homebrew-research/instruction-speech-v1
收藏Hugging Face2024-07-09 更新2024-07-22 收录
下载链接:
https://hf-mirror.com/datasets/homebrew-research/instruction-speech-v1
下载链接
链接失效反馈官方服务:
资源简介:
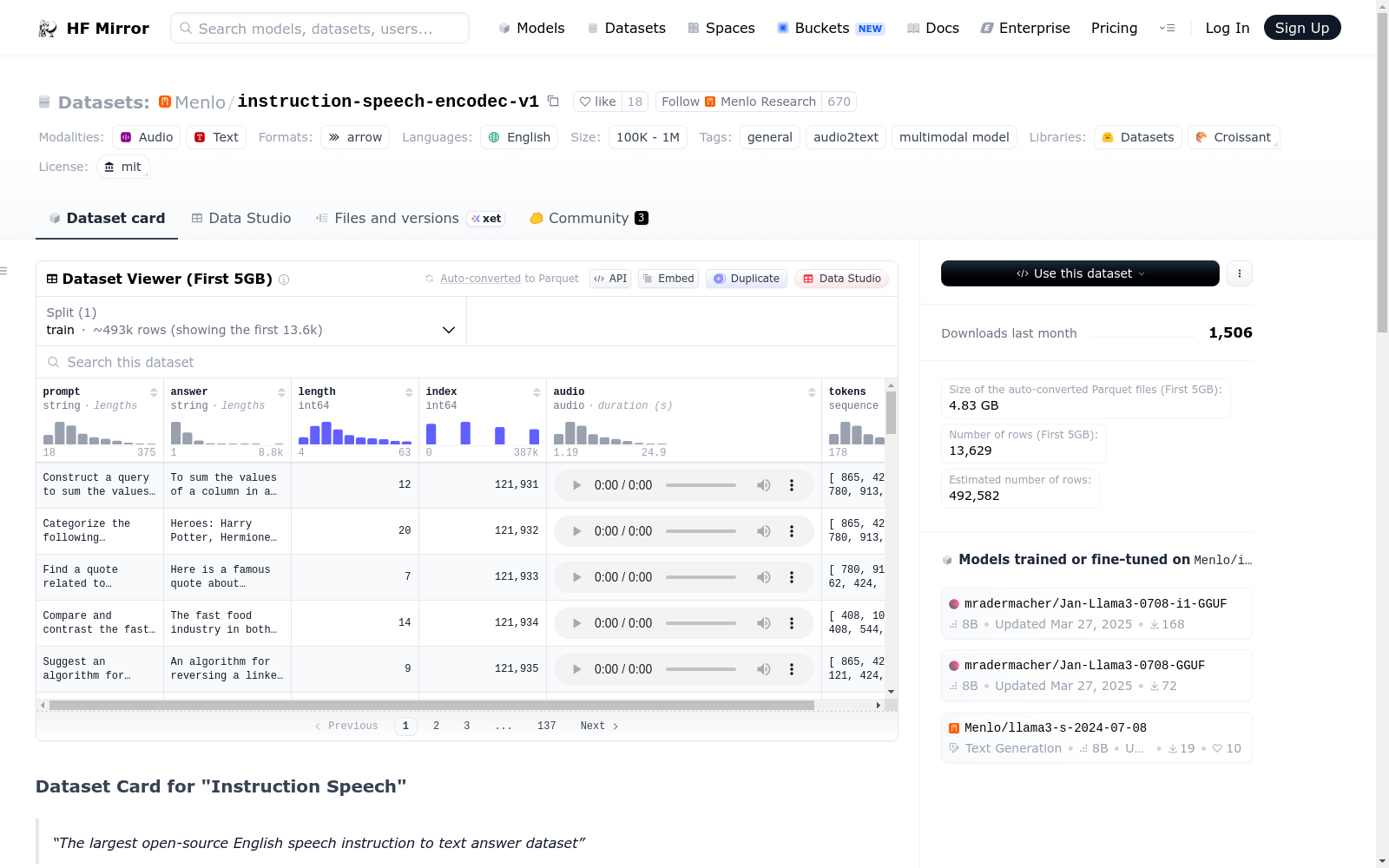
该数据集包含近450,000个英语语音指令到文本回答的样本,使用了OpenHermes 2.5的子集、WhisperSpeech生成的音频以及Encodec进行标记化。数据集字段包括用户的查询、助手的回答、查询的长度、音频文件以及使用Encodec标记化的序列。数据集可能存在源数据中的偏见,当前版本缺乏对提示和回答的质量控制,使用Encodec可能会影响声音标记的质量。数据集在MIT许可下发布。
The dataset is a large open-source English speech instruction to text answer dataset containing nearly 450,000 samples. It includes user queries, assistant answers, lengths of queries, audio files, and tokenized data using Encodec. The dataset is sourced from OpenHermes 2.5 and uses WhisperSpeech for audio generation. It is released under the MIT license and includes fields such as prompt, answer, length, audio, and tokens. The README also mentions potential biases, risks, and limitations, and provides citation information.
提供机构:
homebrew-research
原始信息汇总
数据集卡片:"Instruction Speech"
数据集概述
该数据集包含近450,000个英语的语音指令到文本回答样本,使用以下资源:
- 来自OpenHermes 2.5的子集,用户提示长度小于64。
- 使用WhisperSpeech生成音频。
- 使用Encodec进行标记化。
使用方法
python from datasets import load_dataset, Audio
加载Instruction Speech数据集
dataset = load_dataset("jan-hq/instruction-speech-v1",split=train)
数据集字段
| 字段 | 类型 | 描述 |
|---|---|---|
prompt |
string | 用户查询 |
answer |
string | 助手回答 |
length |
int | 用户查询的长度 |
audio |
audio | 音频文件 |
tokens |
sequence | 使用Encodec标记化 |
偏差、风险和限制
- 数据集可能反映其来源的固有偏差。
- 当前版本缺乏对提示和响应的质量控制。
- 使用Encodec可能会影响声音标记的质量。
- 用户在应用数据集时应考虑这些限制。
许可信息
该数据集在MIT许可证下发布。
引用信息
@article{Instruction Speech 2024, title={Instruction Speech}, author={JanAI}, year=2024, month=June}, url={https://huggingface.co/datasets/jan-hq/instruction-speech}
搜集汇总
数据集介绍
背景与挑战
背景概述
This dataset is a comprehensive open-source collection of English speech instruction to text answer pairs, featuring nearly 450,000 samples generated using WhisperSpeech and tokenized with Encodec. It supports tasks in speech-to-text conversion and multimodal learning, with fields including user prompts, assistant answers, audio files, and tokenized sequences.
以上内容由遇见数据集搜集并总结生成


