OAEI Machine Learning Dataset for Online Model Generation
收藏arXiv2024-04-29 更新2024-06-21 收录
下载链接:
https://dwslab.github.io/melt/track-repository#ml-based-tracks
下载链接
链接失效反馈官方服务:
资源简介:
OAEI Machine Learning Dataset for Online Model Generation是由卡尔斯鲁厄理工学院(AIFB)创建的数据集,旨在为Ontology Alignment Evaluation Initiative (OAEI)提供机器学习模型训练、验证和测试的标准数据。该数据集包含多个OAEI跟踪的训练、验证和测试集,支持在线模型学习,确保机器学习系统能适应输入对齐,实现公平比较。数据集通过精细的分层确保了训练和测试数据的质量,适用于解决知识图谱对齐中的复杂匹配问题。
OAEI Machine Learning Dataset for Online Model Generation is a dataset developed by the Karlsruhe Institute of Technology (AIFB). It is designed to provide standardized data for training, validating, and testing machine learning models for the Ontology Alignment Evaluation Initiative (OAEI). This dataset includes multiple training, validation, and test sets tracked by OAEI, supporting online model learning and ensuring that machine learning systems can adapt to input alignments for fair comparative evaluations. The dataset ensures the quality of training and test data through rigorous stratification, and is applicable to solving complex matching problems in knowledge graph alignment.
提供机构:
卡尔斯鲁厄理工学院(AIFB)
创建时间:
2024-04-29
搜集汇总
数据集介绍
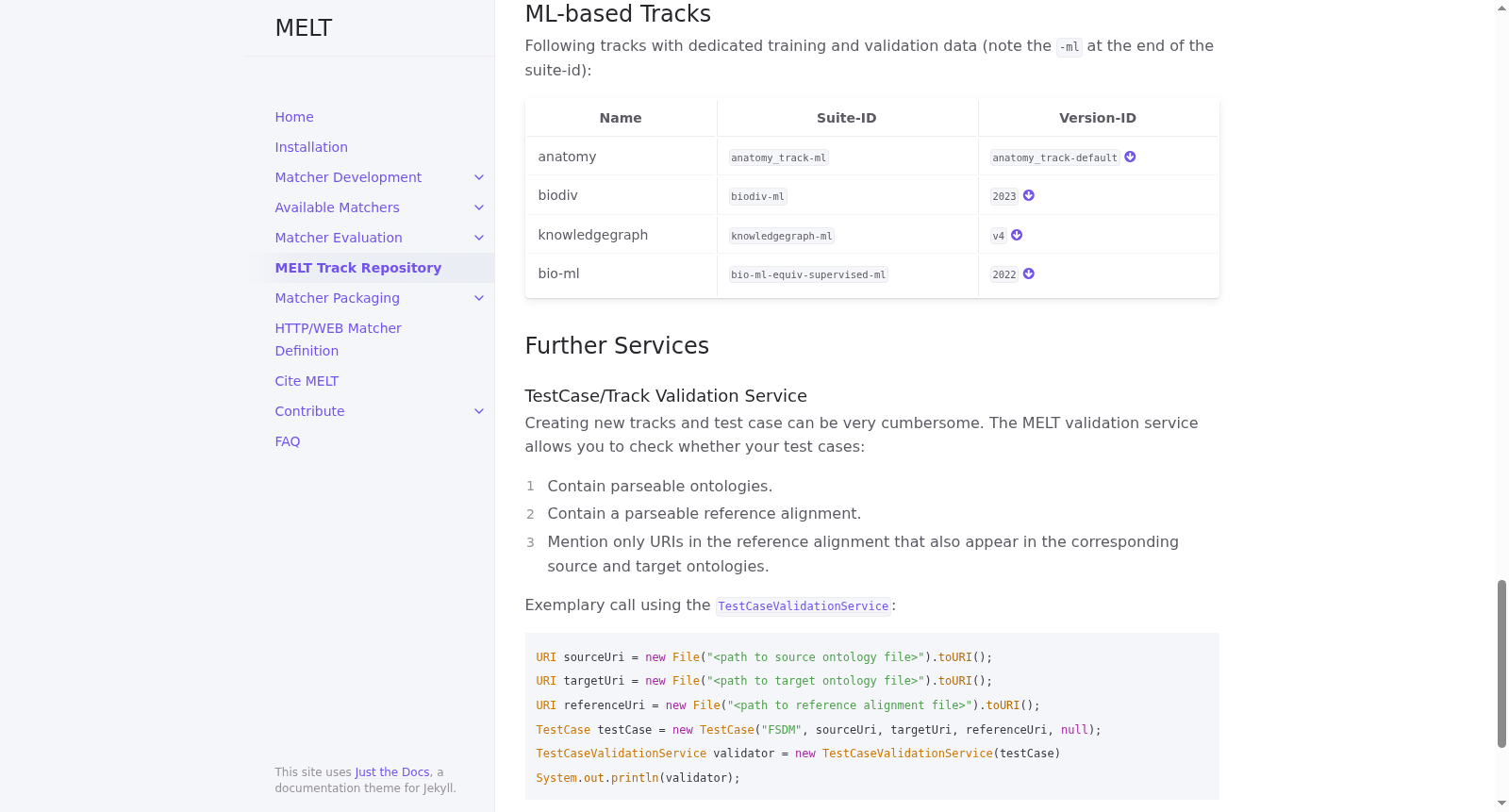
构建方式
该数据集基于本体对齐评估倡议(OAEI)的现有赛道构建,旨在为机器学习驱动的本体匹配系统提供标准化的训练、验证与测试划分。构建过程中,参考对齐被按照20%用于训练、10%用于验证、70%用于测试的比例进行分割,这一比例参考了He等人(2022)的研究,并考虑到真实场景中正例对应关系稀缺且标注成本高昂。为确保分割的合理性,数据集采用了分层抽样策略,依据实体类型(类、属性、实例)、关系类型以及映射难度(简单、中等、困难)三个维度对参考对齐进行分组。仅选择参考对齐中对应关系数量不少于350条的OAEI测试用例,最终涵盖解剖学、生物多样性、知识图谱和生物机器学习四个赛道。所有数据集均与MELT工具包深度集成,可通过赛道仓库下载,并附有生成与评估代码。
使用方法
使用者可通过MELT工具包轻松加载该数据集,并将其作为输入对齐提供给匹配系统。系统需利用训练和验证集在线调整参数,例如优化置信度阈值以过滤低置信度对应关系。论文展示了通过监督方法(部分监督和完全监督)调整阈值的用例,结果在多个赛道和匹配器上取得了性能提升,尤其在生物多样性赛道中,OLaLa系统的F1值提升了超过13%。开发者可参考GitHub上的示例代码进行数据集生成与评估,并鼓励仅在没有输入对齐的情况下回退至默认或预训练参数。
