synthetic-distance
收藏synthetic-distance 数据集概述
数据集基本信息
- 数据集名称: synthetic-distance
- 发布者: Joel Currie 等
- 发布日期: 2025年
- 许可证: MIT
- 数据集大小: 762.43 MB
- 下载大小: 727.44 MB
- 访问地址: https://huggingface.co/datasets/jwgcurrie/synthetic-distance
- DOI: 10.57967/hf/5351
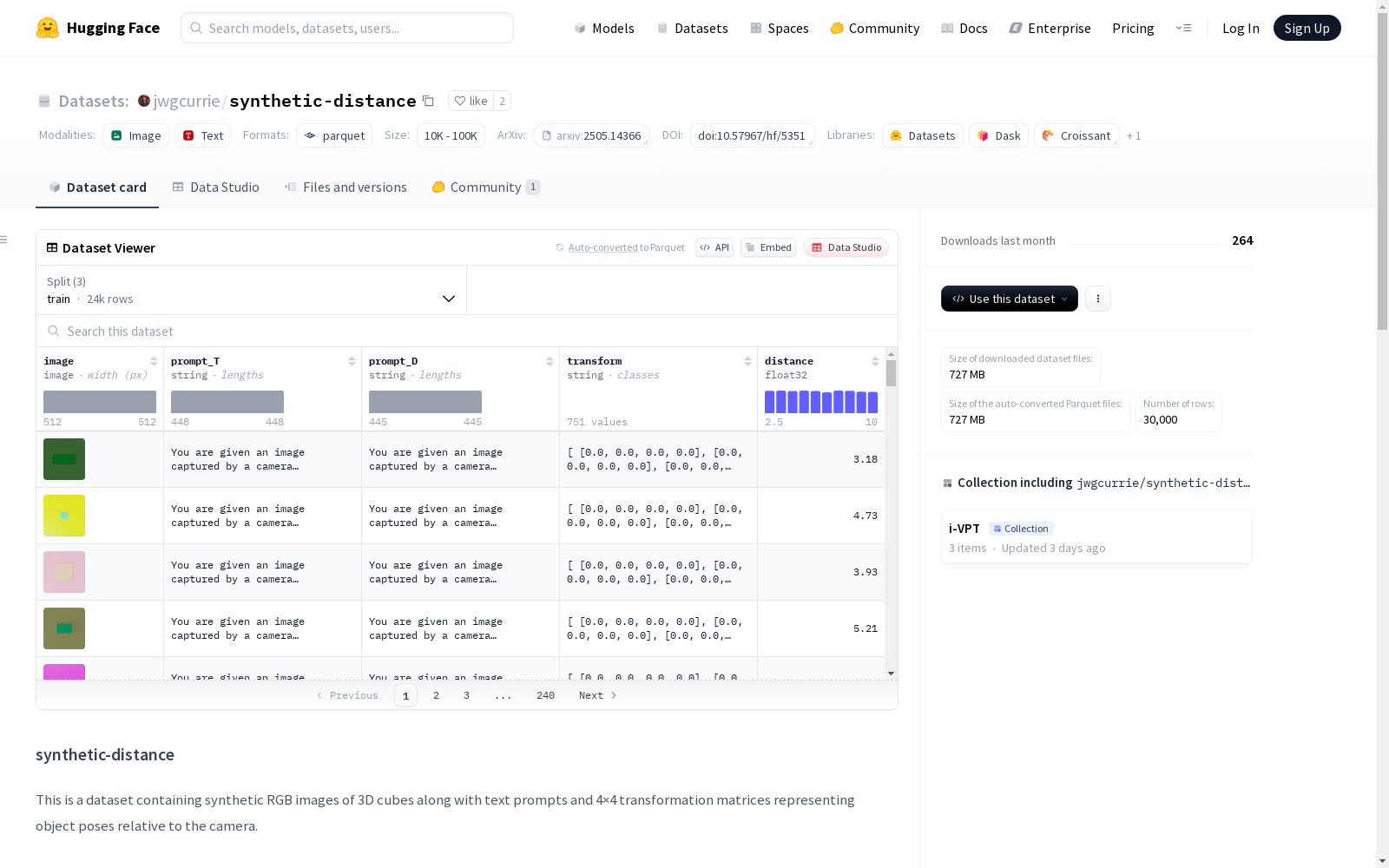
数据集内容
- 数据类型: 合成RGB图像及文本提示
- 主要内容: 包含3D立方体的合成RGB图像,以及描述物体及其尺寸的自然语言指令、4×4变换矩阵和相机与立方体中心的距离。
特征字段
- image: RGB图像(从相机视角渲染的3D物体图像)
- prompt_T: 描述物体及其尺寸的自然语言指令(字符串)
- prompt_D: 描述物体及其尺寸的自然语言指令(字符串)
- transform: 扁平化的4×4变换矩阵(16个值,字符串格式)
- distance: 相机与立方体中心之间的距离(float32)
数据划分
- train
- 样本数量: 24000
- 数据大小: 611.93 MB
- validation
- 样本数量: 4500
- 数据大小: 112.27 MB
- test
- 样本数量: 1500
- 数据大小: 38.23 MB
引用信息
论文引用
bibtex @misc{currie2025embodiedcognitionrobotsspatially, title={Towards Embodied Cognition in Robots via Spatially Grounded Synthetic Worlds}, author={Joel Currie and Gioele Migno and Enrico Piacenti and Maria Elena Giannaccini and Patric Bach and Davide De Tommaso and Agnieszka Wykowska}, year={2025}, eprint={2505.14366}, archivePrefix={arXiv}, primaryClass={cs.AI}, url={https://arxiv.org/abs/2505.14366}, }
数据集引用
bibtex @misc{joel_currie_2025, author = { Joel Currie and Gioele Migno and Enrico Piacenti and Maria Elena Giannaccini and Patric Bach and Davide De Tommaso and Agnieszka Wykowska }, title = { synthetic-distance (Revision c86eff8) }, year = 2025, url = { https://huggingface.co/datasets/jwgcurrie/synthetic-distance }, doi = { 10.57967/hf/5351 }, publisher = { Hugging Face } }
纯文本引用
Currie, J., Migno, G., Piacenti, E., Giannaccini, M. E., Bach, P., De Tommaso, D., & Wykowska, A. (2025). synthetic-distance (Revision c86eff8). Hugging Face. https://doi.org/10.57967/hf/5351