-world 3D scans. It contains approximately 14.5 million images covering a wide range of visual tasks such as depth estimation, surface normal estimation, semantic segmentation and more. The dataset creation process involves parametric sampling and rendering of 3D scan data using tools such as Blender. The Omnidata Dataset has broad application scenarios, and is designed to solve multi-task learning problems in computer vision and improve the performance of models in real-world scenarios.
提供机构:
瑞士联邦理工学院 (EPFL) 加州大学伯克利分校
创建时间:
2021-10-11
搜集汇总
数据集介绍
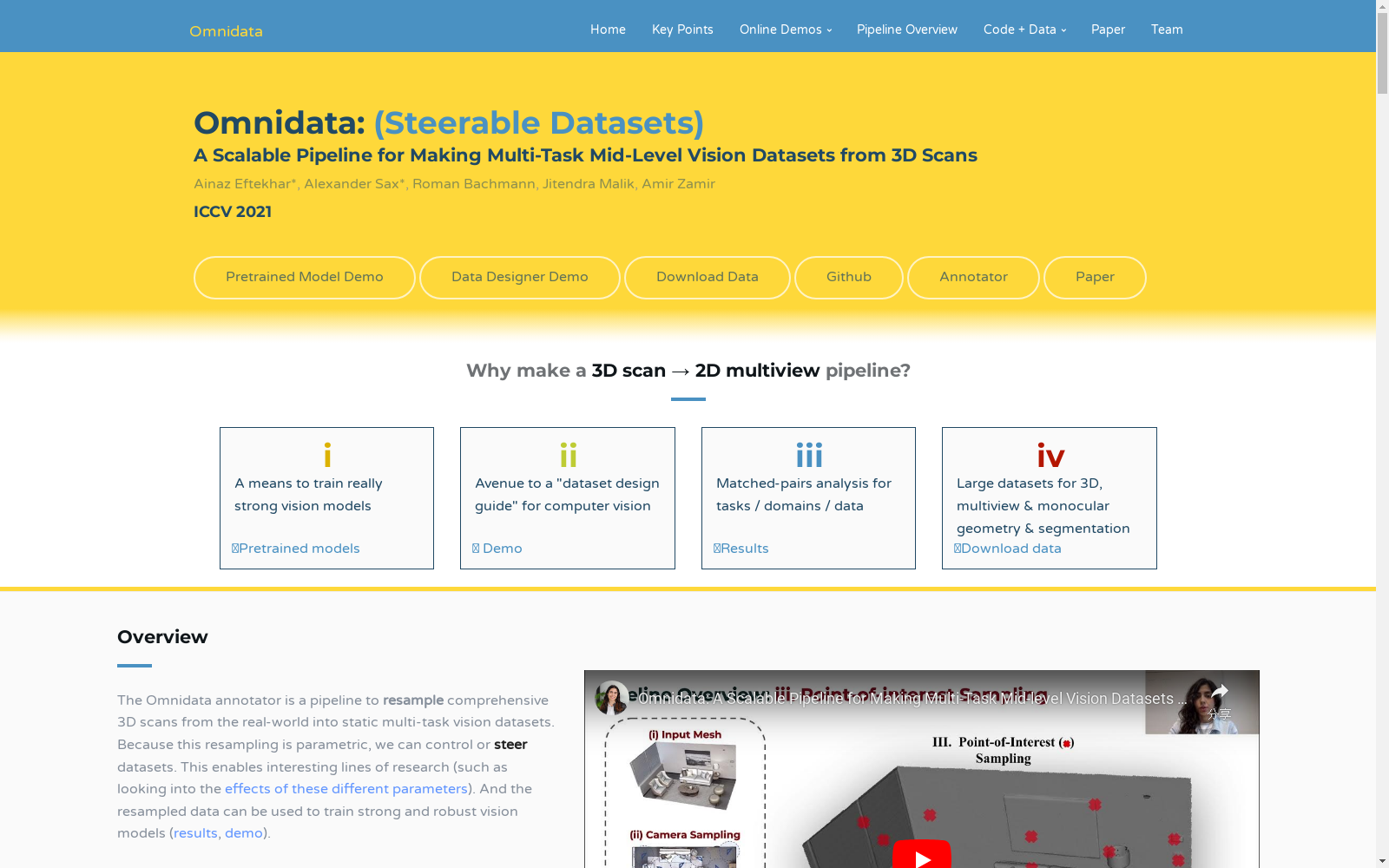
构建方式
Omnidata数据集通过一个可扩展的管道从现实世界的3D扫描中生成多任务的中级视觉数据集。该管道利用Blender等物理基础的3D渲染引擎,从输入的纹理网格、带有实际相机/传感器图像的网格或3D点云与对齐的RGB图像中生成多任务数据集。每个图像包含21种默认的中级视觉线索,如光流、曲率、重着色、2D和3D关键点、深度、语义分割等。该管道提供了对采样和生成过程的完全控制,确保了数据集的多样性和密集覆盖。
特点
Omnidata数据集的特点在于其多任务性和多样性。每个样本包含21种不同的中级视觉线索,涵盖了从几何到语义的广泛任务。数据集通过从多个3D扫描中生成,确保了场景和对象的多样性,适用于多种计算机视觉任务。此外,数据集的生成过程允许通过调整采样参数来“引导”数据集,强调特定信息,从而支持多种研究方向。
使用方法
Omnidata数据集适用于训练和评估多种计算机视觉任务的模型,如深度估计、表面法线估计、语义分割等。用户可以通过PyTorch数据加载器高效地加载生成的数据,并利用提供的预训练模型进行快速实验。数据集还支持通过Docker化的管道进行自定义数据生成,用户可以根据需要调整采样参数和生成设置,以满足特定的研究需求。
