ncats/EpiSet4NER-v2
收藏Hugging Face2022-09-20 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/ncats/EpiSet4NER-v2
下载链接
链接失效反馈官方服务:
资源简介:
EpiSet4NER-v2是一个用于流行病学实体识别的黄金标准数据集,包括位置、流行病学类型(如“患病率”、“年发病率”、“估计发生率”)和流行病学率(如“每100万活产中的1.7”、“2.1:1.000.000”、“五百万分之一”、“0.03%”)的识别。该数据集由美国国家转化科学推进中心(NCATS)的遗传和罕见疾病信息中心(GARD)创建,采用spaCy NER和基于规则的方法进行程序化标注,并由生物医学研究人员(包括GARD专家)手动验证。数据集用于训练基于BioBERT的NER模型EpiExtract4GARD-v2。数据集包含620篇罕见疾病摘要,数据字段包括句子编号、词汇列表和NER标签列表。数据集分为训练集、验证集和测试集,分别包含456、114和50篇摘要。数据集创建的目的是训练ML/DL模型,以自动化罕见疾病流行病学信息的整理过程,对患者、家庭、研究人员、资助者和政策制定者具有重要意义。
EpiSet4NER-v2 is a gold-standard dataset for epidemiological entity recognition, covering the identification of locations, epidemiological types (e.g., "prevalence", "annual incidence", "estimated incidence") and epidemiological rates (e.g., "1.7 per 1 million live births", "2.1 per 1,000,000", "one in five million", "0.03%"). This dataset was developed by the Genetic and Rare Diseases Information Center (GARD) of the U.S. National Center for Advancing Translational Sciences (NCATS). It was programmatically annotated using spaCy NER and rule-based approaches, and manually validated by biomedical researchers including GARD experts. The dataset is utilized to train the BioBERT-based NER model EpiExtract4GARD-v2. It contains 620 rare disease abstracts, with data fields including sentence indices, vocabulary lists, and NER label lists. The dataset is split into training, validation, and test sets, which consist of 456, 114, and 50 abstracts