RuBLiMP
收藏arXiv2024-06-27 更新2024-07-23 收录
下载链接:
https://huggingface.co/datasets/RussianNLP/rublimp
下载链接
链接失效反馈官方服务:
资源简介:
RuBLiMP是由爱丁堡大学等机构创建的俄语语言学最小对齐基准数据集,包含45000对句子,专门用于评估语言模型的语法知识。数据集内容丰富,涵盖了俄语中的形态学、句法学和语义学现象。创建过程中,数据集从多个领域的开放文本语料库中提取句子,并使用先进的形态句法解析器进行标注,通过专家编写的扰动规则生成最小对齐。RuBLiMP主要应用于语言模型的语法能力评估,旨在解决现有资源在语言多样性和特定语法现象覆盖上的不足。
RuBLiMP is a Russian linguistic minimal pair benchmark dataset developed by the University of Edinburgh and other institutions, containing 45,000 sentence pairs and specifically designed to evaluate the grammatical knowledge of language models. It covers a wide range of morphological, syntactic and semantic phenomena in Russian. During its creation, sentences were extracted from open text corpora across multiple domains, annotated using advanced morphosyntactic parsers, and minimal pairs were generated via expert-written perturbation rules. RuBLiMP is primarily applied to evaluating the grammatical competence of language models, aiming to address the shortcomings of existing resources in terms of linguistic diversity and coverage of specific grammatical phenomena.
提供机构:
爱丁堡大学, 国立高等经济学院, 格罗宁根大学, 根特大学, Toloka AI, 奥斯陆大学
创建时间:
2024-06-27
原始信息汇总
数据集概述
基本信息
- 许可证: Apache 2.0
- 语言: 俄语
- 标签: benchmark
- 任务类型: acceptability-classification
- 数据集名称: RuBLiMP
- 数据规模: 10K<n<100K
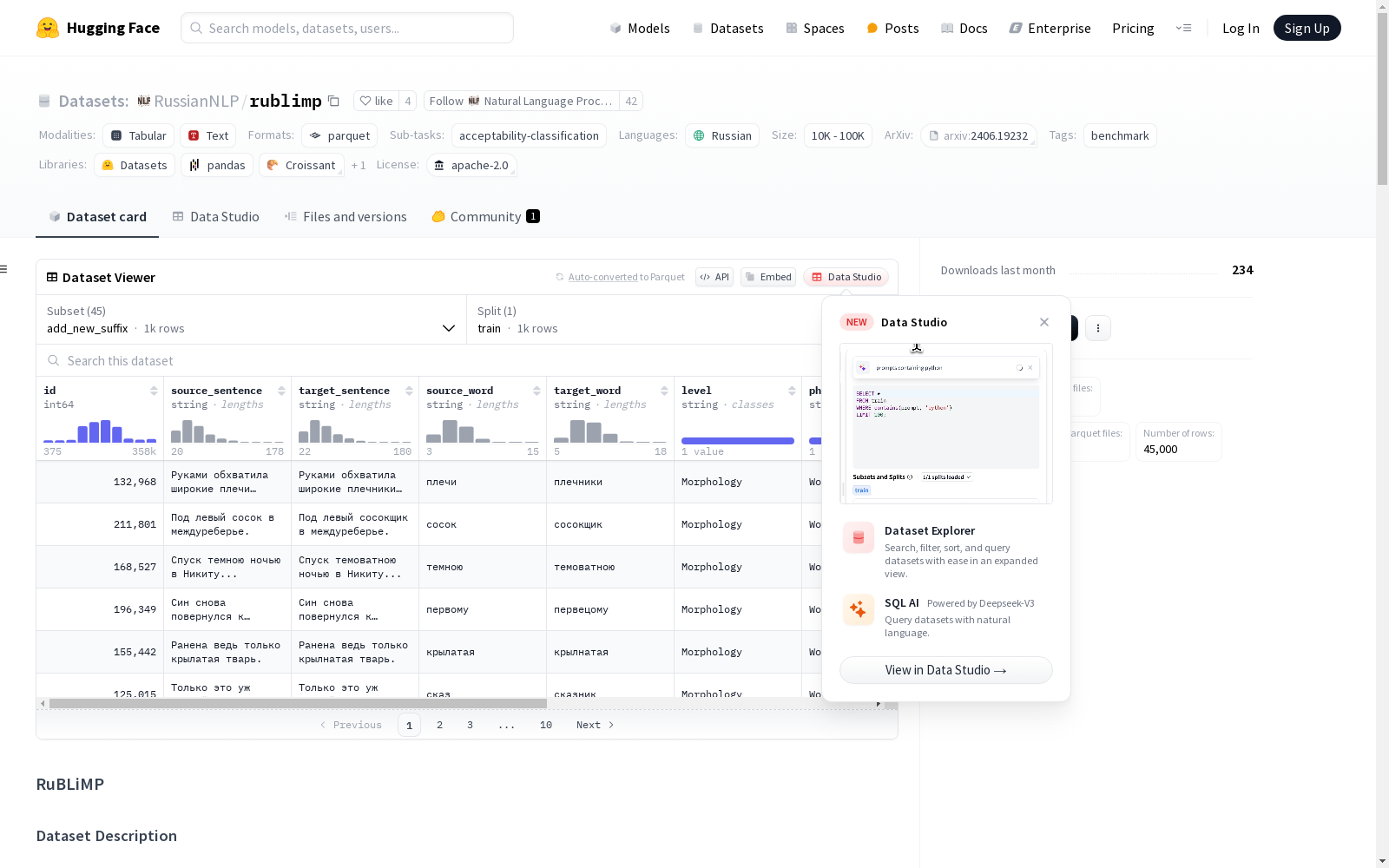
数据集配置
配置名称: add_new_suffix
- 特征:
- id: int64
- source_sentence: string
- target_sentence: string
- source_word: string
- target_word: string
- level: string
- phenomenon: string
- PID: string
- subtype: string
- domain: string
- tree_depth: int64
- 分割:
- train:
- 字节数: 349051
- 样本数: 1000
- train:
- 下载大小: 153218
- 数据集大小: 349051
配置名称: add_verb_prefix
- 特征:
- id: int64
- source_sentence: string
- target_sentence: string
- source_word: string
- target_word: string
- level: string
- phenomenon: string
- PID: string
- subtype: string
- domain: string
- tree_depth: int64
- 分割:
- train:
- 字节数: 325796
- 样本数: 1000
- train:
- 下载大小: 139990
- 数据集大小: 325796
配置名称: adposition_government
- 特征:
- id: int64
- source_sentence: string
- target_sentence: string
- source_word: string
- target_word: string
- level: string
- phenomenon: string
- PID: string
- subtype: string
