nguyenvulebinh/libris_clean_100
收藏Hugging Face2022-12-06 更新2024-03-04 收录
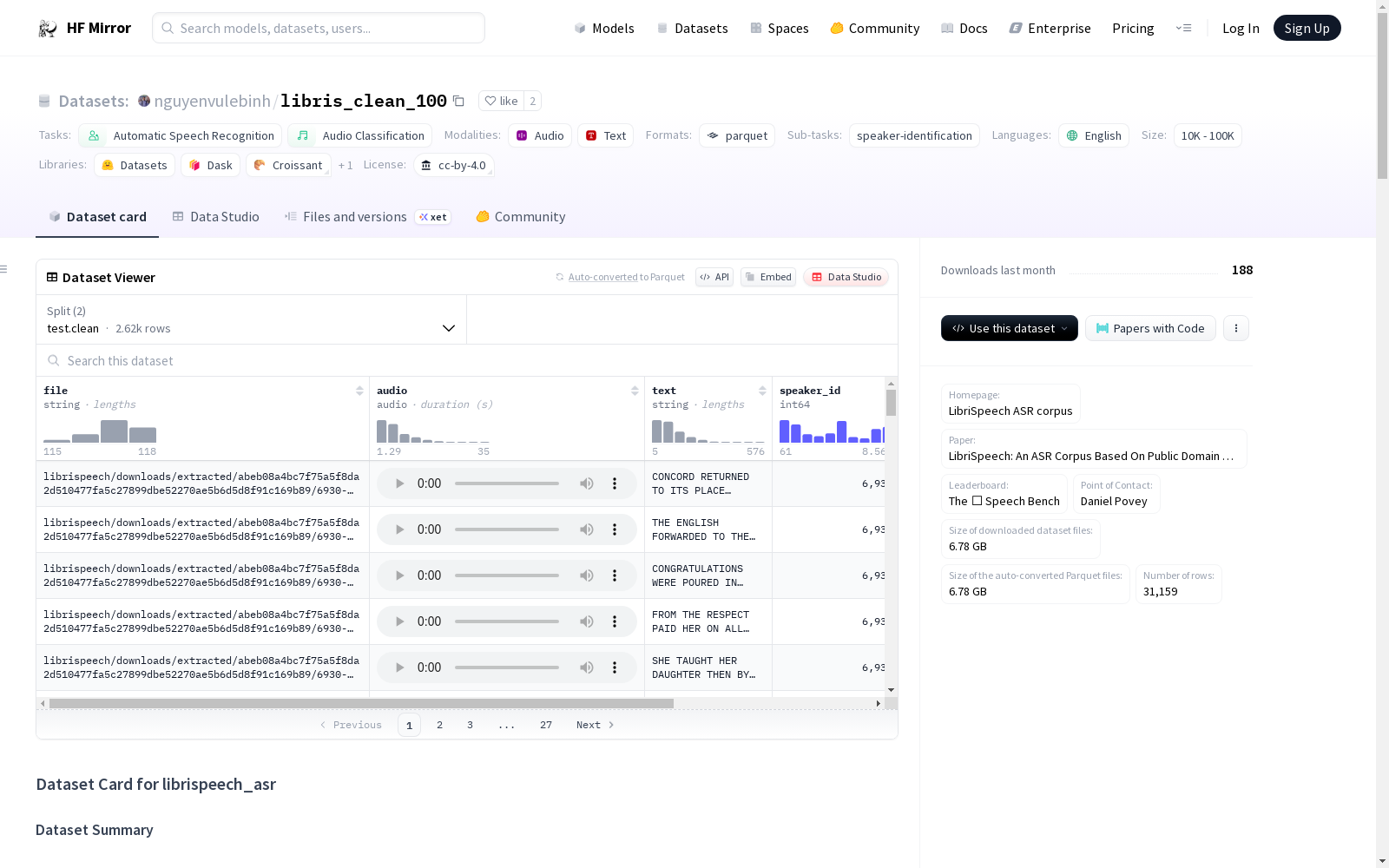
下载链接:
https://hf-mirror.com/datasets/nguyenvulebinh/libris_clean_100
下载链接
链接失效反馈资源简介:
LibriSpeech是一个包含约1000小时16kHz英语朗读语音的语料库,数据来源于LibriVox项目的有声读物,并经过仔细的分段和对齐处理。数据集支持自动语音识别(ASR)和音频说话人识别任务,并提供了两个配置:clean和other。数据集的结构包括音频文件路径、音频数据、文本转录、说话人ID、章节ID和唯一ID等信息。数据集分为训练集、验证集和测试集,训练集进一步分为train.100、train.360和train.500。数据集的创建者包括Vassil Panayotov、Guoguo Chen、Daniel Povey和Sanjeev Khudanpur,使用CC BY 4.0许可证。
LibriSpeech is a corpus containing approximately 1000 hours of 16 kHz English read speech, sourced from audiobooks of the LibriVox project with careful segmentation and alignment processing. It supports automatic speech recognition (ASR) and audio speaker recognition tasks, and provides two configurations: clean and other. The dataset structure includes information such as audio file paths, audio data, text transcriptions, speaker IDs, chapter IDs, and unique IDs. It is divided into training, validation, and test sets, where the training set is further split into train.100, train.360, and train.500. The dataset's creators are Vassil Panayotov, Guoguo Chen, Daniel Povey, and Sanjeev Khudanpur, and it is released under the CC BY 4.0 license.