respectively. The dataset was created to train machine learning (ML)/deep learning (DL) models to automate the curation of rare disease epidemiological information, which holds important value for patients, families, researchers, funders, and policy-makers.
提供机构:
ncats
原始信息汇总
数据集概述
名称: EpiSet4NER-v2
语言: 英语 (en)
许可证: 其他
多语言性: 单语
规模: 100K<n<1M
来源: 原始数据集
标签: 流行病学, 罕见疾病, 命名实体识别, NER, NIH
任务类别: 令牌分类
任务ID: 命名实体识别
数据集描述
摘要: EpiSet4NER-v2 是一个用于流行病学实体识别的黄金标准数据集,由遗传和罕见疾病信息中心(GARD)创建,用于识别地点、流行病学类型和流行病学率。该数据集通过 spaCy NER 和基于规则的方法程序化标记,并由生物医学研究人员手动验证。
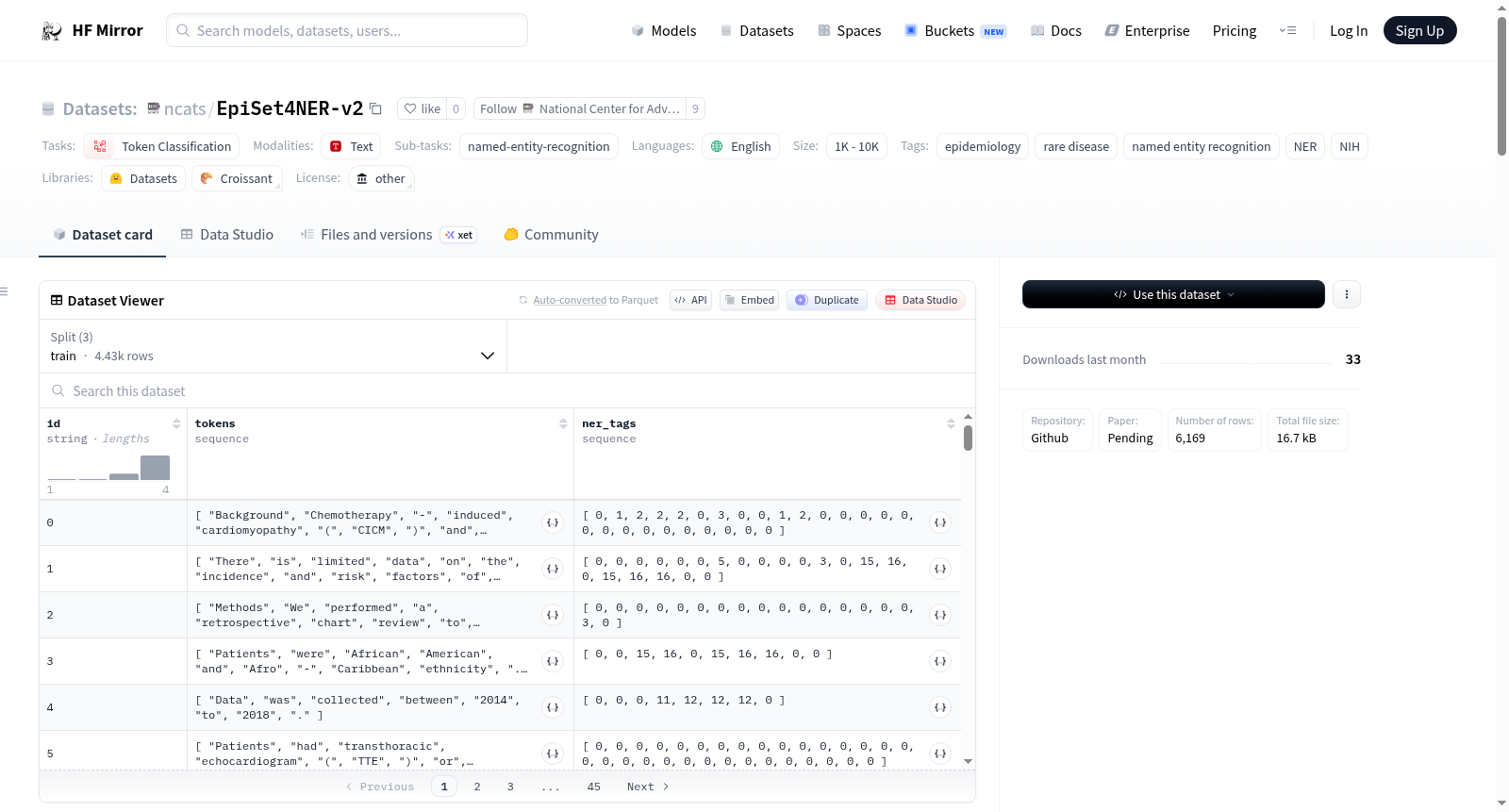
数据字段:
id: 字符串,表示句子编号。tokens: 字符串列表。ner_tags: 分类标签列表,可能值包括O(0),B-LOC(1),I-LOC(2),B-EPI(3),I-EPI(4),B-STAT(5),I-STAT(6)。
数据分割:
| 名称 | 训练 | 验证 | 测试 |
|---|---|---|---|
| EpiSet 摘要数量 | 456 | 114 | 50 |
| EpiSet 令牌数量 | 117888 | 31262 | 13910 |
数据集创建
来源数据: 620 篇罕见疾病摘要,被 LSTM RNN 罕见疾病流行病学分类器分类为流行病学。
注释过程: 程序化标记,由 NCATS 研究人员执行,测试集在创建后手动更正。
个人和敏感信息: 无,数据来源于 PubMed 的公开摘要。
使用数据集的考虑
社会影响: 帮助 25-30 百万美国罕见疾病患者,对 Orphanet 或 CDC 的研究人员/馆员也有用。
偏见和限制:
- 源文件中的罕见疾病同义词名称错误可能导致无关摘要被包含在训练、验证和测试集中。
- 通过 EBI API 收集的摘要可能存在偏见。
- LSTM RNN 流行病学分类器用于筛选 7699 篇罕见疾病摘要,可能存在假阳性和假阴性。
- 程序化标记的精确度较低,可能是 BioBERT 模型训练的最大限制。
搜集汇总
数据集介绍
构建方式
在流行病学与罕见病研究领域,构建高质量标注数据集对于信息自动化提取至关重要。EpiSet4NER-v2的构建采用了弱监督与专家验证相结合的方法,首先从PubMed数据库中检索约25,000篇罕见病相关摘要,通过LSTM RNN流行病学分类器筛选出620篇具有流行病学特征的文本。随后利用spaCy命名实体识别模型与规则方法进行程序化标注,识别位置、流行病学类型及比率三类实体。最终,由生物医学研究者及罕见病专家对测试集进行人工校正,确保标注的准确性与可靠性,形成规模介于10万至100万标记之间的高质量数据集。
特点
