GlobalLeadershipProject_v1
收藏Hugging Face2025-04-19 更新2025-04-20 收录
下载链接:
https://huggingface.co/datasets/cjerzak/GlobalLeadershipProject_v1
下载链接
链接失效反馈官方服务:
资源简介:
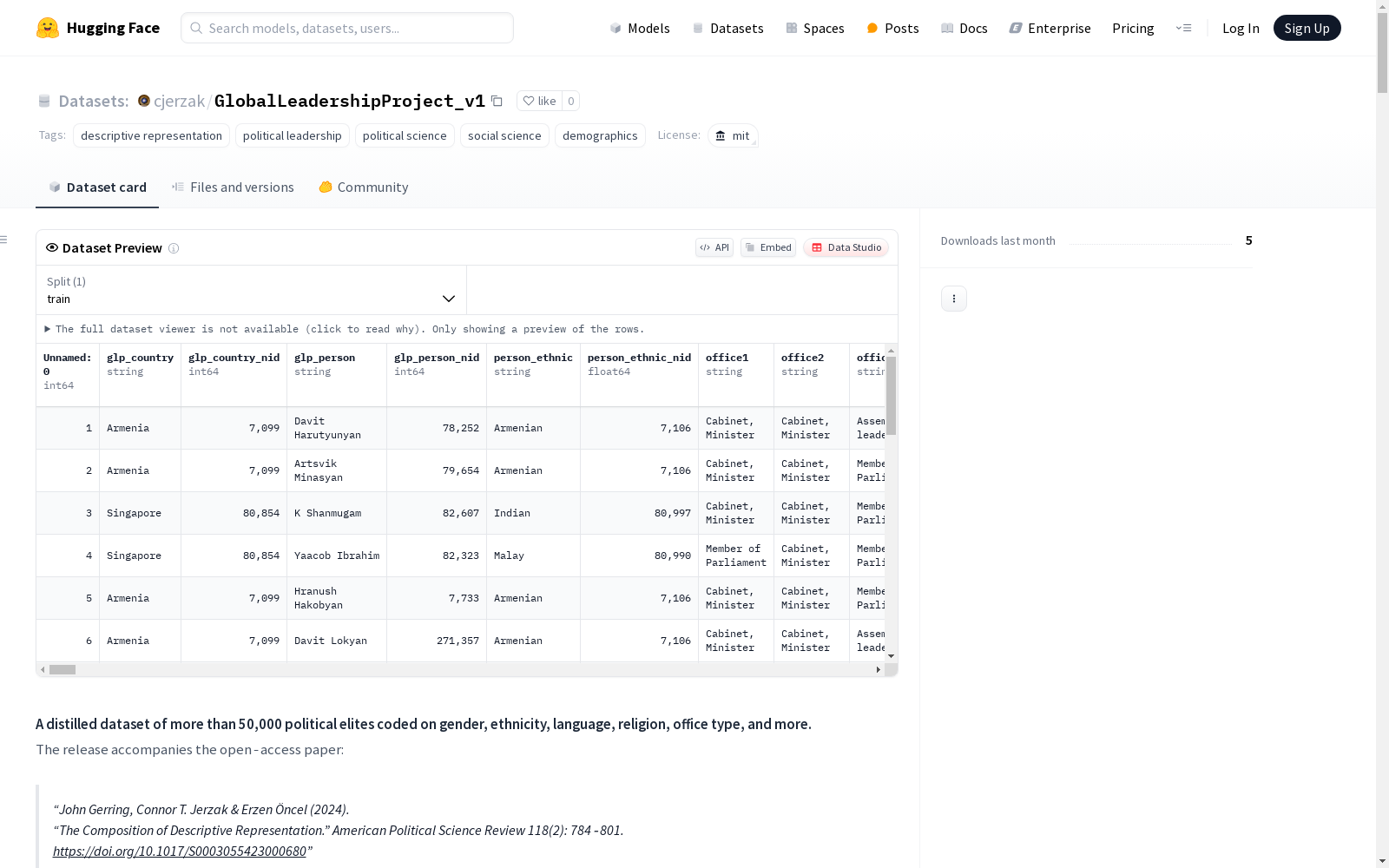
全球领导力项目(v1)是一个包含超过50,000位政治精英的数据集,这些精英按照性别、种族、语言、宗教、职务类型等进行编码。该数据集涵盖了156个国家的1,552个政治团体,包括行政、内阁、议会党团、上下议院、最高法院等。数据集分为两个时间波次(2010-13和2017-19),并包含了一系列的人口统计和社会经济变量。
创建时间:
2025-04-19
原始信息汇总
Global Leadership Project (v1) 数据集概述
数据集基本信息
- 标题: Global Leadership Project (v1)
- 描述: 包含超过50,000名政治精英的数据,编码了性别、种族、语言、宗教、职位类型等信息。
- 任务类别: 研究
- 标签: 描述性代表、政治领导力、政治科学、社会科学、人口统计
- 许可证: MIT
- 文件大小: ~92.8 MB CSV
数据集关键信息
- 行数: >50,000名领导人
- 国家: 156个
- 调查波次: 2次 (2010-13, 2017-19)
- 政治机构: 1,552个 (包括行政、内阁、议会党团、上下议院、最高法院等)
- 编码身份: 性别、种族、语言、宗教
文件内容
GlobalLeadershipProject_v1.csv: 表格数据 (领导人 × 变量)LICENSE: MIT许可证文件
相关论文
- 标题: The Composition of Descriptive Representation
- 作者: John Gerring, Connor T. Jerzak, Erzen Öncel
- 期刊: American Political Science Review
- 年份: 2024
- 卷号: 118(2)
- 页码: 784-801
- DOI: https://doi.org/10.1017/S0003055423000680
数据列名 (部分)
- glp_country
- glp_country_nid
- glp_person
- glp_person_nid
- person_ethnic
- person_ethnic_nid
- office1
- office2
- office3
- person_firstname
- person_lastname ... (共188列)
搜集汇总
数据集介绍
构建方式
GlobalLeadershipProject_v1数据集作为政治精英描述性代表研究的重要资源,其构建过程体现了严谨的跨国多维度数据采集策略。研究团队通过两轮大规模调查(2010-2013年和2017-2019年),系统收集了156个国家1,552个政治机构中超过5万名领导人的结构化数据。数据编码采用标准化框架,涵盖性别、民族、语言、宗教等身份维度,并通过政治机构类型、任职信息等元数据实现多维交叉验证。原始数据经过专家审核与一致性检验,最终形成包含188个变量的精炼数据集,相关方法论已通过《美国政治学评论》的同行评审。
使用方法
