LAMBDA
收藏Hugging Face2024-07-03 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/behavior-in-the-wild/LAMBDA
下载链接
链接失效反馈官方服务:
资源简介:
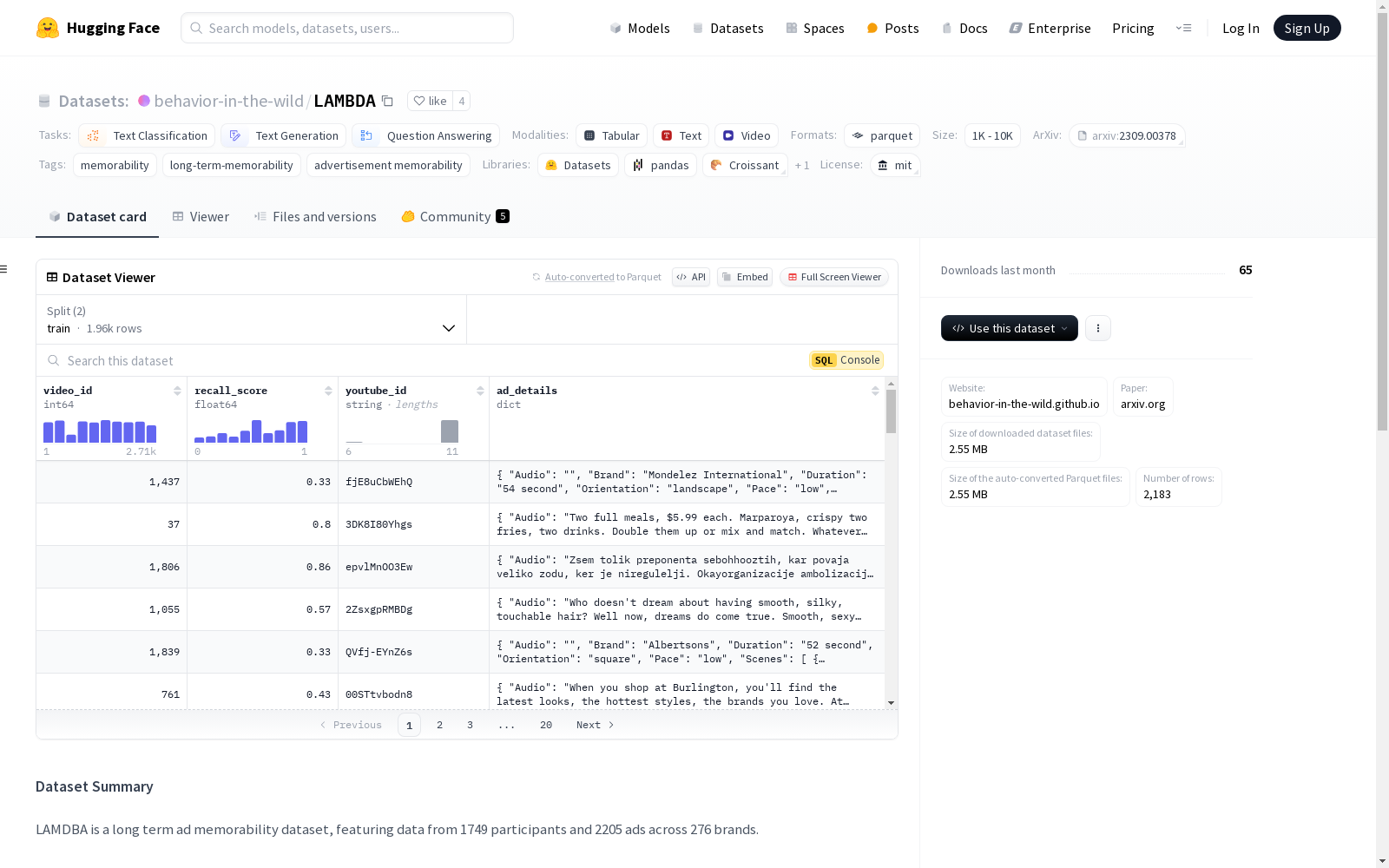
该数据集主要用于分析和评估视频广告的效果。数据集包含视频的唯一标识符(video_id)、召回分数(recall_score)、YouTube视频标识符(youtube_id)以及广告详情(ad_details)。广告详情是一个结构化特征,包含音频(Audio)、品牌(Brand)、持续时间(Duration)等多个子特征。数据集分为训练集和测试集,分别包含1964和219个样本。数据集的总大小为5707189.0字节,下载大小为2281142字节。
创建时间:
2024-07-03
原始信息汇总
数据集概述
数据集信息
- 名称: Long Term Memorability of Advertisements (LAMBDA)
- 许可证: MIT
- 任务类别:
- 文本分类
- 文本生成
- 问答
- 标签:
- 记忆性
- 长期记忆性
- 广告记忆性
数据集结构
- 特征:
video_id: 数据样本的标识符,类型为int64recall_score: 视频的记忆性分数,范围为 0 到 1,类型为float64youtube_id: 视频的 YouTube ID,类型为stringad_details: 每个视频的场景特征,包含以下结构:Audio: 音频,类型为stringBrand: 品牌,类型为stringDuration: 时长,类型为stringOrientation: 方向,类型为stringPace: 节奏,类型为stringScenes: 场景列表,包含以下子特征:Colors: 颜色,类型为stringDescription: 描述,类型为stringEmotions: 情感,类型为stringNumber: 数量,类型为stringPhotography Style: 摄影风格,类型为stringTags: 标签,类型为stringText Shown: 显示的文本,类型为stringTone: 色调,类型为stringVisual Complexity: 视觉复杂度,类型为string
Title: 标题,类型为string
数据分割
- 训练集:
- 样本数量: 1964
- 字节数: 5490622.457169034
- 测试集:
- 样本数量: 219
- 字节数: 612243.5428309665
数据集大小
- 下载大小: 2551503 字节
- 数据集大小: 6102866 字节
配置
- 默认配置:
- 训练集路径:
data/train-* - 测试集路径:
data/test-*
- 训练集路径:
引用
plaintext @misc{s2024longtermadmemorabilityunderstanding, title={Long-Term Ad Memorability: Understanding and Generating Memorable Ads}, author={Harini S I au2 and Somesh Singh and Yaman K Singla and Aanisha Bhattacharyya and Veeky Baths and Changyou Chen and Rajiv Ratn Shah and Balaji Krishnamurthy}, year={2024}, eprint={2309.00378}, archivePrefix={arXiv}, primaryClass={cs.CL}, url={https://arxiv.org/abs/2309.00378} }
