newsxlm-mhtml
收藏Hugging Face2025-12-25 更新2025-12-26 收录
下载链接:
https://huggingface.co/datasets/ispras-crawlers/newsxlm-mhtml
下载链接
链接失效反馈官方服务:
资源简介:
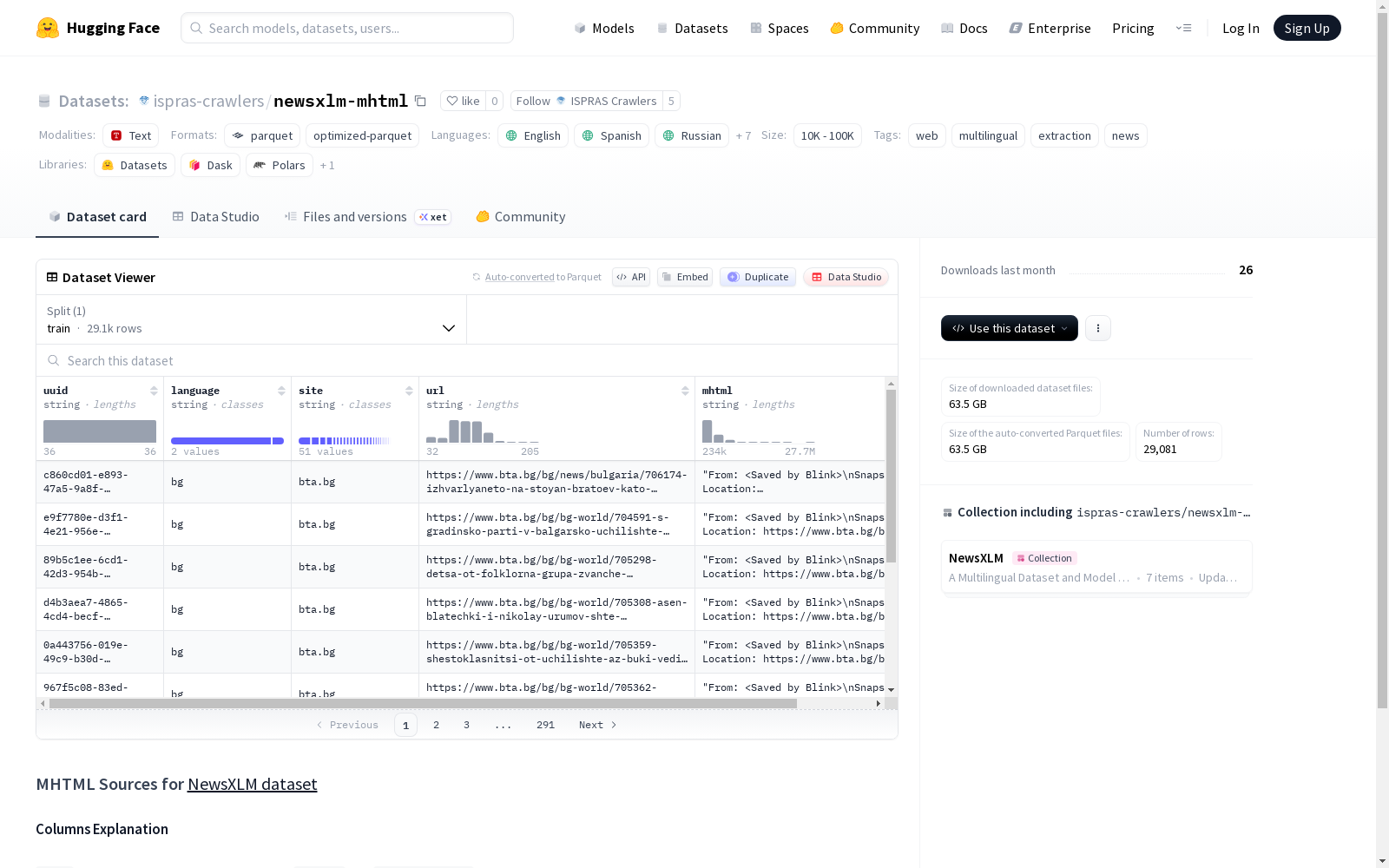
该数据集是NewsXLM数据集的MHTML来源,包含多语言的网页快照数据。数据集的特征包括uuid、language、site、url和mhtml,其中mhtml列包含经过WTL算法处理的网页快照。数据集支持多种语言(如英语、西班牙语、俄语、阿拉伯语、法语、葡萄牙语、克罗地亚语、中文、德语和韩语),并标记为web、multilingual、extraction和news类别。数据集的规模在10K到100K之间,具体包含29,081个训练样本。
创建时间:
2025-12-25
原始信息汇总
数据集概述
基本信息
- 数据集名称: MHTML Sources for NewsXLM dataset
- 托管地址: https://huggingface.co/datasets/ispras-crawlers/newsxlm-mhtml
- 关联数据集: NewsXLM dataset
数据内容与结构
- 数据格式: MHTML网页快照
- 数据列:
uuid: 字符串类型,唯一标识符language: 字符串类型,语言代码site: 字符串类型,网站来源url: 字符串类型,网页URLmhtml: 字符串类型,MHTML格式的网页内容快照
- 特殊处理: MHTML快照中,
<body>内的每个元素均添加了wtl-uid和wtl-parent-uid属性,遵循WTL算法。
数据集统计
- 数据分割: 仅包含训练集(train)
- 训练集样本数: 29,081
- 训练集大小: 84,012,036,587字节
- 下载大小: 63,542,382,099字节
- 数据集总大小: 84,012,036,587字节
语言与标签
- 支持语言: 英语(en)、西班牙语(es)、俄语(ru)、阿拉伯语(ar)、法语(fr)、葡萄牙语(pt)、克罗地亚语(hr)、中文(zh)、德语(de)、韩语(ko)
- 标签: web、multilingual、extraction、news
- 规模分类: 10K < n < 100K(样本数在1万到10万之间)
搜集汇总
数据集介绍
构建方式
在新闻信息抽取领域,多语言数据的获取与处理是推动跨语言模型发展的关键。newsxlm-mhtml数据集依托NewsXLM项目的框架,通过自动化网络爬虫技术,从全球多个新闻网站系统性地采集了涵盖英语、西班牙语、俄语、阿拉伯语、法语、葡萄牙语、克罗地亚语、中文、德语和韩语等十种语言的网页内容。其核心构建方法在于将原始HTML页面转换为MHTML格式的快照,并创新性地为每个<body>内的页面元素注入了“wtl-uid”和“wtl-parent-uid”属性,这一过程严格遵循Web遍历库的算法规范,旨在为后续的结构化信息抽取提供精确的文档对象模型锚点。
使用方法
研究人员在利用newsxlm-mhtml数据集时,主要将其作为训练或评估网页信息抽取模型的原料。使用流程始于加载MHTML格式的文件,并解析其中嵌入的WTL属性,这些属性能够精准定位页面中的文本块及其父子关系。基于此,开发者可以构建模型来识别新闻文章的标题、正文、作者、发布时间等关键元数据,或是进行更复杂的跨语言内容对齐与语义分析。该数据集通常与NewsXLM主数据集配合使用,为从原始网页到结构化知识的转换管道提供了不可或缺的中间层支持。
