BOE-XSUM
收藏arXiv2025-09-29 更新2025-10-01 收录
下载链接:
https://huggingface.co/datasets/bertin-project/BOE-XSUM
下载链接
链接失效反馈官方服务:
资源简介:
BOE-XSUM数据集包含来自西班牙《国家官方公报》的3648个清晰且极其简洁的摘要,以及其原始文本。该数据集旨在解决西班牙法律文件中缺乏简洁摘要的问题,并通过将复杂的专业语言转化为清晰的语言来提高文件的可读性。数据集的创建过程包括从社交媒体帖子中提取摘要,并进行人工编辑以确保其准确性和清晰性。BOE-XSUM数据集适用于法律和行政领域的研究和应用,有助于提高语言模型在生成简洁摘要方面的能力。
提供机构:
西班牙国立远程教育大学,挪威国家图书馆
创建时间:
2025-09-29
原始信息汇总
BOE-XSUM 数据集概述
数据集基本信息
- 数据集名称: BOE-XSUM Balanced Dataset - Reviewed and Cleaned
- 许可证: CC-BY-4.0
- 语言: 西班牙语 (es)
- 任务类别: 文本摘要、文本分类
数据集规模
- 总大小: 221,528,042 字节
- 下载大小: 84,283,000 字节
- 训练集: 2867 个样本,179,564,763 字节
- 验证集: 392 个样本,19,448,939 字节
- 测试集: 389 个样本,22,514,340 字节
数据集内容
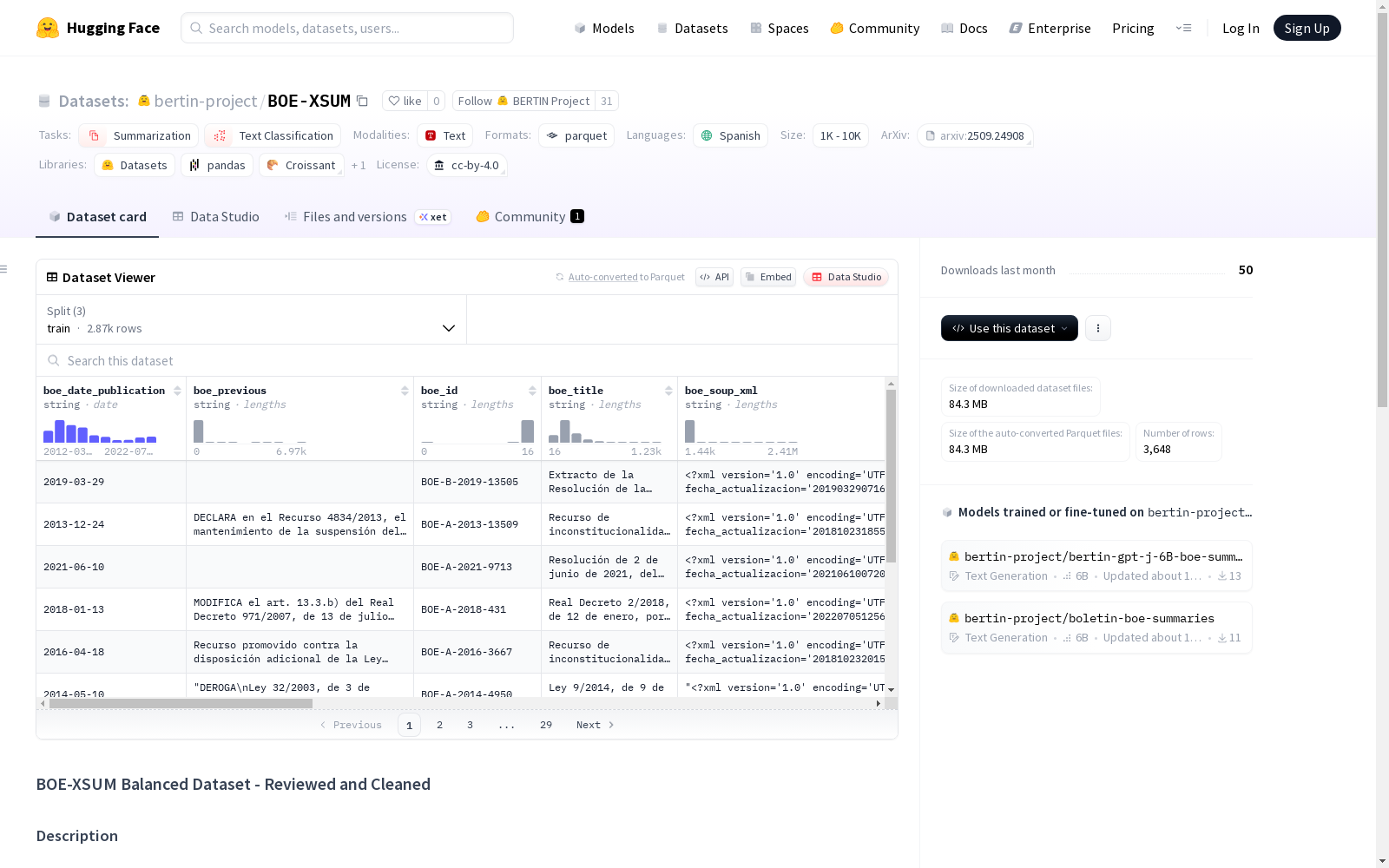
该数据集包含BOE文章及其极端摘要,经过精心平衡和清理,主要用于评估生成模型。
数据字段说明
- id: 项目唯一标识符
- boe_materials: BOE使用的分类标识符
- boe_date_publication: BOE文章发布日期
- boe_previous: 受此新BOE影响的先前BOE文章
- boe_id: BOE标识符
- boe_title: BOE文章标题
- boe_soup_xml: 完整抓取的网页内容
- tweet_original: Eva Belmonte的原始推文
- boe_category: 项目所属类别
- boe_alert: 国家领域中的BOE分类代码
- boe_departament: BOE文章来源部门
- tweet_text_cleaned: 从Eva Belmonte推文精心审查生成的极端摘要
- boe_subsequent: 被此命令修改的法律(仅适用于涉及立法的文章)
数据配置
- 配置名称: default
- 数据文件路径:
- 训练集: data/train-*
- 验证集: data/validation-*
- 测试集: data/test-*
相关资源
- 详细论文: https://arxiv.org/abs/2509.24908
搜集汇总
数据集介绍
构建方式
在法律信息过载日益严重的背景下,BOE-XSUM数据集通过系统化流程构建而成。研究团队从西班牙记者每日发布的官方公报社交媒体摘要中收集原始数据,经过多轮人工审核确保内容与《国家官方公报》原文的准确对应。通过开发专用可视化工具对3648条数据进行逐条验证,对存在语义偏差的摘要进行专业编辑,最终形成包含原始文本、编辑后摘要和文档类型标签的完整数据集。