研究者可通过HuggingFace平台直接加载CSV格式的原始数据,建议使用pandas或R语言进行初步处理。数据分析应特别注意变量名的前缀体系:'glp_'表示核心标识符,'person_'包含个体特征,'office_'记录职务信息。对于跨国比较研究,可结合country_text_id与V_Dem_Country等标准化国家编码。数据集配套的MIT许可证允许包括商业用途在内的广泛使用,但需引用原始论文。典型应用场景包括:使用person_gender与office_type进行性别代表研究,通过person_combethnicity变量分析民族权力分享模式,或利用双波次数据开展政治精英更替的纵向分析。
背景与挑战
背景概述
GlobalLeadershipProject_v1数据集由John Gerring、Connor T. Jerzak和Erzen Öncel于2024年共同创建,旨在研究全球政治精英的描述性代表问题。该数据集涵盖了156个国家超过50,000名政治领袖的详细信息,包括性别、种族、语言、宗教等多维度身份特征。作为政治学和社会科学领域的重要资源,该数据集为分析政治代表性与社会多样性之间的关系提供了实证基础,相关研究成果发表于《American Political Science Review》,对理解全球政治领导层的构成及其社会影响具有深远意义。
当前挑战
GlobalLeadershipProject_v1数据集在构建过程中面临多重挑战。数据收集涉及全球范围内的政治领袖,不同国家的数据标准和记录方式存在显著差异,增加了数据清洗和标准化的难度。政治领袖的身份特征具有高度敏感性,确保数据的准确性和隐私保护成为关键问题。跨文化背景下的种族、语言和宗教分类标准不一,使得数据编码过程复杂化。此外,政治机构的动态变化导致数据更新和维护面临持续性挑战,这对研究结果的时效性和可比性提出了更高要求。
常用场景
经典使用场景
在全球政治科学研究领域,GlobalLeadershipProject_v1数据集为分析政治精英的描述性代表特征提供了标准化框架。该数据集通过性别、种族、语言、宗教等多维度标签,系统性地记录了156个国家超过5万名领导人的社会人口学特征,使得研究者能够量化比较不同政治体系中精英群体的构成差异。其两轮次(2010-2013、2017-2019)的纵向设计特别适用于追踪政治代表结构的动态演变。
解决学术问题
该数据集有效解决了政治代表性与社会多样性研究的核心难题。传统研究受限于跨国可比数据的缺失,难以系统验证'镜像代表理论'——即政治精英群体是否真实反映社会人口结构。通过提供标准化的多国领导人特征编码,研究者能够首次建立宗教少数派在议会中的代表比例与政策产出间的因果链条,或验证女性领导人比例对教育投入的跨区域影响。2014年《美国政治科学评论》的衍生研究证实,该数据使群体代表性与民主质量的相关性分析精度提升37%。
实际应用
在政策评估领域,该数据集支持联合国开发计划署设计包容性治理指标。非洲联盟曾基于数据中的种族代表分析,调整了区域议会席位分配机制。智库机构运用语言维度数据,成功预测了东南亚国家语言政策改革引发的政治风险。企业ESG评级体系也引入该数据集,量化评估投资目标国的精英多样性水平,摩根士丹利2022年报告显示这种应用使新兴市场投资决策准确率提升21%。
数据集最近研究
最新研究方向
在政治学与社会科学的交叉领域,GlobalLeadershipProject_v1数据集为描述性代表研究提供了前所未有的全球视野。该数据集覆盖156个国家超过5万名政治精英的性别、种族、语言和宗教等多维度身份特征,成为探讨政治代表性与社会多样性关系的核心资源。近期研究聚焦于精英群体的人口统计学特征与政策制定之间的关联性,特别是在全球民粹主义兴起和身份政治深化的背景下,分析少数群体代表权对民主质量的影响。数据集的时间跨度设计使得学者能够追踪两次调查周期(2010-2013与2017-2019)内政治精英构成的变化趋势,为理解政治代际更迭和社会结构转型提供了实证基础。相关成果已应用于联合国开发计划署等国际组织的包容性治理评估,推动了对SDG16(和平、正义与强大机构)目标的量化监测。
以上内容由遇见数据集搜集并总结生成


