connections-dev/connection_queries_jan12_natural_original_1_reason_high_0.7_31000_gpt-oss-120b
收藏Hugging Face2026-05-02 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/connections-dev/connection_queries_jan12_natural_original_1_reason_high_0.7_31000_gpt-oss-120b
下载链接
链接失效反馈官方服务:
资源简介:
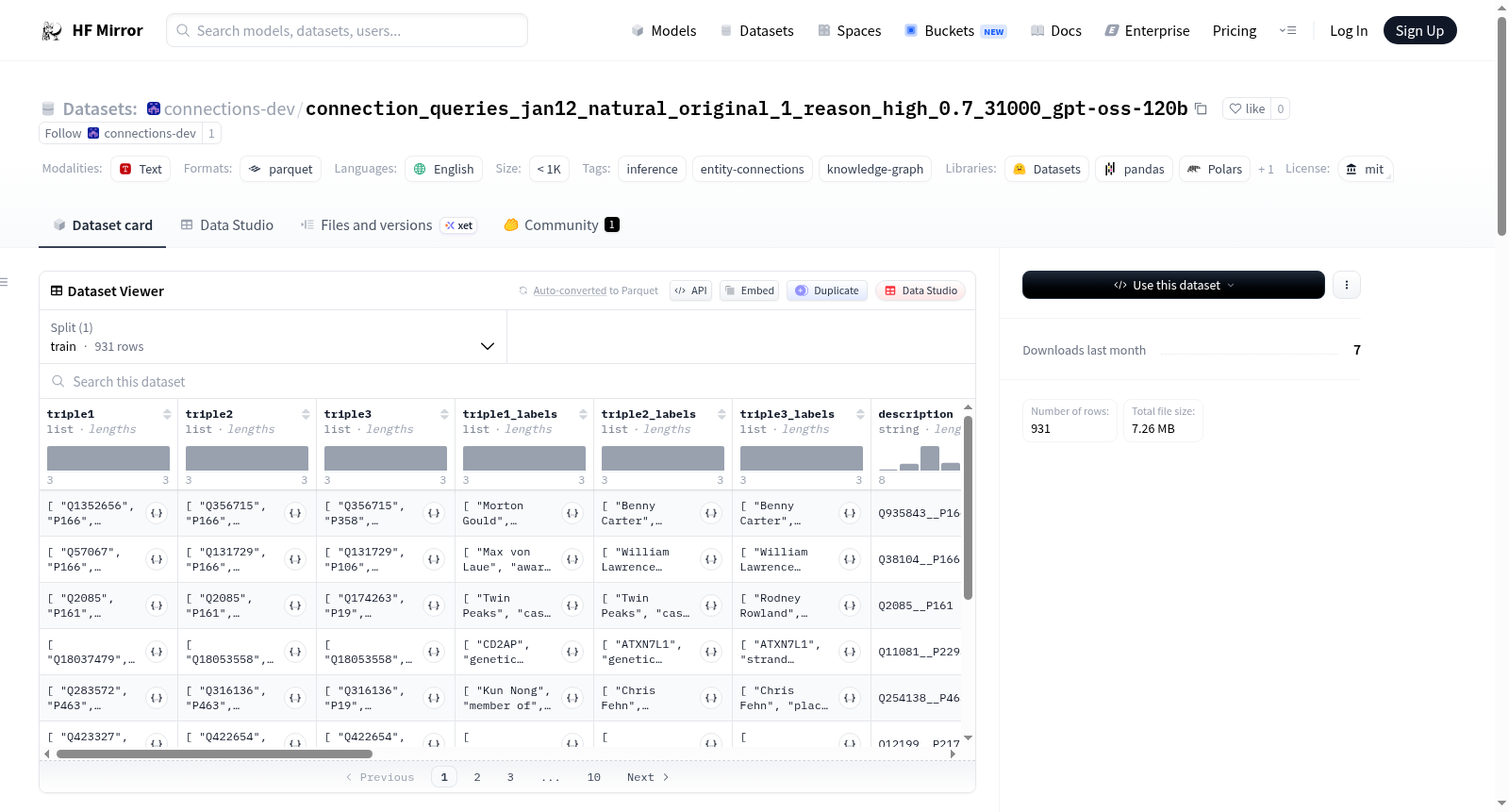
该数据集名为connections-dev/connection_queries_jan12,是通过推理脚本生成的实体连接查询数据集。数据集包含931个样本,主要列包括原始查询(query)、起始实体(entity_a)、目标实体(entity_b)、目标关系(rel_b)、生成的连接路径(path_prediction)和用于路径生成的提示(prompt_for_path)。数据集生成时使用了openai/gpt-oss-120b模型,配置了自然查询类型、0.7的温度参数和31000的最大token数等参数。该数据集主要用于知识图谱中的实体连接推理任务。
The dataset named connections-dev/connection_queries_jan12 is an entity connection query dataset generated using an inference script. It contains 931 samples with key columns including original query, starting entity (entity_a), target entity (entity_b), target relationship (rel_b), generated connection paths (path_prediction), and prompts used for path generation (prompt_for_path). The dataset was generated using the openai/gpt-oss-120b model with configuration parameters such as natural query type, temperature of 0.7, and max tokens of 31000. This dataset is primarily used for entity connection inference tasks in knowledge graphs.
