MultiOCR-QA
收藏github2025-03-03 更新2025-02-21 收录
下载链接:
https://github.com/DataScienceUIBK/MultiOCR-QA
下载链接
链接失效反馈官方服务:
资源简介:
一个多语言问答数据集,设计用于评估OCR错误对跨英语、法语和德语的问答系统的影响。该数据集来源于几个世纪的古老文件,为现实世界应用中OCR引起的挑战提供了独特的评估。
A multilingual question answering (QA) dataset designed to evaluate the impact of OCR errors on cross-lingual question answering systems covering English, French and German. Derived from centuries-old historical documents, this dataset provides a unique assessment of the challenges posed by OCR errors in real-world applications.
创建时间:
2025-02-17
原始信息汇总
MultiOCR-QA 数据集概述
数据集简介
- 数据集名称:MultiOCR-QA
- 数据集用途:评估OCR错误对跨英语、法语和德语问答系统的影响
- 数据集特点:基于数百年历史文档,提供OCR误差在现实世界应用中的挑战评估
数据集统计
| 语言 | 英语 | 法语 | 德语 |
|---|---|---|---|
| QA对数量 | 10,875 | 10,004 | 39,200 |
| 段落数量 | 6,525 | 1,670 | 9,075 |
| 平均段落长度 | 219.09 | 297.53 | 212.86 |
| 平均问题长度 | 10.98 | 8.73 | 8.08 |
| 平均答案长度 | 2.05 | 3.12 | 5.63 |
| 每段问题数量 | 1.67 | 5.99 | 4.32 |
数据结构
json { "document_id": "", "rawOCR_text": "", "correctedOCR_text": "", "QA_pairs": [ { "q_id": "", "question": "", "answer": "" } ] }
数据下载
许可
- 许可证:MIT License
- 许可详情:查看LICENSE文件
引用
- 论文引用:请根据格式引用我们的论文
致谢
- 感谢贡献者和因斯布鲁克大学对该项目的支持。
搜集汇总
数据集介绍
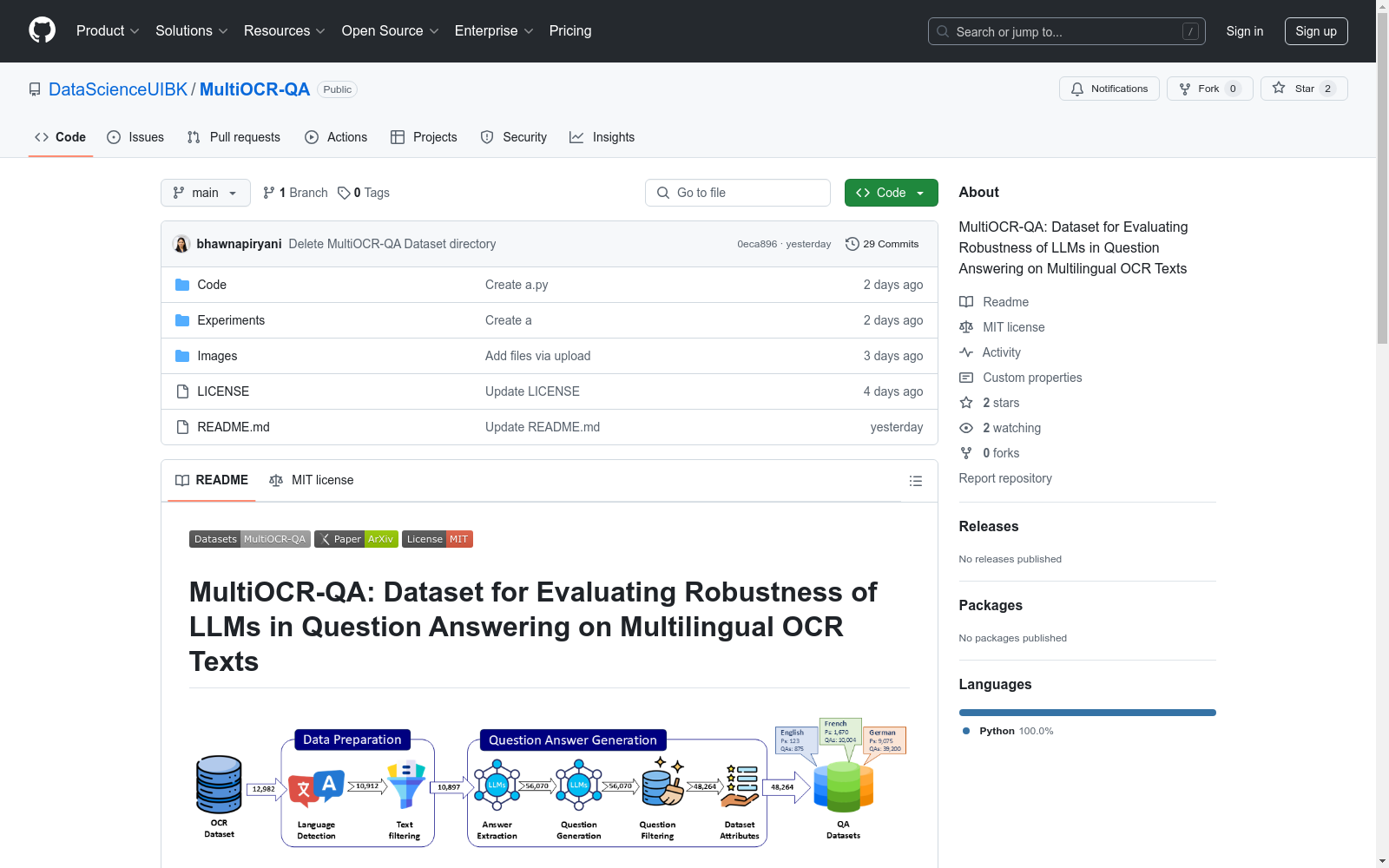
构建方式
