FinLang/investopedia-embedding-dataset
收藏Hugging Face2024-05-06 更新2024-06-15 收录
下载链接:
https://hf-mirror.com/datasets/FinLang/investopedia-embedding-dataset
下载链接
链接失效反馈官方服务:
资源简介:
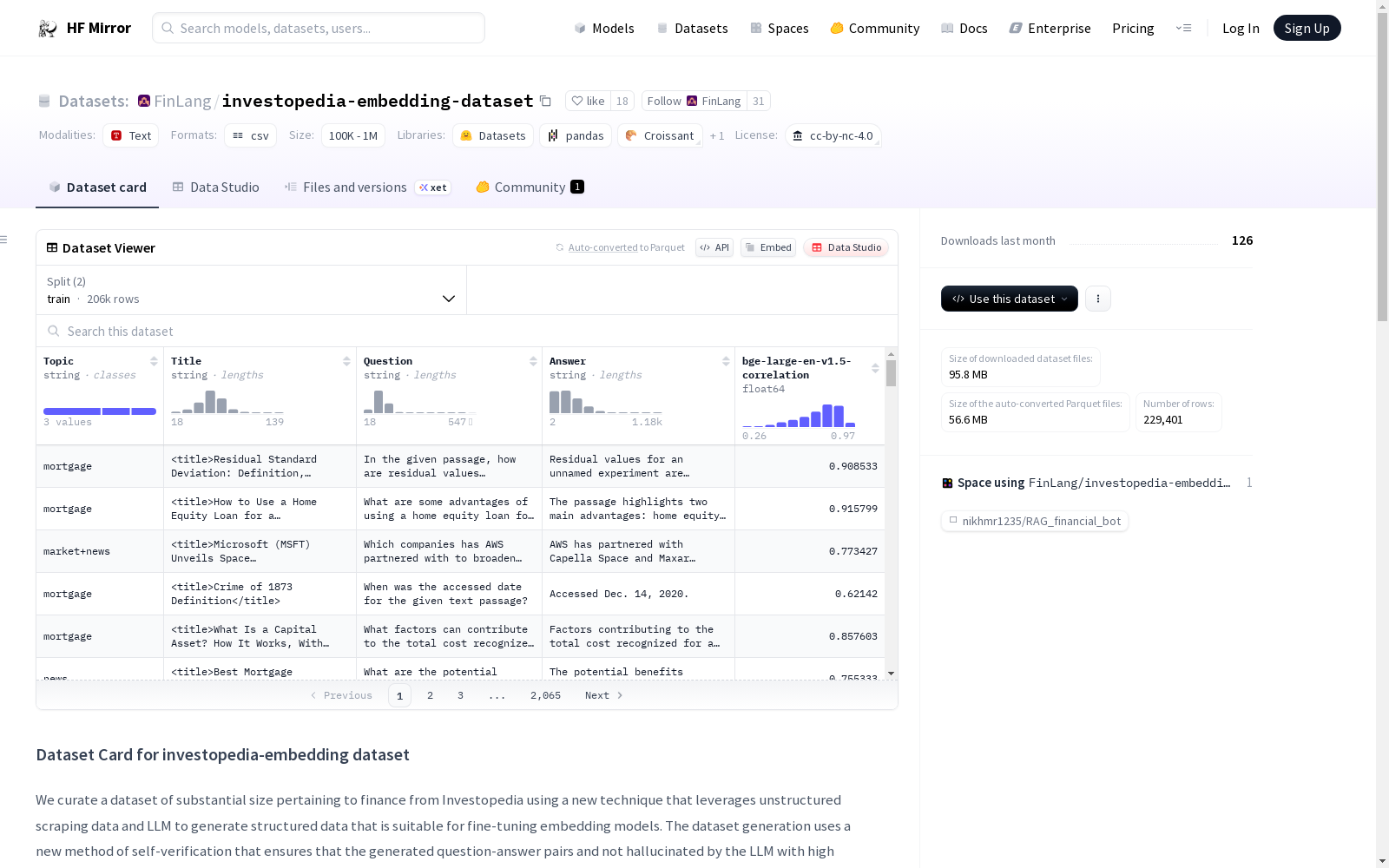
该数据集是从Investopedia网站收集的金融相关数据,通过一种新的技术将非结构化数据转化为结构化数据,适用于微调嵌入模型。数据集生成过程中使用了自我验证的方法,确保生成的问题-答案对不是由LLM虚构的。每个数据点包含四个字段:Topic(主题)、Title(标题)、Question(问题)和Answer(答案)。数据集的语言为英语,许可证为cc-by-nc-4.0。
This dataset consists of finance-related data sourced from the Investopedia website. A novel technique is utilized to transform unstructured data into structured format, rendering it suitable for fine-tuning embedding models. During the dataset generation workflow, a self-verification method is adopted to ensure that the generated question-answer pairs are not fabricated by large language models (LLMs). Each data point contains four fields: Topic, Title, Question, and Answer. The dataset is in English, and its license is CC-BY-NC-4.0.