搜集汇总
数据集介绍
构建方式
LAMBDA数据集的构建基于1749名参与者对2205个广告的长期记忆测试,涵盖了276个品牌。数据采集过程中,每个广告的视频内容被详细分解为多个场景特征,包括音频、品牌、时长、方向、节奏等,并通过结构化数据记录每个场景的色彩、描述、情感、数量、摄影风格、标签、显示文本、语调和视觉复杂性。这些数据经过标准化处理,确保了数据的一致性和可用性。
使用方法
使用LAMBDA数据集时,用户可以通过Hugging Face的`datasets`库加载数据,数据集分为训练集和测试集,分别包含1964和219个样本。每个样本包含视频ID、记忆性得分、YouTube ID以及广告的详细场景特征。研究者可以利用这些数据进行文本分类、文本生成或问答任务,探索广告记忆性的生成和理解。数据集的使用方法简单直观,适合用于广告记忆性研究的多种场景。
背景与挑战
背景概述
LAMBDA数据集由Harini S I au2等研究人员于2024年创建,旨在研究广告的长期记忆性。该数据集涵盖了1749名参与者和276个品牌的2205个广告,通过视频广告的详细场景特征和记忆评分,为广告记忆性研究提供了丰富的数据支持。LAMBDA数据集的核心研究问题在于如何理解和生成具有长期记忆性的广告,这对于广告创意和营销策略的优化具有重要意义。该数据集的出现填补了广告记忆性研究领域的空白,为相关领域的学术研究和实际应用提供了宝贵的数据资源。
当前挑战
LAMBDA数据集面临的挑战主要集中在两个方面。首先,广告记忆性的评估具有高度主观性,如何准确量化记忆评分并确保其可靠性是一个技术难题。其次,数据集的构建过程中,收集和标注大量广告视频的详细场景特征需要耗费大量的人力和时间资源,且需确保标注的一致性和准确性。此外,广告记忆性研究涉及多学科交叉,如何有效整合心理学、市场营销和计算机科学等领域的知识,也是该数据集在应用过程中需要克服的挑战。
常用场景
经典使用场景
LAMBDA数据集在广告记忆性研究领域具有重要应用,尤其在评估广告的长期记忆效果方面。研究者通过分析广告的视觉复杂性、情感表达、摄影风格等特征,结合参与者的记忆评分,能够深入理解广告内容如何影响观众的长期记忆。这一数据集为广告创意优化提供了科学依据,帮助广告从业者设计更具记忆点的广告内容。
解决学术问题
LAMBDA数据集解决了广告记忆性研究中的关键问题,即如何量化广告的长期记忆效果。通过提供详细的广告场景特征和记忆评分,研究者能够建立广告内容与记忆效果之间的关联模型,从而揭示广告设计中的关键记忆因素。这一研究不仅推动了广告心理学的发展,还为广告效果的量化评估提供了新的方法论。
实际应用
在实际应用中,LAMBDA数据集被广泛用于广告行业的创意优化和效果评估。广告公司利用该数据集分析广告的视觉和情感特征,优化广告内容以提高观众的长期记忆效果。此外,该数据集还被用于开发广告记忆性预测模型,帮助广告主在投放前评估广告的潜在记忆效果,从而提升广告投放的精准性和有效性。
数据集最近研究
最新研究方向
在广告记忆性研究领域,LAMBDA数据集为长期广告记忆性提供了丰富的数据支持。该数据集通过收集1749名参与者和2205个广告的数据,涵盖了276个品牌,为研究者提供了广告记忆性评分的详细记录。当前研究热点集中在利用深度学习模型预测广告的长期记忆性,以及探索广告内容特征(如场景、情感、视觉复杂度等)对记忆性的影响。这些研究不仅有助于优化广告设计,还能为广告效果的量化评估提供科学依据,推动广告行业向数据驱动的方向发展。
以上内容由遇见数据集搜集并总结生成


