rpr
收藏Hugging Face2024-07-26 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/microsoft/rpr
下载链接
链接失效反馈官方服务:
资源简介:
Reasonable Preference Reversal (RPR) Dataset是一个合成条件-条件偏好数据集,包含超过20000个配对元组,包括提示、上下文(标准或场景)和偏好判断。该数据集的设计确保了在没有上下文的情况下,两个完成的偏好是完全模糊的,从而测试模型对上下文的关注和解释能力。数据集主要用于训练和评估上下文感知偏好模型,特别是在需要上下文理解和偏好确定的任务中。数据集由Silviu Pitis等人创建,主要语言为英语。
The Reasonable Preference Reversal (RPR) Dataset is a synthetic conditional-conditional preference dataset comprising over 20,000 paired tuples, including prompts, contexts (either standard or scenario-based) and preference judgments. The dataset is designed such that the two presented preferences are completely ambiguous without the accompanying context, thereby testing a model's ability to attend to and interpret contextual information. It is primarily used for training and evaluating context-aware preference models, especially for tasks requiring contextual comprehension and preference determination. The dataset was created by Silviu Pitis et al., and its primary language is English.
提供机构:
Microsoft
创建时间:
2024-07-26
原始信息汇总
RPR 数据集概述
数据集描述
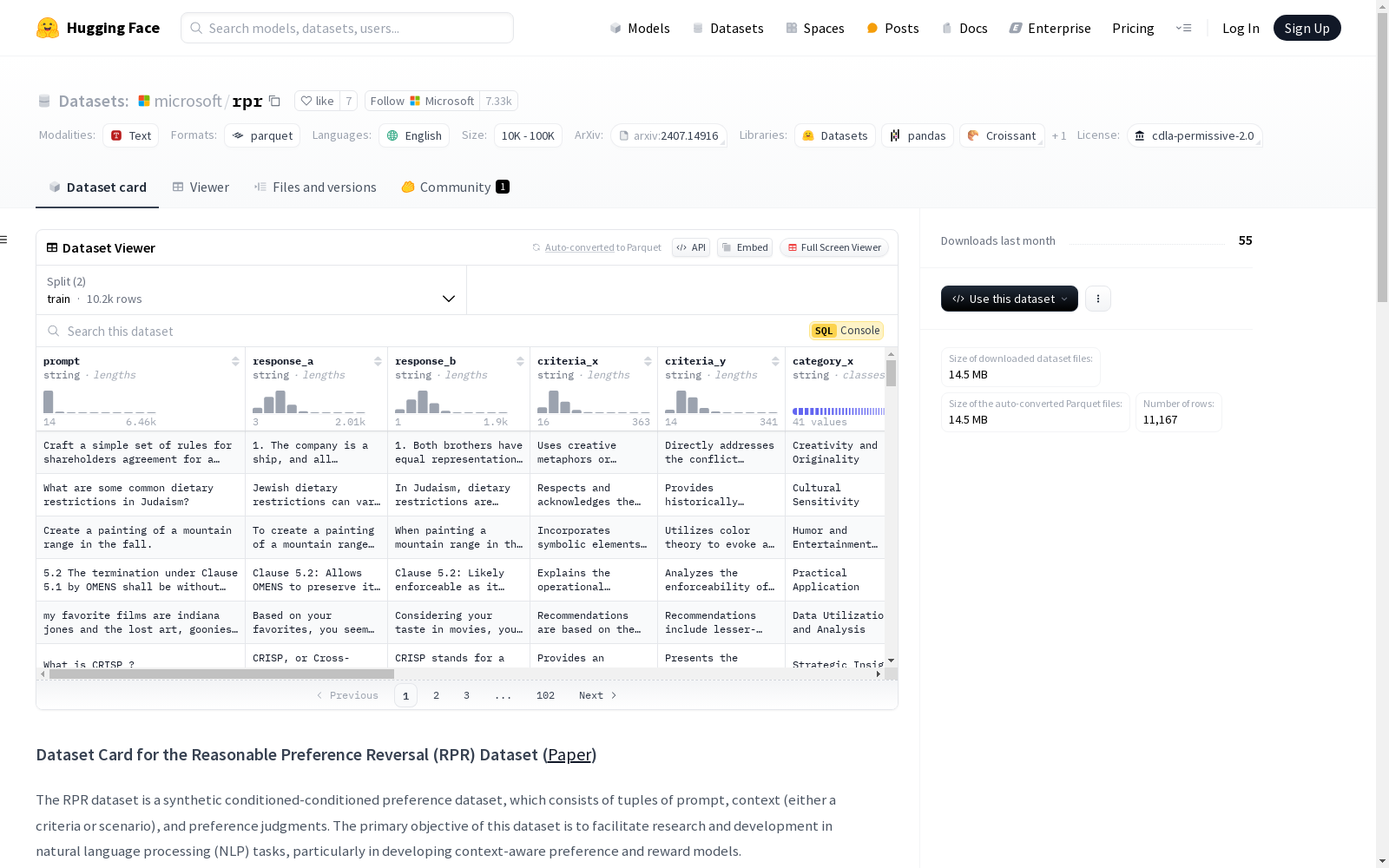
RPR 数据集是一个合成条件-条件偏好数据集,包含超过 20000 对提示、上下文(标准或场景)和偏好判断的元组。每个样本成对出现,使得同一提示下的两个完成之间的偏好完全模糊,除非有上下文:对于每个上下文,都存在一个替代上下文,使得偏好反转。这种设计确保了在该数据集上的偏好预测性能完全取决于模型对上下文的注意力和解释能力。
数据集结构
特征
- prompt: 字符串
- response_a: 字符串
- response_b: 字符串
- criteria_x: 字符串
- criteria_y: 字符串
- category_x: 字符串
- category_y: 字符串
- id: 整数
- scenario_x: 字符串
- scenario_y: 字符串
- profile_0: 字符串
- profile_1: 字符串
- profile_2: 字符串
- profile_3: 字符串
- profile_4: 字符串
分割
- train: 包含 10167 个样本,22281359 字节
- test: 包含 1000 个样本,2228352 字节
文件大小
- 下载大小: 14545101 字节
- 数据集大小: 24509711 字节
配置
- default: 包含训练和测试数据文件
语言
- 英语
使用场景
该数据集可用于训练和评估上下文感知偏好模型,特别是在需要上下文理解和偏好确定的任务中。它提供了一个受控环境,用于实验偏好建模。
数据集创建
数据集的创建细节见论文附录 B。
偏差、风险和限制
- 数据集主要为英语语言
- 合成数据可能不具备真实世界数据的丰富性和多样性
- 偏好指示基于预定义标准,可能与所有潜在用户视角不一致
建议
用户应意识到,基于合成数据训练的系统在实际部署时的性能可能有所不同。
引用