提供机构:
nguyenvulebinh
原始信息汇总
数据集概述
数据集名称
- 名称: LibriSpeech
数据集属性
- 语言: 英语 (en)
- 许可证: CC-BY-4.0
- 多语言性: 单语种
- 任务类别: 自动语音识别, 音频分类
- 任务ID: 说话人识别
- 大小类别: 100K<n<1M
- 源数据集: 原始数据
- Paperswithcode ID: librispeech-1
数据集结构
- 配置名称: clean, other, all
- 特征:
- file: 字符串类型
- audio: 音频类型,采样率为16000
- text: 字符串类型
- speaker_id: 整数类型
- chapter_id: 整数类型
- id: 字符串类型
- 数据分割:
- clean配置:
- train.100: 28539个样本,6619683041字节
- train.360: 104014个样本,23898214592字节
- validation: 2703个样本,359572231字节
- test: 2620个样本,367705423字节
- other配置:
- train.500: 148688个样本,31810256902字节
- validation: 2864个样本,337283304字节
- test: 2939个样本,352396474字节
- all配置:
- train.clean.100: 28539个样本,6627791685字节
- train.clean.360: 104014个样本,23927767570字节
- train.other.500: 148688个样本,31852502880字节
- validation.clean: 2703个样本,359505691字节
- validation.other: 2864个样本,337213112字节
- test.clean: 2620个样本,368449831字节
- test.other: 2939个样本,353231518字节
- clean配置:
- 下载大小:
- clean配置: 30121377654字节
- other配置: 31236565377字节
- all配置: 61357943031字节
- 数据集大小:
- clean配置: 31245175287字节
- other配置: 32499936680字节
- all配置: 63826462287字节
数据集创建
- 注释创建者: 专家生成
- 语言创建者: 众包, 专家生成
AI搜集汇总
数据集介绍
构建方式
LibriSpeech数据集的构建基于从LibriVox项目获取的公共领域有声读物。数据集被精心分割和校准,以确保音频质量和与美式英语的发音更为接近。数据集分为'clean'和'other'两种配置,其中'clean'配置包含录音质量较高、发音更接近美式英语的音频,而'other'配置则包含其他发音。为了确保数据集的质量,使用了一个基于WSJ数据集的声学模型对音频进行识别,并计算了自动转录的词错误率(WER),根据WER将说话者分为'clean'和'other'两组。
特点
LibriSpeech数据集的特点在于其规模庞大,包含约1000小时的16kHz采样率的英语语音数据。数据集分为训练集、验证集和测试集,其中训练集进一步分为train.100、train.360和train.500三个子集,分别包含100小时、360小时和500小时的数据。每个数据点包含音频文件的路径、音频数据、文本转录、说话者ID、章节ID和唯一样本ID。数据集支持自动语音识别(ASR)和音频说话人识别等任务。
使用方法
使用LibriSpeech数据集时,可以通过访问数据集的README文件和文档来了解数据集的结构和特性。用户可以下载数据集并使用Python编程语言中的Hugging Face库来加载和访问数据。数据集提供了对音频文件、音频数组、采样率、文本转录等数据的访问。用户可以使用这些数据来训练和评估自动语音识别模型,并参与Hugging Face的ASR排行榜。
背景与挑战
背景概述
LibriSpeech,由Vassil Panayotov与Daniel Povey等人创建,是一项包含约1000小时16kHz英语朗读语音的语料库。数据来源于LibriVox项目的朗读有声读物,经过精心分割和校准。该数据集旨在为自动语音识别(ASR)任务提供训练和评估资源,并支持语音识别和音频说话人识别等任务。LibriSpeech语料库分为'clean'和'other'两种配置,根据转录的单词错误率(WER)将说话人分为两组。'clean'配置的说话人转录WER较低,'other'配置的说话人转录WER较高。该数据集已被广泛应用于语音识别研究,并在多个国际竞赛中取得了优异成绩。
当前挑战
LibriSpeech数据集在语音识别领域面临的主要挑战包括:1)数据集的多样性和覆盖范围有限,可能无法完全满足所有语音识别场景的需求;2)数据集可能存在偏差,如说话人性别、年龄、口音等,这可能会影响模型在不同群体中的表现;3)数据集的规模较大,处理和存储成本较高;4)数据集的分割方式可能导致模型训练的不均衡,需要进一步研究和改进。
常用场景
经典使用场景
LibriSpeech 数据集作为自动语音识别(ASR)研究领域的基石,其经典使用场景在于为 ASR 模型提供训练和测试数据。研究人员和开发者利用该数据集的多样性和大规模,训练出能够准确转录语音为文本的模型,广泛应用于语音助手、语音到文本的转换工具等。此外,LibriSpeech 数据集也为音频分类任务提供了丰富的资源,帮助模型学习识别和分类不同类型的音频内容。
衍生相关工作
LibriSpeech 数据集的发布和广泛应用,激发了众多相关研究工作。例如,基于该数据集的语音合成和语音增强技术取得了显著进展,为语音处理领域带来了新的可能性。此外,LibriSpeech 数据集还促进了多语言 ASR 研究的发展,为构建跨语言的语音识别系统提供了宝贵资源。
数据集最近研究
最新研究方向
LibriSpeech作为自动语音识别(ASR)领域的一项重要资源,其最新研究方向主要集中在深度学习模型在ASR任务上的性能提升。研究学者们正致力于探索更先进的神经网络架构,如Transformer、Convolutional Neural Networks(CNNs)和Recurrent Neural Networks(RNNs),以提高模型在识别不同口音、背景噪声以及不同语速的语音时的准确率。同时,研究也关注于如何更好地处理和利用LibriSpeech中的多说话人数据,通过说话人识别和说话人分离技术来提高语音识别的鲁棒性。此外,随着深度学习模型的应用越来越广泛,研究也在探索如何将LibriSpeech应用于跨语言语音识别和语音翻译等领域,以促进语音识别技术在多语言环境中的应用和发展。
以上内容由AI搜集并总结生成