- domain: string
- tree_depth: int64
- 分割:
- train:
- 字节数: 333926
- 样本数: 1000
- train:
- 下载大小: 146114
- 数据集大小: 333926
配置名称: anaphor_agreement_gender
- 特征:
- id: int64
- source_sentence: string
- target_sentence: string
- source_word: string
- target_word: string
- level: string
- phenomenon: string
- PID: string
- subtype: string
- domain: string
- tree_depth: int64
- 分割:
- train:
- 字节数: 497512
- 样本数: 1000
- train:
- 下载大小: 205655
- 数据集大小: 497512
配置名称: anaphor_agreement_number
- 特征:
- id: int64
- source_sentence: string
- target_sentence: string
- source_word: string
- target_word: string
- level: string
- phenomenon: string
- PID: string
- subtype: string
- domain: string
- tree_depth: int64
- 分割:
- train:
- 字节数: 502871
- 样本数: 1000
- train:
- 下载大小: 222157
- 数据集大小: 502871
配置名称: change_declension_ending
- 特征:
- id: int64
- source_sentence: string
- target_sentence: string
- source_word: string
- target_word: string
- level: string
- phenomenon: string
- PID: string
- subtype: string
- domain: string
- tree_depth: int64
- 分割:
- train:
- 字节数: 350376
- 样本数: 1000
- train:
- 下载大小: 148612
- 数据集大小: 350376
配置名称: change_declension_ending_has_dep
- 特征:
- id: int64
- source_sentence: string
- target_sentence: string
- source_word: string
- target_word: string
- level: string
- phenomenon: string
- PID: string
- subtype: string
- domain: string
- tree_depth: int64
- 分割:
- train:
- 字节数: 400435
- 样本数: 1000
- train:
- 下载大小: 164951
- 数据集大小: 400435
配置名称: change_duration_aspect
- 特征:
- id: int64
- source_sentence: string
- target_sentence: string
- source_word: string
- target_word: string
- level: string
- phenomenon: string
- PID: string
- subtype: string
- domain: string
- tree_depth: int64
- 分割:
- train:
- 字节数: 355088
- 样本数: 1000
- train:
- 下载大小: 134065
- 数据集大小: 355088
配置名称: change_repetition_aspect
- 特征:
- id: int64
- source_sentence: string
- target_sentence: string
- source_word: string
- target_word: string
- level: string
- phenomenon: string
- PID: string
- subtype: string
- domain: string
- tree_depth: int64
- 分割:
- train:
- 字节数: 434479
- 样本数: 1000
- train:
- 下载大小: 178290
- 数据集大小: 434479
配置名称: change_verb_conjugation
- 特征:
- id: int64
- source_sentence: string
- target_sentence: string