提供机构:
connections-dev
搜集汇总
数据集介绍
构建方式
该数据集基于推理流水线生成,采用OpenAI的GPT-OSS-120B模型作为核心引擎,以自然语言查询为输入,通过实体连接与知识图谱技术构建。生成过程中设定温度为0.7以平衡创造性与确定性,最大生成长度达31000个token,采样类型为原始采样,推理能力设置为高,旨在从931个样本中抽取实体对之间的路径预测。数据集存储为JSONL格式,包含原始查询、起始实体、目标实体、目标关系以及生成的连接路径与提示词字段。
特点
该数据集专注于实体连接推理任务,特色在于结合大规模语言模型与知识图谱,通过高推理强度生成复杂的连接路径。温度参数0.7确保了路径的多样性与合理性,而31000个token的生成容量支持对深度关联的探索,原始采样方式保留了数据的初始分布特性。数据集结构清晰,包含明确的查询、实体和关系字段,便于进行知识推理与路径分析研究。
使用方法
用户可通过HuggingFace Datasets库直接加载数据集,使用简单的Python代码`load_dataset`即可获取数据,其中包含query、entity_a、entity_b、rel_b、path_prediction和prompt_for_path等关键列。数据集适合用于训练实体链接模型、评估知识图谱推理能力或作为事实验证任务的基准。加载后可按需过滤或转换字段,以适配不同的下游应用如问答系统或关系抽取。
背景与挑战
背景概述
在知识图谱与图推理领域,实体间复杂关联路径的自动发现是推动智能问答、推荐系统与语义搜索发展的核心挑战之一。connection_queries_jan12_natural_original_1_reason_high_0.7_31000_gpt-oss-120b数据集由connections-dev团队于2026年5月创建,采用OpenAI的GPT-OSS-120B大语言模型进行推理生成,旨在探索自然查询下实体间连接路径的预测能力。该数据集包含931个样本,每个样本记录起始实体、目标实体及其关系路径,为知识图谱中多跳推理与路径生成研究提供了高质量基准。其发布不仅推动了图神经网络与语言模型在实体连接任务中的融合应用,也促使研究者重新审视大规模语言模型在结构化知识推理中的潜力与局限。
当前挑战
数据集面临的首要挑战是解决知识图谱中长距离实体连接路径的准确性与多样性问题——现有方法常受限于稀疏连接或路径冗余,难以捕捉复杂语义关系;同时,在构建过程中,数据生成依赖大语言模型的推理输出,但高温采样(temperature=0.7)虽提升路径多样性,却可能引入逻辑不一致或未经验证的虚假连接。此外,单次生成流程(runs=1)无法充分覆盖多跳路径的完备性,且缺乏人工审核(no curator=True),使得路径质量高度依赖模型自身能力。跨实体类型的路径对齐与关系类型注释的精确性,则进一步加剧了数据构建的复杂性,为后续应用中的可信推理与泛化能力带来潜在风险。
常用场景
经典使用场景
在知识图谱与自然语言处理的交叉领域,该数据集为实体关系推理任务提供了精心设计的基准。其经典使用场景在于评估和增强模型在给定起始实体与目标实体之间发现潜在连接路径的能力。通过引入自然语言形式的查询,研究者能够检验大规模语言模型在进行复杂、多跳推理时的表现,尤其是在面对高难度样本时,模型如何利用链式思维机制逐步挖掘实体间的语义关联。这一过程不仅考验模型对结构化知识的理解,也对其在长篇文本中保持推理连贯性的能力提出了严苛要求。
衍生相关工作
围绕该数据集,衍生出一系列颇具影响力的研究工作。在模型训练层面,有工作引入强化学习与蒙特卡洛树搜索,优化路径生成的质量与多样性,避免模型陷入语义循环。在评估方法上,研究者提出了基于图编辑距离与语义一致性的双重评分机制,更全面地衡量推理路径的合理性。另一方向关注模型校准,即通过对比生成路径与知识库中结构化路径的偏差,量化模型内部表示与外部知识的一致性。这些工作共同推动了开放域推理系统从实验走向实用化部署的进程。
数据集最近研究
最新研究方向
在知识图谱与实体关系推理的前沿领域,该数据集通过大规模语言模型(如GPT-OSS-120B)的推理能力,聚焦于自然语言查询中实体间复杂路径的自动生成。其核心贡献在于模拟多跳推理过程,探索从起始实体到目标实体的潜在语义连接,为知识增强型问答、常识推理及图神经网络训练提供了高质量的标注样本。当前研究热点在于利用此类数据驱动的大模型推理链路,以突破传统规则或浅层嵌入方法的局限,推动实体关系抽取向动态、可解释的隐性知识挖掘演进,从而显著提升智能系统在生物医学、金融风控等复杂关联场景下的因果推断与知识溯源能力。
以上内容由遇见数据集搜集并总结生成


