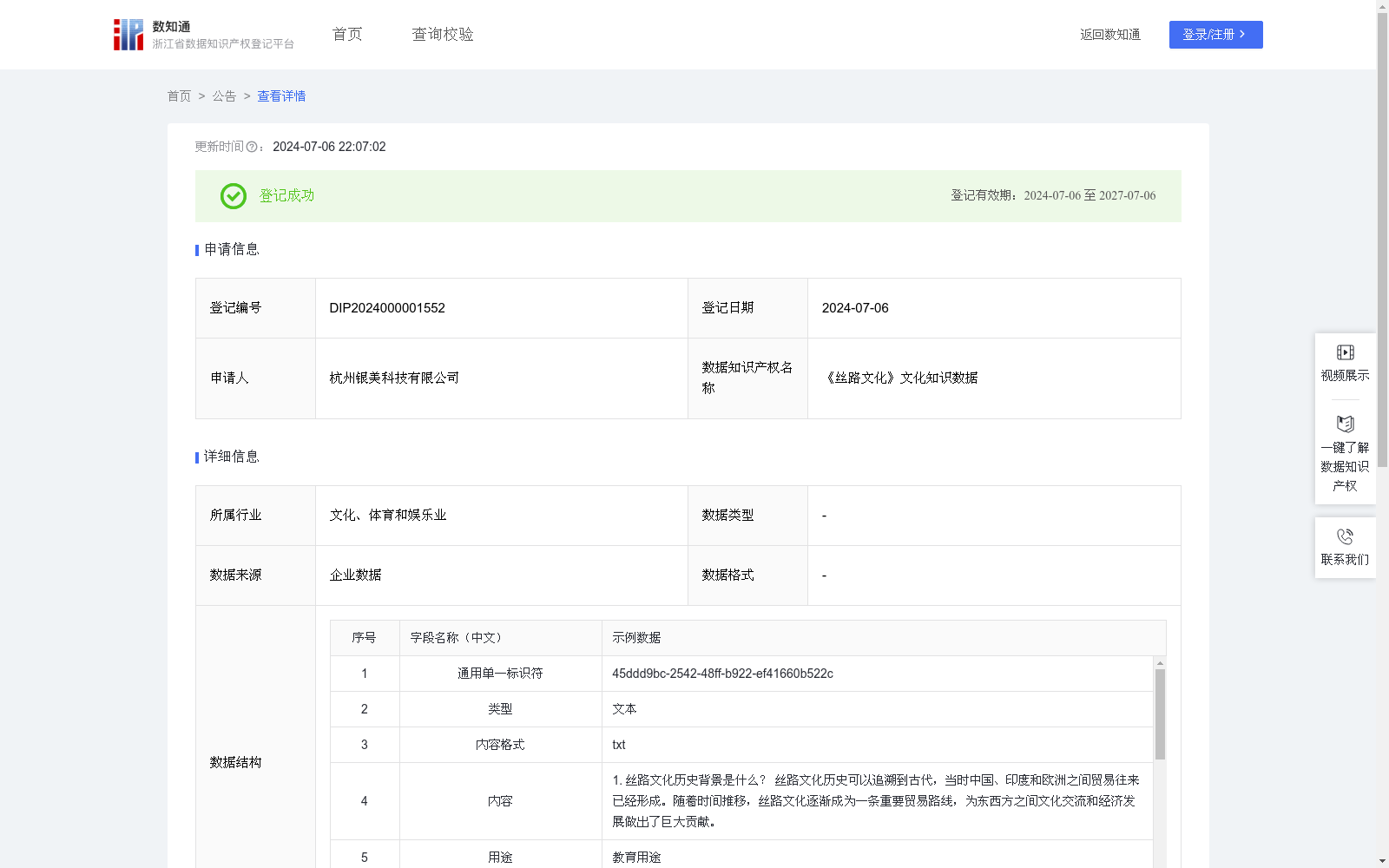
《丝路文化》文化知识数据
收藏浙江省数据知识产权登记平台2024-07-06 更新2024-07-09 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/36644
下载链接
链接失效反馈官方服务:
资源简介:
1.本数据可用于《丝路文化》相关教育创新课程制作参考,例如作为教师教研、教案编写、学生自主欣赏与拓展阅读、PBL课程组织、学生自主创新的素材资料。
2.本数据还可用于文化领域人工智能产品的模型训练,例如文化课程开发辅助决策系统、文化相关的大语言模型等产品的模型训练,经过本数据训练的模型能提供更加专业的建议结果。依据国家文化相关信息公开政策,以及浙江省教育厅与浙江省文旅厅文化数据教育方向应用公约,从公开出版物、论文文献、有发展教育意向的博物馆和研究机构等合法渠道获取《丝路文化》相关古籍、数据库、研究资料等原始数据后,使用自然语言处理(NLP)从大量文本数据中自动识别、抽取和整合有用信息。
1.选择带标点符号的《丝路文化》相关文化信息文本在预训练模型上进行预训练以及微调,获得预测文化信息标点符号模型。
2.将文本输入预测文化信息标点符号模型中,得到含有标点符号的文本。
3.对含有标点符号的文本进行词向量化预处理,得到词向量文本。
4.通过实体识别模型对词向量文本进行实体抽取和分类,并标注需要关系抽取的实体为主体,得到标记文本。
5.对标记文本进行词向量+位置向量的预处理,得到词向量+位置向量文本。
6.通过关系抽取模型对词向量+位置向量文本进行关系抽取,获得实体-关系-实体结构的三元组关系数据集。
7.根据三元组关系数据集,生成《丝路文化》文化信息知识。
以上算法规则初步得到了结构化的《丝路文化》文化知识数据,经文化领域专家团队审核、校验及认证,形成高质量可用的《丝路文化》文化知识数据。
1. This dataset can be used as a reference for developing educational innovation courses related to "Silk Road Culture", serving as teaching materials for teacher teaching research, lesson plan development, students' independent appreciation and extended reading, PBL (Project-Based Learning) course organization, and students' independent innovation practices.
2. This dataset can also be applied to model training for AI products in the cultural domain, such as auxiliary decision-making systems for cultural course development and culturally oriented Large Language Models (LLMs). Models trained with this dataset can deliver more professional and targeted advisory results. In compliance with national policies on the disclosure of cultural information and the Application Convention on Educational Application of Cultural Data jointly formulated by the Department of Education of Zhejiang Province and the Department of Culture and Tourism of Zhejiang Province, original data including ancient books, databases and research materials related to "Silk Road