MultiOCR-QA数据集的构建旨在评估OCR错误对跨英语、法语和德语的问答系统的影响。该数据集源于数百年历史的文献,通过这些文献,研究者们模拟了OCR技术在实际应用中可能遇到的挑战,从而构建了一个包含原始OCR文本、校正后的OCR文本以及对应的问答对的结构化数据集。
特点
该数据集具有多样化的特点,它包含了三种语言的文本,提供了10,875个英语问答对、10,004个法语问答对以及39,200个德语问答对。数据集的文本来源古老,能够反映OCR技术在处理历史悠久文献时的误差情况,这对于评估大型语言模型在处理真实世界文本中的鲁棒性具有重要意义。
使用方法
用户可以通过Hugging Face的数据集库下载该数据集的不同语言版本。数据集以JSON格式组织,每个文档包含文档ID、原始OCR文本、校正后的OCR文本以及一系列的问答对。用户可以直接使用这些数据来训练或评估问答系统的性能,特别是在处理OCR文本的准确性方面。
背景与挑战
背景概述
MultiOCR-QA数据集,创建于近期,由Bhawna等研究人员开发,旨在评估光学字符识别(OCR)错误对跨英语、法语和德语的多语言问答(QA)系统的影响。该数据集源于数个世纪之前的文献,为OCR引入的实际应用挑战提供了一个独特的评估平台,对于自然语言处理(NLP)领域中的OCR后处理及问答系统鲁棒性的研究具有重要的参考价值。
当前挑战
该数据集面临的挑战主要在于:1) OCR错误对QA系统性能的影响评估,这要求系统不仅能够准确理解正常文本,还能够处理由于OCR错误导致的异常文本;2) 数据集构建过程中,如何从古老文献中提取并准确地标注高质量的QA对,同时保持不同语言之间的平衡和一致性。这些挑战对于提升多语言环境中问答系统的鲁棒性和准确性具有重要意义。
常用场景
经典使用场景
针对多语言光学字符识别(OCR)文本中的问答系统鲁棒性评估,MultiOCR-QA数据集提供了10,875个英文、10,004个法文以及39,200个德文问答对。该数据集从具有数百年历史的文献中提取,旨在模拟真实应用场景中OCR错误对问答系统性能的影响,为研究人员提供了一种独特的评价手段。
衍生相关工作
基于MultiOCR-QA数据集,研究者们已经开展了一系列相关工作,如改进OCR识别算法、开发更鲁棒的QA系统,以及探索多语言文本处理的新技术。这些工作为信息检索、自然语言处理和文献数字化等领域提供了新的研究方向和工具。
数据集最近研究
最新研究方向
在自然语言处理领域,特别是在多语言问答系统的研究中,评估系统对光学字符识别(OCR)错误的鲁棒性至关重要。MultiOCR-QA数据集的构建,旨在对英语、法语和德语等多语言OCR文本的问答系统进行影响评估。近期研究利用此数据集,深入探讨了OCR误差对QA系统性能的影响,特别是在处理历史文献这类具有挑战性的实际应用场景中。该数据集不仅为研究者提供了丰富的测试案例,也推动了对于提升LLM(大型语言模型)鲁棒性的技术方法的探索,具有显著的研究价值和实践意义。
以上内容由遇见数据集搜集并总结生成