特点
该数据集在西班牙语法律文本处理领域具有显著特色。其核心价值在于将复杂的法律条文转化为通俗易懂的日常语言,平均压缩率仅为0.005%,每份摘要控制在15-22个词汇量。数据集涵盖宪法法院裁决、行政协议、人事任免等18个互斥的法律文档类别,且通过余弦相似度分析显示约三分之一摘要与原始推文保持90%以上语义一致性,确保了内容的专业性与可读性平衡。
使用方法
该数据集主要应用于法律文本极端摘要任务的模型训练与评估。研究人员可采用微调策略在BERTIN GPT-J 6B等模型上进行领域适配,通过添加###RESUMEN:标记构建输入输出映射。在零样本设置下,建议使用特定提示模板指导模型生成符合字符限制的摘要。评估时需综合运用BLEU、ROUGE、METEOR和BERTScore等多维度指标,同时注意生成摘要长度与评分间的负相关特性,以确保评估结果的全面性。
背景与挑战
背景概述
BOE-XSUM数据集由西班牙国立远程教育大学与挪威国家图书馆等机构于2025年联合构建,旨在填补西班牙语法律文本极端摘要任务的资源空白。该数据集从西班牙《国家官方公报》中精选3,648份法律法令与通知,通过专业记者的社交媒体摘要与人工校对,构建了首个面向西班牙语法律领域的极端摘要基准。其核心研究聚焦于将复杂法律术语转化为清晰易懂的日常语言,推动法律文本的公众可及性,对西班牙语自然语言处理与法律人工智能领域具有开创性意义。
当前挑战
该数据集面临双重技术挑战:在领域问题层面,需解决法律文本极端摘要中专业术语语义保留与语言风格转换的平衡难题,既要压缩原文99.5%的内容,又要确保法律要点的准确传达;在构建过程中,遭遇法律文档结构异构性带来的信息提取困难,包括PDF格式转换误差、长文本截断导致关键语境丢失,以及人工校对时对记者主观表述的客观化重构。此外,数据类别分布不均衡与法律文本特有的嵌套引用结构,进一步增加了高质量摘要生成的复杂度。
常用场景
经典使用场景
在法律信息处理领域,BOE-XSUM数据集为西班牙语法律文本的极端摘要任务提供了标准化基准。该数据集最经典的使用场景是训练和评估生成模型在西班牙官方公报文档上的极端摘要能力,要求模型将冗长的法律条文转化为简洁明了的日常语言摘要,通常控制在280字符以内。这种应用场景特别适合社交媒体平台的传播需求,能够有效解决法律文本与公众理解之间的信息鸿沟。
解决学术问题
该数据集主要解决了西班牙语自然语言处理资源匮乏的核心问题,特别是在法律领域极端摘要任务的空白。通过提供3648条经过人工编辑的法律文档摘要对,它为研究社区建立了可靠的评估基准,使得研究者能够系统比较不同模型在复杂领域文本理解与生成任务上的表现。数据集还揭示了领域自适应预训练与目标任务之间的语言学匹配问题,为语言模型在专业领域的应用提供了重要启示。
衍生相关工作
基于BOE-XSUM数据集,研究社区已开展多项相关探索工作。BERTIN GPT-J 6B模型的领域自适应研究展示了专业领域预训练对法律文本处理的影响,而不同精度参数高效微调技术的比较为资源受限环境下的模型部署提供了实践指导。这些工作进一步推动了西班牙语法律文本处理技术的发展,并为多语言法律人工智能系统的构建奠定了重要基础,激励了后续在长文本处理、领域适应和评估指标优化等方面的深入研究。
以上内容由遇见数据集搜集并总结生成