Culture" are collected from legal channels such as public publications, academic papers, museums and research institutions with educational development intentions. Then, useful information is automatically identified, extracted and integrated from large-scale text data via Natural Language Processing (NLP).
1. Select text related to "Silk Road Culture" with complete punctuation marks for pre-training and fine-tuning on a pre-trained language model, so as to obtain a cultural information punctuation prediction model.
2. Input the unprocessed text into the cultural information punctuation prediction model to generate text with standard punctuation marks.
3. Conduct word vectorization preprocessing on the punctuated text to obtain word-vectorized text.
4. Perform entity extraction and classification on the word-vectorized text using an entity recognition model, and label the entities that require relation extraction as main subjects to obtain labeled text.
5. Carry out preprocessing combining word vectors and position vectors on the labeled text to acquire text integrated with both word vectors and position vectors.
6. Utilize a relation extraction model to perform relation extraction on the text with word and position vectors, thus obtaining a triple relation dataset in the entity-relation-entity structure.
7. Generate structured cultural knowledge about "Silk Road Culture" based on the obtained triple relation dataset.
The above algorithmic workflow initially yields structured cultural knowledge data for "Silk Road Culture". After being reviewed, verified and certified by a panel of cultural domain experts, the data is finalized as a high-quality and readily usable "Silk Road Culture" knowledge dataset.
提供机构:
杭州银美科技有限公司
创建时间:
2024-05-31
搜集汇总
数据集介绍
特点
《丝路文化》文化知识数据集由杭州银美科技有限公司提供,包含637条记录,每月更新2-4次。数据主要用于教育领域,如课程制作和AI模型训练,采用NLP技术进行加工,形成结构化的文化知识数据。
以上内容由遇见数据集搜集并总结生成


