base_cpi
收藏Hugging Face2025-05-31 更新2025-06-01 收录
下载链接:
https://huggingface.co/datasets/domq/base_cpi
下载链接
链接失效反馈官方服务:
资源简介:
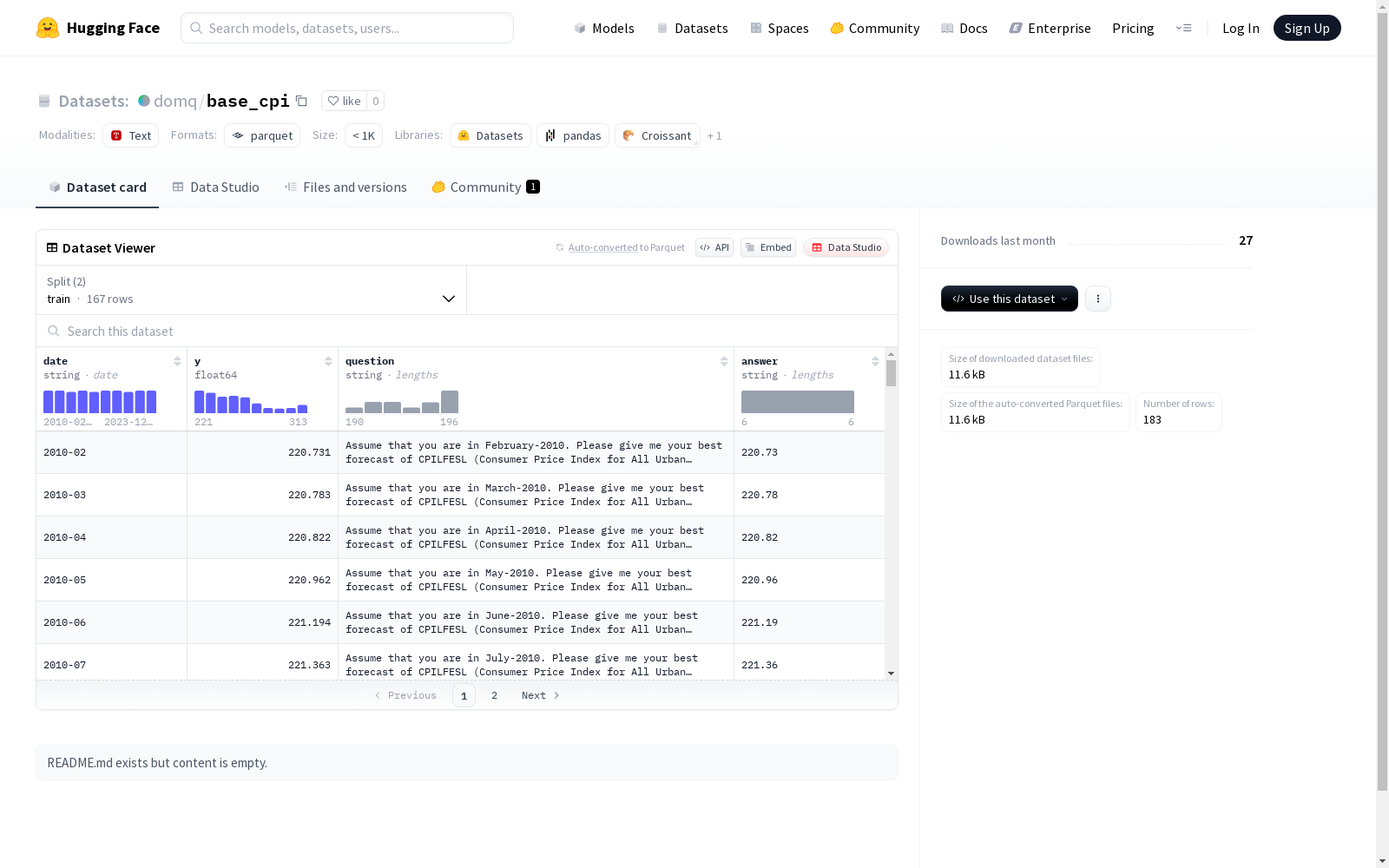
该数据集包含了日期、答案、问题和数值四个字段的信息。数据集分为训练集和测试集,其中训练集包含167个示例,测试集包含16个示例。数据集适用于机器学习模型的训练和评估。
创建时间:
2025-05-31
原始信息汇总
数据集概述
基本信息
- 数据集名称: base_cpi
- 存储位置: https://huggingface.co/datasets/domq/base_cpi
- 下载大小: 11,611 bytes
- 数据集大小: 41,388 bytes
数据特征
- 字段说明:
date: 字符串类型,表示日期y: 浮点数类型question: 字符串类型,表示问题answer: 字符串类型,表示答案
数据划分
- 训练集 (train):
- 样本数量: 167
- 数据大小: 37,769 bytes
- 测试集 (test):
- 样本数量: 16
- 数据大小: 3,619 bytes
配置文件
- 默认配置 (default):
- 训练集路径:
data/train-* - 测试集路径:
data/test-*
- 训练集路径:
搜集汇总
数据集介绍
构建方式
base_cpi数据集聚焦于经济指标分析领域,通过系统化采集时间序列数据构建而成。其核心结构包含日期标识、数值指标、问题描述和对应解答四个维度,训练集与测试集按9:1比例划分,确保了模型开发与验证的科学性。数据采集过程严格遵循时序连续性原则,167组训练样本和16组测试样本均经过标准化处理,数值型字段采用float64格式以保留经济数据的精确度。
特点
该数据集以经济预测场景中的消费者价格指数为核心,呈现出鲜明的多模态特征。文本字段采用自然语言形式记录经济指标相关的问答对,与数值型时间序列形成互补。数据时间跨度经过精心设计,既包含足够的历史深度又保持时效性,37.7KB的紧凑体积使其兼具轻量化与信息密度优势。特征字段间存在显着的逻辑关联,为联合分析文本描述与数值趋势提供了理想实验环境。