- source_word: string
- target_word: string
- level: string
- phenomenon: string
- PID: string
- subtype: string
- domain: string
- tree_depth: int64
- 分割:
- train:
- 字节数: 331430
- 样本数: 1000
- train:
- 下载大小: 131965
- 数据集大小: 331430
配置名称: change_verb_prefixes_order
- 特征:
- id: int64
- source_sentence: string
- target_sentence: string
- source_word: string
- target_word: string
- level: string
- phenomenon: string
- PID: string
- subtype: string
- domain: string
- tree_depth: int64
- 分割:
- train:
- 字节数: 486936
- 样本数: 1000
- train:
- 下载大小: 193967
- 数据集大小: 486936
配置名称: clause_subj_predicate_agreement_gender
- 特征:
- id: int64
- source_sentence: string
- target_sentence: string
- source_word: string
- target_word: string
- level: string
- phenomenon: string
- PID: string
- subtype: string
- domain: string
- tree_depth: int64
- 分割:
- train:
- 字节数: 382513
- 样本数: 1000
- train:
- 下载大小: 123034
- 数据集大小: 382513
配置名称: clause_subj_predicate_agreement_number
- 特征:
- id: int64
- source_sentence: string
- target_sentence: string
- source_word: string
- target_word: string
- level: string
- phenomenon: string
- PID: string
- subtype: string
- domain: string
- tree_depth: int64
- 分割:
- train:
- 字节数: 382153
- 样本数: 1000
- train:
- 下载大小: 122369
- 数据集大小: 382153
配置名称: clause_subj_predicate_agreement_person
- 特征:
- id: int64
- source_sentence: string
- target_sentence: string
- source_word: string
- target_word: string
- level: string
- phenomenon: string
- PID: string
- subtype: string
- domain: string
- tree_depth: int64
- 分割:
- train:
- 字节数: 406739
- 样本数: 1000
- train:
- 下载大小: 133132
- 数据集大小: 406739
配置名称: conj_verb_tense
- 特征:
- id: int64
- source_sentence: string
- target_sentence: string
- source_word: string
- target_word: string
- level: string
- phenomenon: string
- PID: string
- subtype: string
- domain: string
- tree_depth: int64
- 分割:
- train:
- 字节数: 464440
- 样本数: 1000
- train:
- 下载大小: 199995
- 数据集大小: 464440
配置名称: deontic_imperative_aspect
- 特征:
- id: int64
- source_sentence: string
- target_sentence: string
- source_word: string
- target_word: string
- level: string
- phenomenon: string
- PID: string
- subtype: string
- domain: string
- tree_depth: int64
- 分割:
- train:
- 字节数: 369950
- 样本数: 1000
- train:
- 下载大小: 140645
- 数据集大小: 369950
配置名称: external_possessor
- 特征:
- id: int64
- source_sentence: string
- target_sentence: string
- source_word: string
- target_word: string
- level: string
- phenomenon: string
- PID: string
- subtype: string
- domain: string
- tree_depth: int64
- 分割:
- train:
- 字节数: 304621
- 样本数: 1000
- train:
- 下载大小: 116558
- 数据集大小: 304621
配置名称: floating_quantifier_agreement_case
- 特征:
- id: int64
- source_sentence: string
- target_sentence: string
- source_word: string
- target_word: string
- level: string
- phenomenon: string
- PID: string
- subtype: string
- domain: string
- tree_depth: int64
- 分割:
- train:
- 字节数: 345416
- 样本数: 1000
- train:
- 下载大小: 113129
- 数据集大小: 345416
配置名称: floating_quantifier_agreement_gender
- 特征:
- id: int64
- source_sentence: string
- target_sentence: string
- source_word: string
- target_word: string
- level: string
- phenomenon: string
- PID: string
- subtype: string
- domain: string
- tree_depth: int64
- 分割:
- train:
- 字节数: 362382
- 样本数: 1000
- train:
- 下载大小: 121666
- 数据集大小: 362382
配置名称: floating_quantifier_agreement_number
- 特征:
- id: int64
- source_sentence: string
- target_sentence: string
- source_word: string
- target_word: string
- level: string
- phenomenon: string
- PID: string
- subtype: string
- domain: string
- tree_depth: int64
- 分割:
- train:
- 字节数: 423319
- 样本数: 1000
- train:
- 下载大小: 162506
- 数据集大小: 423319
配置名称: genitive_subj_predicate_agreement_gender
- 特征:
- id: int64
- source_sentence: string
- target_sentence: string
- source_word: string
- target_word: string
- level: string
- phenomenon: string
- PID: string
- subtype: string
- domain: string
- tree_depth: int64
- 分割:
- train:
- 字节数: 368978
- 样本数: 1000
- train:
- 下载大小: 115023
- 数据集大小: 368978
配置名称: genitive_subj_predicate_agreement_number
- 特征:
- id: int64
- source_sentence: string
- target_sentence: string
- source_word: string
- target_word: string
- level: string
- phenomenon: string
- PID: string
- subtype: string
- domain: string
- tree_depth: int64
- 分割:
- train:
- 字节数: 389125
- 样本数: 1000
- train:
- 下载大小: 125194
- 数据集大小: 389125
配置名称: genitive_subj_predicate_agreement_person
- 特征:
- id: int64
- source_sentence: string