该数据集聚焦于罕见病流行病学实体识别,涵盖位置、流行病学类型与比率三类实体,标注体系细致全面。其独特之处在于融合了程序化标注与专家验证,既通过自动化方法提升构建效率,又借助人工校正保障数据质量。数据规模适中,包含训练、验证与测试三个标准划分,适用于多类型标记分类任务。此外,数据集源自权威生物医学文献,语言为英文,具有高度的领域专业性与实用性,为流行病学信息提取模型提供了可靠的训练与评估基础。
使用方法
EpiSet4NER-v2主要用于命名实体识别任务的模型训练与评估,特别适用于生物医学文本分析领域。使用者可通过HuggingFace平台直接加载数据集,利用其提供的标记序列与实体标签进行模型微调,例如基于BioBERT的预训练模型。数据已划分为训练集、验证集与测试集,便于进行模型训练、调参与性能测试。在应用时需注意程序化标注存在的局限性,建议结合领域知识进行结果验证,以充分发挥数据集在罕见病流行病学信息自动化提取中的价值。
背景与挑战
背景概述
在生物医学信息学领域,流行病学数据的自动化抽取对于罕见病研究具有关键意义。EpiSet4NER-v2数据集由美国国立卫生研究院下属的国家转化科学促进中心与遗传与罕见病信息中心联合构建,旨在通过命名实体识别技术,从科学文献中精准定位流行病学实体,包括地理位置、流行病学类型及发病率数据。该数据集的创建融合了程序化标注与专家人工验证的弱监督方法,有效支撑了基于BioBERT的专用模型训练,为罕见病流行病学信息的系统化整理与利用提供了高质量基准资源。
当前挑战
该数据集致力于解决罕见病流行病学信息抽取中的命名实体识别挑战,其核心难点在于准确识别并分类文本中复杂的流行病学统计表述,如发病率、患病率等数值与单位组合。在构建过程中,面临多重挑战:源数据通过API获取时可能存在偏差;前期使用的LSTM分类器可能导致假阳性与假阴性样本混入;程序化标注的精度有限,尤其在流行病学比率的识别上表现较弱;且标注任务高度依赖领域专家知识,对非专业标注者构成显著困难,这些因素共同影响了数据集的整体质量与模型训练的可靠性。
常用场景
经典使用场景
在流行病学与罕见病研究领域,EpiSet4NER-v2数据集为命名实体识别任务提供了关键支持。该数据集聚焦于从生物医学文献中精准提取地理位置、流行病学类型及发病率等实体信息,其经典应用场景在于训练和评估深度学习模型,如基于BioBERT的EpiExtract4GARD-v2模型,以自动化处理罕见病流行病学数据的标注与提取。通过结合程序化标注与专家验证,该数据集有效提升了实体识别的准确性与效率,为后续信息整合与分析奠定了坚实基础。
解决学术问题
该数据集致力于解决生物医学自然语言处理中的核心挑战,即从非结构化文本中自动识别流行病学相关实体。传统方法依赖人工标注,耗时且易受主观影响,而EpiSet4NER-v2通过弱监督学习与规则结合的方式,构建了高质量的标注语料,显著缓解了标注资源匮乏的问题。其意义在于推动了罕见病流行病学数据的标准化提取,为疾病负担评估、政策制定及科研资助提供了可靠的数据支撑,促进了跨学科研究的融合与发展。
衍生相关工作
基于EpiSet4NER-v2数据集,衍生了一系列经典研究工作。其中最突出的是EpiExtract4GARD-v2模型,该模型通过微调BioBERT架构,实现了对流行病学实体的高效识别。相关研究进一步探索了结合规则引擎与深度学习的方法,以提升数值型实体(如发病率)的提取精度。此外,该数据集也激发了跨语言与跨领域实体识别模型的开发,为生物医学文本挖掘提供了新的范式,推动了罕见病流行病学知识图谱的构建与应用。
以上内容由遇见数据集搜集并总结生成