背景与挑战
背景概述
本体匹配与知识图谱对齐是语义网领域中的核心任务,旨在解决异构知识源之间的语义互操作性问题。自2004年起,本体对齐评估倡议(OAEI)每年组织匹配系统评测,为领域内方法提供公平比较平台。近年来,基于机器学习的方法逐渐成为主流,尤其是大型语言模型的引入显著提升了匹配性能。然而,传统做法中,系统开发者自行采样参考对齐的子集用于训练和验证,这不仅违反了OAEI的规则,也导致不同系统之间难以进行公正对比。为此,FIZ Karlsruhe的Sven Hertling、Ebrahim Norouzi与Harald Sack于2024年提出了OAEI机器学习数据集,旨在支持在线模型生成,即系统在执行过程中自适应地利用输入对齐进行参数调整,从而摆脱离线预训练模型的局限,推动本体匹配系统的可迁移性与公平评估。
当前挑战
该数据集所应对的核心挑战包括:其一,现有基于机器学习的匹配系统多采用离线训练模式,即开发者预先下载参考对齐、手动调优模型并打包成匹配器,这种方式使得系统难以泛化至未见数据集,违背了OAEI促进通用匹配系统发展的初衷。其二,构建过程中面临数据极度不平衡的问题——正确对应关系远少于错误对应关系,且真实场景中仅能提供少量正例作为训练信号。为此,研究团队仅选择参考对齐中至少包含350条对应关系的测试用例,并按实体类型、关系类型及匹配难度进行分层抽样,确保训练集(20%)、验证集(10%)与测试集(70%)中的分布与原对齐一致,同时不提供负例,而由系统在运行时自行生成难负例,以反映真实匹配过程中的分布特性。
常用场景
经典使用场景
在知识图谱与本体匹配领域,该数据集作为OAEI官方评测的标准化训练-验证-测试分割资源,为基于机器学习的在线模型生成提供了关键支撑。研究者可借助其分层抽样策略(依据实体类型、关系类型及匹配难度)构建公平可复现的对比实验,尤其适用于需要动态适应输入对齐的在线学习场景,例如通过微调置信度阈值优化匹配系统性能。
解决学术问题
该数据集直面本体匹配系统中机器学习模型训练数据不统一、离线训练导致泛化性不足的学术困境。通过提供固定分割比例(20%训练、10%验证、70%测试)与类别均衡的参考对齐,它消除了开发者自定义采样带来的评估偏差,使得系统间的公平比较成为可能。此举推动了在线模型生成范式的确立,即匹配器需在无人工干预下从给定输入对齐中自主学习,显著提升了方法在未知数据集上的迁移能力。
实际应用
在实际应用中,该数据集赋能了跨知识图谱的自动化对齐任务,例如生物医学本体(Anatomy、Bio-ML)、生物多样性(BioDiv)及通用知识图谱(Knowledge Graph)等领域的语义互操作。通过集成MELT工具链,开发者可直接下载分割后的对齐数据,并利用在线学习机制快速调整匹配系统的参数(如置信度阈值),从而在医疗知识融合、科研数据整合等场景中实现精准的实体对应关系发现。
数据集最近研究
最新研究方向
在知识图谱与本体匹配领域,随着大型语言模型等机器学习方法的广泛应用,模型训练数据的规范性与公平性成为前沿焦点。OAEI Machine Learning Dataset for Online Model Generation 数据集应运而生,它针对传统离线训练模式中系统开发者自行采样参考对齐、违背评估规则的问题,提供了标准化的训练、验证与测试分割。该数据集通过按实体类型、关系类型及映射难度进行分层抽样,确保分布一致性,并倡导在线模型生成——即系统在执行过程中自适应地调整参数,而非依赖预封装模型。这一方向紧密关联本体匹配竞赛中公平比较的迫切需求,尤其2023年会议轨道中系统对训练数据的依赖暴露了性能偏差,而该数据集通过支持置信度阈值自动调优等用例,显著提升了匹配的精准度与鲁棒性,其意义在于推动机器学习驱动的本体匹配系统走向可复现、可迁移的评估范式。
相关研究论文
- 1OAEI Machine Learning Dataset for Online Model Generation卡尔斯鲁厄理工学院(AIFB) · 2024年
以上内容由遇见数据集搜集并总结生成