提供机构:
FinLang
原始信息汇总
数据集卡片 - investopedia-embedding 数据集
数据集描述
概述
investopedia-embedding 数据集是从 Investopedia 收集的关于金融领域的大规模数据集,通过一种新的技术利用非结构化抓取数据和大型语言模型(LLM)生成适合微调嵌入模型的结构化数据。该数据集采用了一种新的自验证方法,确保生成的问答对具有高概率不是由LLM幻觉产生的。
数据点结构
每个数据点包含以下字段:
Topic:问题和答案生成所围绕的主题的一般分类。Title:问题和答案生成所依据的段落的更详细描述或标题。Question:嵌入模型训练数据集中的句子1,也称为锚点。Answer:嵌入模型训练数据集中的句子3,也称为正样本。
示例
json { "Topic": "mortgage", "Title": "<title>How to Use a Home Equity Loan for a Remodel</title>", "Question": "与个人贷款等无担保选项相比,使用房屋净值贷款进行家庭改造有哪些优势?", "Answer": "该段落强调了两个主要优势:房屋净值贷款通常提供比个人贷款等无担保选项更低的利率,这有助于节省家庭改造成本。此外,它们具有固定利率,为每月还款提供稳定性,并在整个还款期限内防止利率变化。" }
数据集信息
- 制作团队: FinLang Team
- 语言: 英语
- 许可证: cc-by-nc-4.0
数据集结构
数据集分为90%的训练集和10%的测试集。
数据集创建
创建动机
在金融领域,语言模型存在三个主要限制:
- 没有适合语言和嵌入模型微调的大型(百万级令牌)公开可用数据集,这是由于内部数据受到大型公司如彭博等的保护,出于金钱和隐私利益。
- 当前语言模型在复杂的金融缩写面前表现不佳,这再次指向了训练模型数据不足的问题。
- 尽管互联网上有大量关于金融的数据,如Investopedia、Yahoo Finance等网站,但很难以适合指令调整或嵌入训练的形式获取数据,因为注释非结构化数据集将产生巨大的成本,需要高薪的金融专家进行注释。
源数据
源数据收集自 Investopedia。
许可证
由于用于生成数据集的数据是非商业性的,因此我们以 cc-by-nc-4.0 许可证发布此数据集。
搜集汇总
数据集介绍
构建方式
FinLang团队针对金融领域的特定需求,从Investopedia网站采集大量金融相关数据,运用非结构化数据抓取技术结合大型语言模型,生成适用于微调嵌入模型的结构化数据。该数据集的构建采用了一种新颖的自我验证方法,以确保生成的问题-答案对不是由LLM产生的幻觉,具有较高的可靠性。
特点
该数据集具有以下显著特点:涵盖了广泛金融主题的问题与答案对,为嵌入模型的微调提供了丰富的资源;采用90-10的训练与测试数据分割比例,有利于模型的有效训练与评估;数据集遵循cc-by-nc-4.0许可,适用于非商业用途的研究与开发。
使用方法
使用该数据集时,研究者可依据数据集的结构化字段,包括主题、标题、问题及答案,进行嵌入模型的训练与测试。数据集的获取可通过HuggingFace的FinLang团队仓库,便于集成到相关研究或应用中。此外,数据集的开放许可使得其成为金融领域自然语言处理研究的宝贵资源。
背景与挑战
背景概述
在金融领域,语言模型的应用受到诸多限制,FinLang团队针对这一现状,精心构建了investopedia-embedding-dataset数据集。该数据集的创建旨在解决金融领域缺乏大规模公开数据集的问题,这些问题数据集对于语言和嵌入模型的微调至关重要。该数据集利用了一种新的无结构数据抓取技术和大型语言模型(LLM)生成结构化数据,这些数据适合于微调嵌入模型。FinLang团队采用了一种新的自我验证方法,确保生成的问题-答案对不太可能由LLM产生幻觉。该数据集的构建时间为近年,主要研究人员为FinLang团队,其核心研究问题是如何在金融领域有效地微调语言模型,对金融领域的自然语言处理研究产生了显著影响。
当前挑战
该数据集在构建过程中面临的挑战包括:一是公开可用的金融领域大规模数据集的缺乏,导致语言模型难以在金融专业术语上达到理想的性能;二是金融文档中常见的复杂金融缩写使得现有语言模型处理能力不足;三是尽管互联网上存在大量金融数据,但将这些无结构数据转化为适合指令调整或嵌入训练的格式成本高昂。此外,数据集在生成过程中还需要克服如何确保LLM生成的问题-答案对的真实性和有效性的挑战。
常用场景
经典使用场景
在金融领域自然语言处理的研究与应用中,FinLang团队精心制作的investopedia-embedding数据集,因其独特的数据结构和高质量的问答对,成为了一款极具价值的资源。该数据集最经典的使用场景在于,研究者可以利用其进行嵌入模型的微调,从而提升模型对金融领域专业知识的理解和应答能力。
衍生相关工作
基于此数据集,已经衍生出一系列相关的研究工作,包括但不限于金融文本分类、情感分析以及金融预测模型的开发。这些研究不仅推动了金融领域自然语言处理技术的进步,也为金融科技的创新发展提供了新的视角和方法论。
数据集最近研究
最新研究方向
在金融语言模型的领域,FinLang团队最新构建的investopedia-embedding-dataset数据集,针对现有模型在金融领域面临的三大挑战:缺乏大规模公开数据集、模型对复杂金融缩写的处理能力不足,以及结构化数据获取成本高昂等问题,提供了创新的解决方案。该数据集通过利用大规模非结构化数据,结合语言模型生成结构化数据,为精细调整嵌入模型提供了优质资源。其独到的自验证技术有效减少了语言模型生成数据时的幻觉现象,对于推动金融领域自然语言处理技术的发展具有重要的实践价值和理论研究意义。
以上内容由遇见数据集搜集并总结生成


