litagin/Galgame_Speech_ASR_16kHz
收藏Hugging Face2024-10-14 更新2024-12-14 收录
下载链接:
https://hf-mirror.com/datasets/litagin/Galgame_Speech_ASR_16kHz
下载链接
链接失效反馈官方服务:
资源简介:
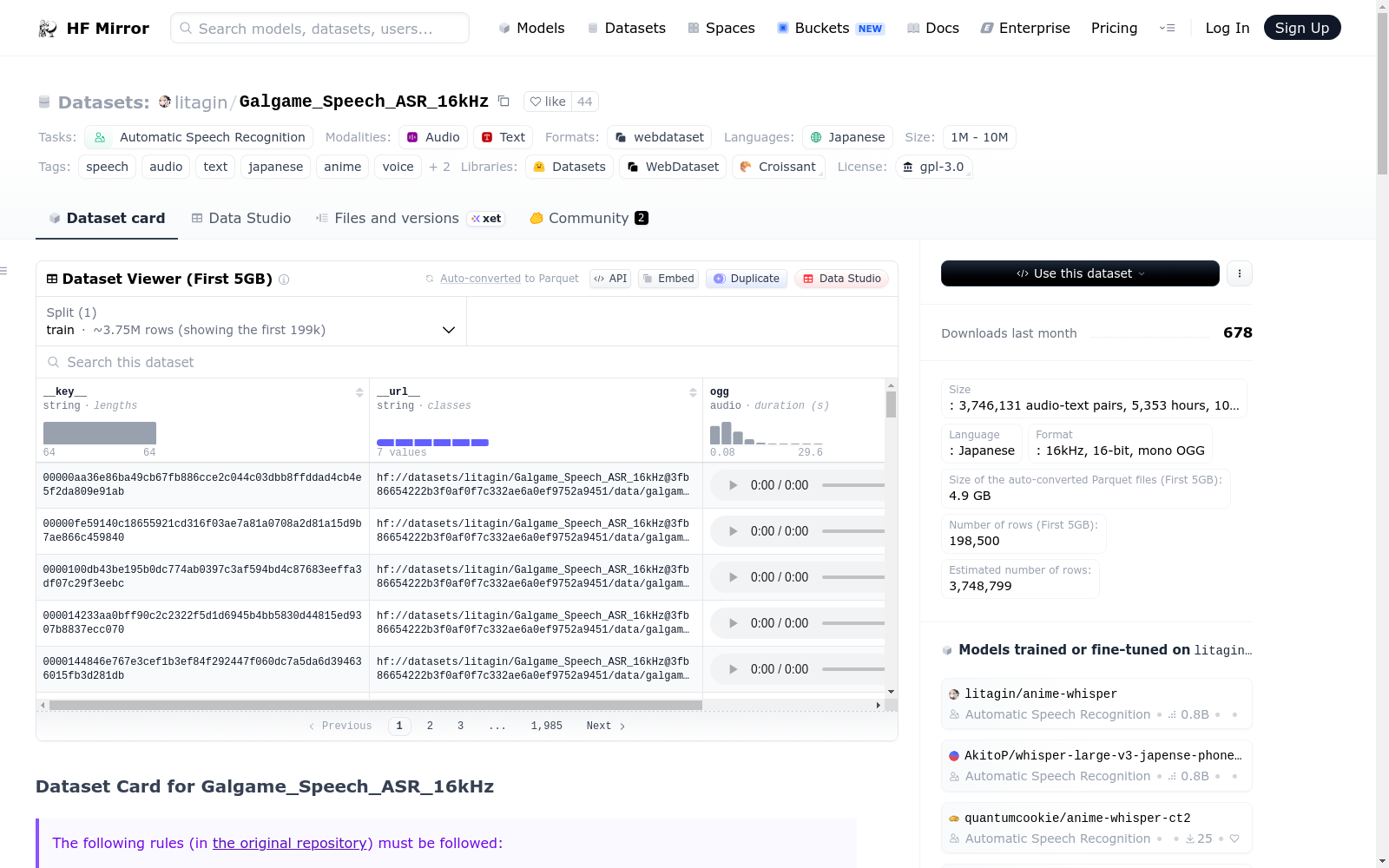
Galgame_Speech_ASR_16kHz是一个日语语音数据集,专门用于训练自动语音识别(ASR)模型,特别是针对动漫风格的语音。数据集包含3,746,131个音频-文本对,总时长为5,353.9小时,数据总量为100.16 GB。音频文件为16kHz、16位、单声道的OGG格式。数据集是从OOPPEENN/Galgame_Dataset派生而来,并进行了多项修改以适应ASR训练需求,包括重新采样音频文件、规范化文本、过滤不符合要求的音频等。数据集的使用受到GNU General Public License v3.0的限制,禁止商业用途,并要求使用该数据集训练的模型必须开源。
The Galgame_Speech_ASR_16kHz dataset is a Japanese speech dataset extracted from Japanese visual novels (Galgames), specifically designed for training Automatic Speech Recognition (ASR) models like Whisper. The dataset contains 3,746,131 audio files with corresponding transcriptions, totaling 5,353 hours and 100.16 GB in size. The dataset is stored in WebDataset format, with audio files in 16kHz, 16-bit, mono OGG format. The creation motivation of the dataset was to provide a large-scale Japanese audio-text pair corpus, especially in the anime-like speech domain, voiced by professional voice actors, with 100% accurate transcriptions. The datasets applications include fine-tuning ASR models, benchmarking Japanese ASR models, and training ASR models for the NSFW domain. The limitations of the dataset include its unsuitability for Text-to-Speech (TTS) and Voice Conversion (VC) tasks, low audio quality, and a potential gender bias due to more female voices than male voices in the dataset.
提供机构:
litagin
搜集汇总
数据集介绍
背景与挑战
背景概述
Galgame_Speech_ASR_16kHz是一个大规模的日语语音数据集,专为训练自动语音识别模型设计,特别适合处理动漫风格和NSFW内容的语音。数据集包含超过3.7百万个音频-文本对,总时长超过5,353小时,所有音频均以16kHz的OGG格式提供,并经过严格的文本规范化处理。
以上内容由遇见数据集搜集并总结生成