背景与挑战
背景概述
随着自然语言处理领域对多语言文本数据需求的日益增长,新闻文本因其时效性与广泛覆盖性成为关键资源。NewsXLM-MHTML数据集由ISPRAS-Crawlers研究团队构建,旨在为跨语言预训练模型提供高质量的网页原始数据支撑。该数据集采集了涵盖英语、西班牙语、俄语、阿拉伯语、法语、葡萄牙语、克罗地亚语、中文、德语和韩语等多种语言的新闻网页,通过MHTML格式保存完整页面快照,并嵌入了Web遍历库的元数据标记,以支持结构化信息抽取任务。其核心研究问题聚焦于如何从异构网页源中有效提取对齐的多语言文本,进而推动机器翻译、跨语言检索等应用的发展,自发布以来已成为多语言NLP社区的重要基准之一。
当前挑战
在新闻文本的多语言处理领域,主要挑战在于如何从非结构化的网页内容中准确分离出新闻正文,同时去除广告、导航栏等噪声信息,并保持不同语言间文本的语义对齐。数据集构建过程中,研究者需应对网页布局的多样性、动态加载内容的捕获困难,以及多语言编码与文本归一化的复杂性。此外,MHTML格式虽能完整保存页面状态,但数据体积庞大,给存储与处理效率带来压力,且嵌入的WTL元数据标记需确保与原始DOM结构的一致性,这对大规模自动化爬取与清洗流程的鲁棒性提出了较高要求。
常用场景
经典使用场景
在跨语言新闻内容分析领域,newsxlm-mhtml数据集为研究者提供了多语言网页的原始MHTML快照,这些快照通过WTL算法增强了元素级元数据标注。该数据集最经典的使用场景是支持跨语言文本提取与对齐任务,例如在新闻文章中识别结构化信息如标题、作者或正文,并实现不同语言版本间的语义映射。通过利用其丰富的语言覆盖和网页结构信息,研究人员能够训练模型以理解多语言网页的布局与内容关联,为后续的机器翻译、信息检索等任务奠定数据基础。
解决学术问题
该数据集主要解决了跨语言自然语言处理中的网页内容结构化提取难题,特别是在新闻领域,传统方法往往受限于语言差异和网页布局复杂性。newsxlm-mhtml通过提供标注了WTL元数据的多语言MHTML快照,使研究者能够开发算法以自动识别网页中的语义单元,从而促进跨语言信息对齐、内容摘要和知识图谱构建等研究。其意义在于降低了多语言数据处理的壁垒,推动了全球化新闻分析技术的发展,对跨文化传播研究产生了深远影响。
实际应用
在实际应用中,newsxlm-mhtml数据集被广泛用于构建多语言新闻聚合系统,帮助媒体机构自动化收集和整理全球新闻内容。例如,企业可以利用该数据集训练模型,从不同语言的新闻网站中提取关键事件或趋势信息,以支持市场分析或舆情监测。此外,它还为跨语言搜索引擎优化提供了数据支撑,使系统能更准确地理解用户查询并返回相关多语言结果,从而提升信息服务的覆盖范围和效率。
数据集最近研究
最新研究方向
在跨语言新闻分析领域,newsxlm-mhtml数据集凭借其多语言MHTML快照结构,为前沿研究提供了关键支持。当前研究聚焦于利用其增强的网页元素元数据,探索跨语言信息抽取与语义对齐技术,尤其在低资源语言处理中展现出潜力。该数据集与大规模多语言预训练模型相结合,推动了新闻内容的结构化解析与知识图谱构建,相关热点事件如全球虚假新闻检测与多语言舆情分析,进一步凸显了其在促进信息公平与跨文化理解方面的重要意义。
以上内容由遇见数据集搜集并总结生成


