llamafactory/alpaca_en
收藏Hugging Face2024-06-07 更新2024-06-12 收录
下载链接:
https://hf-mirror.com/datasets/llamafactory/alpaca_en
下载链接
链接失效反馈官方服务:
资源简介:
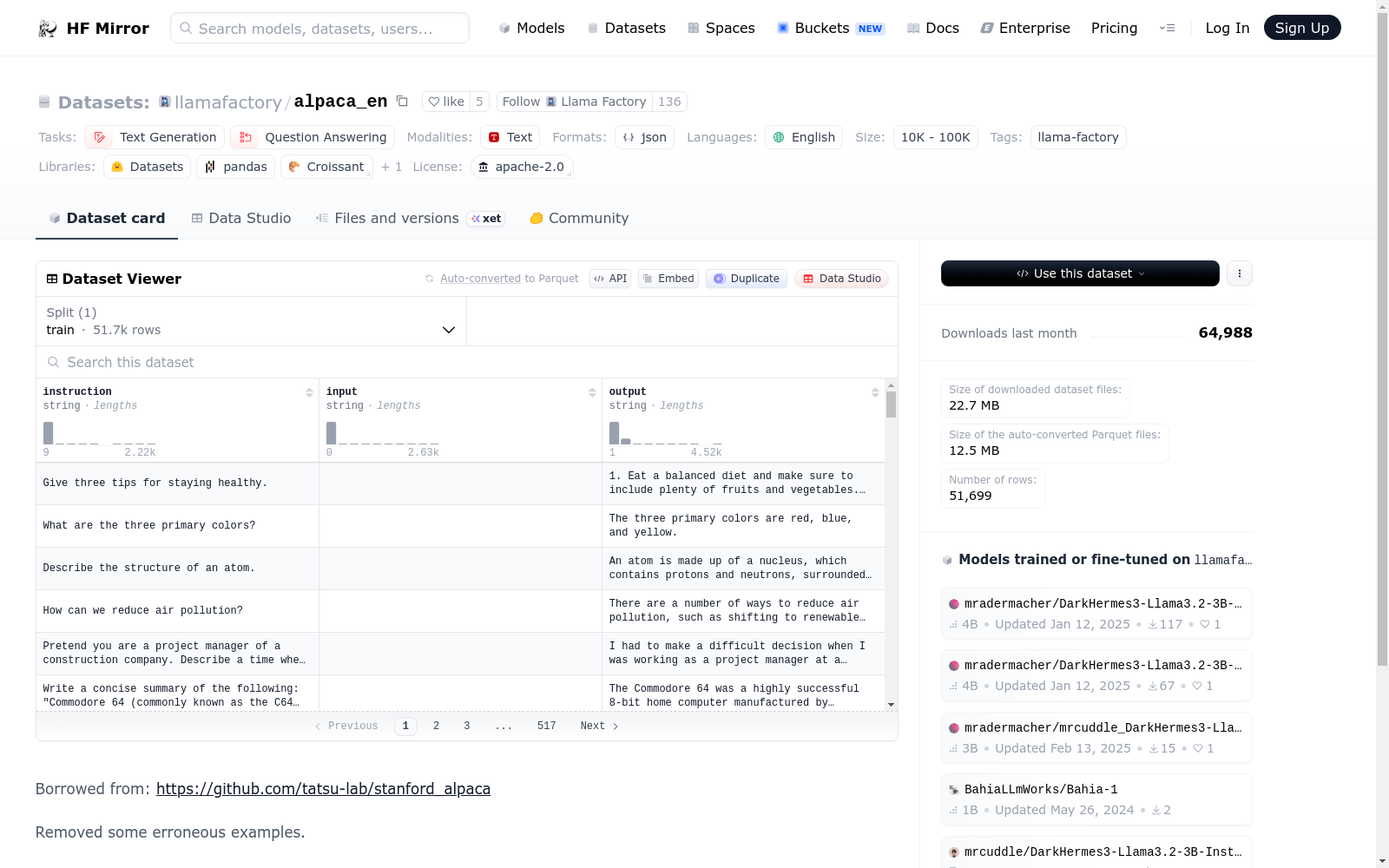
该数据集包含指令、输入和输出三个特征,适用于文本生成和问答任务。数据集语言为英语,规模在10K到100K之间。数据集来源于https://github.com/tatsu-lab/stanford_alpaca,并移除了部分错误的示例。可以在LLaMA Factory中使用,指定`dataset: alpaca_en`即可。
该数据集包含指令、输入和输出三个特征,适用于文本生成和问答任务。数据集语言为英语,规模在10K到100K之间。数据集来源于https://github.com/tatsu-lab/stanford_alpaca,并移除了部分错误的示例。可以在LLaMA Factory中使用,指定`dataset: alpaca_en`即可。
提供机构:
llamafactory
原始信息汇总
数据集概述
数据集特征
- instruction: 数据类型为字符串。
- input: 数据类型为字符串。
- output: 数据类型为字符串。
许可
- 许可证: Apache-2.0
任务类别
- 文本生成
- 问答
语言
- 英语
标签
- llama-factory
大小类别
- 10K<n<100K
搜集汇总
数据集介绍
背景与挑战
背景概述
The 'llamafactory/alpaca_en' dataset is an English-language collection of 51.7k rows of text data formatted in JSON, aimed at text generation and question answering tasks. It features diverse content from instructional examples to Q&A pairs, licensed under Apache-2.0, and is compatible with popular data processing libraries.
以上内容由遇见数据集搜集并总结生成