- target_sentence: string
- source_word: string
- target_word: string
- level: string
- phenomenon: string
- PID: string
- subtype: string
- domain: string
- tree_depth: int64
- 分割:
- train:
- 字节数: 398814
- 样本数: 1000
- train:
- 下载大小: 127526
- 数据集大小: 398814
配置名称: indefinite_pronoun_to_negative
- 特征:
- id: int64
- source_sentence: string
- target_sentence: string
- source_word: string
- target_word: string
- level: string
- phenomenon: string
- PID: string
- subtype: string
- domain: string
- tree_depth: int64
- 分割:
- train:
- 字节数: 384859
- 样本数: 1000
- train:
- 下载大小: 151220
- 数据集大小: 384859
配置名称: negative_concord
- 特征:
- id: int64
- source_sentence: string
- target_sentence: string
- source_word: string
- target_word: string
- level: string
- phenomenon: string
- PID: string
- subtype: string
- domain: string
搜集汇总
数据集介绍
构建方式
RuBLiMP 数据集的构建采用了从开放文本语料库中自动标注的句子,通过应用语言扰动规则生成最小对,并经过数据净化处理,确保测试数据不受训练数据污染。具体而言,该数据集从维基百科、维基新闻和俄语数字书籍等公开文本语料库中提取句子,使用多领域形态句法解析器对句子进行标注,然后根据专家编写的规则对标注后的句子进行扰动,生成包含45k对句子的最小对数据集。
特点
RuBLiMP 数据集的特点在于其多样性、规模和针对性。它涵盖了45种最小对类型,每种类型包含1k对句子,涵盖了形态、句法和语义方面的12种语言现象。此外,RuBLiMP 的构建过程中采用了数据净化方法,确保测试数据不受训练数据污染,从而提高了数据集的质量和可靠性。
使用方法
RuBLiMP 数据集的使用方法包括对语言模型进行评估、开发可接受性分类器以及进行自然语言处理研究。通过对语言模型在 RuBLiMP 上的表现进行评估,可以了解模型对俄语语法知识的掌握程度。同时,RuBLiMP 还可以作为可接受性分类器的训练数据,以提高生成文本的质量。此外,研究人员还可以利用 RuBLiMP 进行自然语言处理研究,例如探索语言模型的语法知识和语言现象的识别能力。
背景与挑战
背景概述
语言模型在处理不同语言时,对其语法知识的评估是一个关键问题。目前,尽管已经有一些针对最小对偶句的数据集,但它们通常只覆盖有限的语言,并且缺乏对特定语言语法现象的多样性。为了填补这一空白,Ekaterina Taktasheva等人创建了RuBLiMP,这是一个包含45k对句子的数据集,这些句子在语法性和形态、句法或语义现象方面有所不同。RuBLiMP通过将语言学扰动应用于自动注释的开放文本语料库中的句子,并去除测试数据中的污染,从而生成最小对偶句。该数据集旨在评估语言模型对俄语语法现象的理解程度,并揭示现有模型在处理俄语时的优势和劣势。
当前挑战
RuBLiMP面临的挑战包括:1)解决领域问题的挑战,即评估语言模型对俄语语法现象的理解程度,这需要对俄语的形态、句法和语义有深入的了解;2)构建过程中的挑战,例如,确保最小对偶句能够清晰地区分目标现象,并且不受语料库污染的影响。此外,RuBLiMP还需要考虑模型大小、现象、领域和长度等因素对模型性能的影响,并与其他语言的数据集进行比较,以揭示跨语言的模型能力。
常用场景
经典使用场景
RuBLiMP数据集主要用于评估语言模型对俄罗斯语语法知识的掌握程度。该数据集包含了45k对句子,这些句子在语法正确性上存在差异,并单独隔离了形态、句法或语义现象。通过对比语言模型对语法正确句子和不正确句子的概率分配,可以评估模型对特定语言现象的敏感性。
实际应用
RuBLiMP数据集的实际应用场景包括语言模型的开发和评估。通过在RuBLiMP上评估语言模型,研究者可以了解模型在不同语法现象上的表现,从而指导模型的设计和改进。此外,RuBLiMP还可以用于开发可接受性分类器,以提高文本生成的质量。
衍生相关工作
RuBLiMP数据集的发布推动了俄罗斯语自然语言处理领域的研究。它为研究语言模型对俄罗斯语语法知识的掌握程度提供了一个标准化的评估工具。此外,RuBLiMP的生成方法和去污技术也为其他语言的最小对基准的创建提供了参考。
以上内容由遇见数据集搜集并总结生成