使用方法
使用base_cpi数据集时,建议采用时序交叉验证策略以充分利用有限样本。训练集适用于构建经济指标预测模型或问答系统,测试集则用于评估模型泛化能力。对于数值预测任务,可重点分析date与y字段的映射关系;文本分析任务则可挖掘question-answer对的语义模式。加载时注意保持原始数据分割比例,建议将字符串日期转换为datetime对象以便进行时间序列分析。
背景与挑战
背景概述
base_cpi数据集聚焦于经济指标预测与分析领域,其核心在于通过结构化数据探讨消费者价格指数(CPI)的变动趋势及其影响因素。该数据集由匿名研究团队构建,收录了包含时间序列数据、量化指标及问答对在内的多维信息,旨在为宏观经济预测和货币政策研究提供数据支撑。其独特之处在于将传统经济指标与自然语言处理相结合,通过问答形式揭示数据背后的经济逻辑,为跨学科研究开辟了新路径。
当前挑战
该数据集面临的核心挑战体现在两个维度:在领域问题层面,CPI预测需解决宏观经济变量的高噪声性和非线性特征,传统计量模型难以捕捉突发经济事件对指标的扰动;在构建过程中,如何平衡问答对的专业深度与语言普适性成为难点,经济术语的歧义性可能导致模型理解偏差。此外,有限样本量对时序预测任务的泛化能力构成制约,需通过数据增强或迁移学习弥补。
常用场景
经典使用场景
在宏观经济研究领域,base_cpi数据集因其包含的时间序列数据和问答对,常被用于消费者价格指数(CPI)的预测模型构建。研究者通过分析历史CPI数据与对应的经济问题及解答,能够深入理解CPI波动的内在规律,为经济预测和政策制定提供数据支持。
实际应用
在实际应用中,base_cpi数据集被广泛用于政府机构和金融机构的经济分析与决策支持。例如,中央银行可以利用该数据集评估通胀趋势,制定更精准的货币政策;投资机构则可通过分析CPI数据优化资产配置策略,降低经济波动带来的风险。
衍生相关工作
围绕base_cpi数据集,学术界已衍生出多项经典研究,包括基于时间序列的CPI预测模型、经济问答系统的自动生成技术等。这些工作不仅推动了宏观经济研究的发展,也为自然语言处理与经济学的交叉研究提供了新的思路和方法。
以上内容由遇见数据集搜集并总结生成