@misc{pitis2024improvingcontextawarepreferencemodeling, title={Improving Context-Aware Preference Modeling for Language Models}, author={Silviu Pitis and Ziang Xiao and Nicolas Le Roux and Alessandro Sordoni}, year={2024}, eprint={2407.14916}, archivePrefix={arXiv}, primaryClass={cs.CL}, url={https://arxiv.org/abs/2407.14916}, }
联系信息
Silviu Pitis (silviu.pitis@gmail.com)
搜集汇总
数据集介绍
构建方式
RPR数据集是一个合成的条件偏好数据集,旨在通过特定的上下文(如标准或场景)来研究自然语言处理中的偏好建模。数据集的构建基于成对的提示、上下文和偏好判断,确保在没有上下文的情况下,两个完成选项的偏好是完全模糊的。这种设计使得模型必须依赖上下文来做出准确的偏好预测。数据集的合成过程详细记录在相关论文的附录B中,确保了数据的科学性和可重复性。
特点
RPR数据集的特点在于其独特的上下文依赖性设计,每个样本都包含提示、两个响应选项以及相关的上下文信息。数据集中的偏好判断完全依赖于上下文,这意味着相同的提示在不同的上下文中可能会导致完全相反的偏好选择。这种设计不仅增强了数据集的研究价值,还为开发上下文感知的偏好模型提供了理想的实验平台。此外,数据集涵盖了多种场景和标准,进一步丰富了其应用场景。
使用方法
RPR数据集主要用于训练和评估上下文感知的偏好模型,特别是在需要理解上下文并做出偏好判断的任务中。用户可以通过分析数据集中的提示、响应和上下文信息,探索模型在不同上下文下的表现。数据集的结构清晰,每个样本都明确标注了在不同上下文下的偏好选择,便于用户进行实验设计和结果分析。此外,数据集还提供了详细的元数据,帮助用户更好地理解数据的背景和应用场景。
背景与挑战
背景概述
Reasonable Preference Reversal (RPR) 数据集由微软研究院蒙特利尔分部的Silviu Pitis、Ziang Xiao、Nicolas Le Roux和Alessandro Sordoni等人于2024年创建,旨在推动自然语言处理(NLP)领域的研究,特别是在上下文感知偏好和奖励模型的开发方面。该数据集包含超过20000组由提示、上下文(标准或场景)和偏好判断组成的元组,其设计核心在于通过上下文反转来确保模型必须依赖上下文信息进行偏好预测。这一独特的设计为研究上下文理解与偏好建模提供了高度可控的实验环境,推动了NLP领域对复杂上下文依赖任务的理解与建模能力。
当前挑战
RPR数据集在构建与应用过程中面临多重挑战。首先,该数据集旨在解决上下文感知偏好建模的复杂问题,要求模型能够准确理解并利用上下文信息进行偏好判断,这对模型的上下文理解能力提出了极高要求。其次,由于数据集为合成数据,其多样性与真实世界数据的丰富性存在差距,可能导致模型在实际应用中的泛化能力受限。此外,数据集中预设的偏好标准可能无法涵盖所有用户视角,进一步增加了模型训练的复杂性。这些挑战不仅体现在数据集的构建过程中,也对后续模型的训练与评估提出了更高的要求。
常用场景
经典使用场景
RPR数据集在自然语言处理领域中的经典使用场景主要集中在对上下文感知偏好模型的训练与评估。该数据集通过提供成对的提示、上下文(标准或场景)以及偏好判断,为研究人员提供了一个理想的实验平台,用于探索模型在不同上下文条件下如何理解和预测用户偏好。这种设计使得模型必须依赖于上下文信息来做出准确的偏好判断,从而推动了上下文感知模型的发展。
解决学术问题
RPR数据集解决了自然语言处理领域中一个关键问题,即如何在复杂的上下文环境中准确预测用户偏好。传统偏好模型往往忽略了上下文的重要性,导致在多变的环境中表现不佳。RPR数据集通过引入上下文条件,使得模型能够更好地理解并利用上下文信息,从而提高了偏好预测的准确性。这一突破为上下文感知模型的研究提供了新的方向,并推动了相关领域的技术进步。
衍生相关工作
RPR数据集的推出催生了一系列相关研究工作,特别是在上下文感知偏好建模领域。许多研究团队基于RPR数据集开发了新的算法和模型,进一步提升了上下文感知模型的性能。例如,一些研究通过引入更复杂的上下文编码机制,显著提高了模型在复杂环境中的表现。此外,RPR数据集还被用于评估和改进现有的偏好模型,推动了自然语言处理技术的持续发展。
以上内容由遇见数据集搜集并总结生成