背景与挑战
背景概述
Omnidata数据集由瑞士联邦理工学院(EPFL)和加州大学伯克利分校的研究团队于近年推出,旨在通过从真实世界的3D扫描中生成多任务视觉数据集,填补3D扫描与静态视觉数据集之间的鸿沟。该数据集的核心研究问题是如何从3D扫描中高效生成包含多种视觉任务的中层视觉线索数据集,以支持计算机视觉模型的训练。Omnidata通过参数化采样和渲染技术,能够生成包含21种不同中层视觉线索的图像,涵盖深度估计、表面法线、语义分割等多种任务。其生成的数据集在多个视觉任务上达到了最先进的性能,尤其是在表面法线估计和深度估计任务上表现尤为突出,展示了其在推动计算机视觉研究中的重要价值。
当前挑战
Omnidata数据集的构建面临多重挑战。首先,从3D扫描中生成多任务数据集的过程复杂,涉及大量的计算资源和时间成本,尤其是在生成高质量的中层视觉线索时,需要精确的渲染和标注技术。其次,数据集的多样性和覆盖范围也是一个挑战,如何在有限的3D扫描数据中生成足够多样化的样本,以确保模型在不同场景下的泛化能力,是一个亟待解决的问题。此外,数据集的生成过程中还需要考虑如何减少人为偏差,确保生成的数据能够真实反映现实世界的复杂性。最后,如何有效地利用生成的数据集进行多任务学习,尤其是在不同任务之间的关联性和相互影响方面,仍需进一步研究和探索。
常用场景
经典使用场景
Omnidata数据集的经典使用场景在于其能够从3D扫描数据中生成多任务的中层视觉数据集,涵盖了从深度估计、表面法线估计到语义分割等多种任务。通过该数据集,研究者可以训练模型在多个视觉任务上达到最先进的性能,尤其是在表面法线估计和深度估计方面,模型表现尤为突出。
实际应用
Omnidata数据集在实际应用中具有广泛的前景,尤其是在机器人导航、增强现实和自动驾驶等领域。通过该数据集训练的模型可以用于室内场景的深度估计、物体识别和语义分割,从而为这些应用提供更精确的环境感知能力。
衍生相关工作
Omnidata数据集的发布催生了一系列相关研究工作,特别是在多任务学习和3D视觉领域。例如,基于Omnidata的深度估计模型在多个基准测试中表现优异,推动了深度估计技术的发展。此外,该数据集还为研究者提供了新的视角,探索如何通过多任务学习提升模型的泛化能力和鲁棒性。
以上内容由遇见数据集搜集并总结生成


