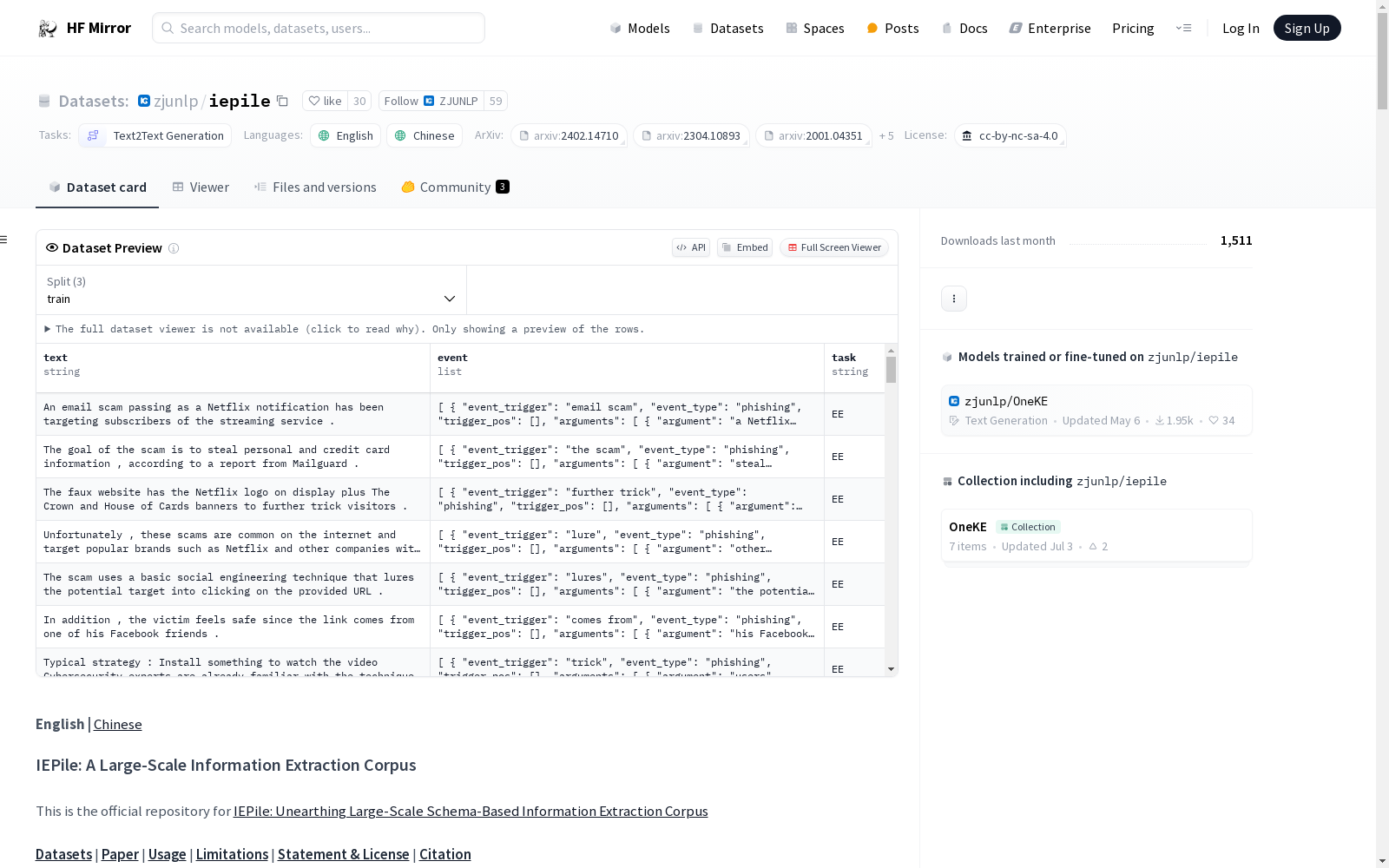
zjunlp/iepile
收藏数据集概述
数据集名称
IEPile: A Large-Scale Information Extraction Corpus
数据集描述
IEPile是一个大规模的信息提取数据集,专注于基于schema的指令生成方法。该数据集整合了26个英文和7个中文信息提取(IE)数据集,覆盖多个领域,如通用、医疗、金融等。
数据集内容
- 语言: 英文(en)和中文(zh)
- 任务类别: 文本到文本生成(text2text-generation)
- 数据格式: 每个实例包含四个字段:
task,source,instruction,output。其中instruction采用JSON-like字符串结构,包含instruction,schema,input三个主要组件。 - 数据集结构: 包含训练集(train.json)、验证集(dev.json)以及针对英文和中文的统一格式数据(IE-en, IE-zh)。
数据集使用
- 模型训练: 基于IEPile,使用Lora技术对Baichuan2-13B-Chat和LLaMA2-13B-Chat模型进行微调,显著提升了零样本信息提取任务的性能。
- 数据集更新: 数据集可能会进行更新,建议使用最新版本。
许可证
数据集遵循CC BY-NC-SA 4.0许可协议。
数据集限制
- 主要关注schema-based IE,未探索Open IE。
- 目前仅包含英文和中文数据,未来计划扩展到更多语言。
- 由于计算资源限制,仅评估了Baichuan和LLaMA模型。
引用信息
若使用IEPile或相关代码,请引用以下文献:
@article{DBLP:journals/corr/abs-2402.14710, author = {Honghao Gui and Lin Yuan and Hongbin Ye and Ningyu Zhang and Mengshu Sun and Lei Liang and Huajun Chen}, title = {IEPile: Unearthing Large-Scale Schema-Based Information Extraction Corpus}, journal = {CoRR}, volume = {abs/2402.14710}, year = {2024}, url = {https://doi.org/10.48550/arXiv.2402.14710}, doi = {10.48550/ARXIV.2402.14710}, eprinttype = {arXiv}, eprint = {2402.14710}, timestamp = {Tue, 09 Apr 2024 07:32:43 +0200}, biburl = {https://dblp.org/rec/journals/corr/abs-2402-14710.bib}, bibsource = {dblp computer science bibliography, https://dblp.org} }