Booster Dataset
收藏arXiv2022-06-10 更新2024-06-21 收录
下载链接:
https://cvlab-unibo.github.io/booster-web/
下载链接
链接失效反馈官方服务:
资源简介:
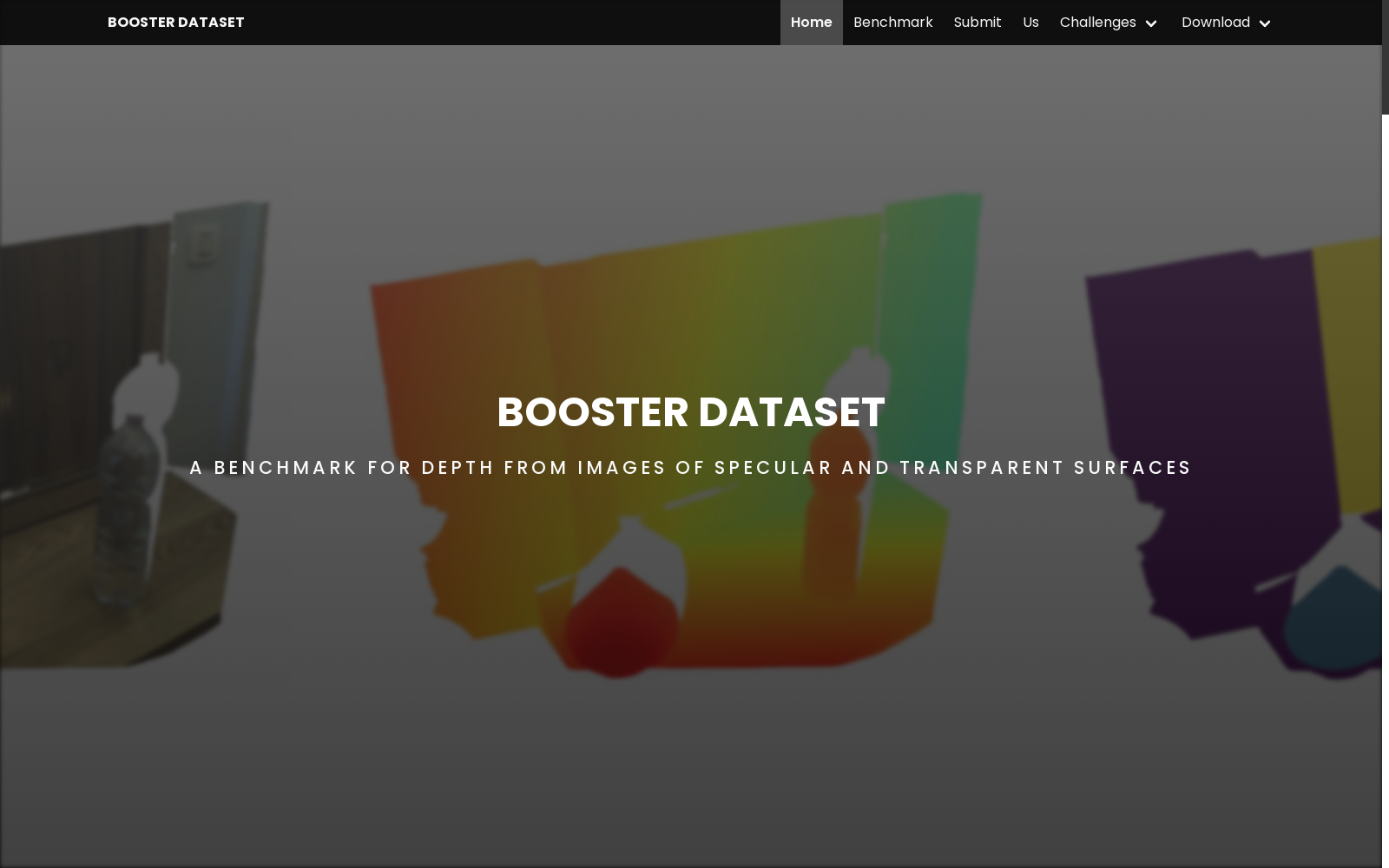
Booster数据集是一个高分辨率和挑战性的立体数据集,专注于室内场景,包含419个样本,分布在64个不同的场景中。该数据集特别之处在于包含了多种镜面和透明表面,这些是现有立体网络失败的主要原因。数据集的采集流程利用了一种新的深度时空立体框架,允许轻松和精确地标注亚像素精度的地面真实差异。此外,数据集还提供了手动标注的材料分割掩码和15K未标注样本,旨在评估和训练处理单一深度预测每像素的立体方法,主要应用于自动驾驶、障碍物避免和机器人操作等领域。
The Booster Dataset is a high-resolution, challenging stereo dataset focused on indoor scenes, comprising 419 samples across 64 unique scenarios. What sets this dataset apart is its inclusion of diverse specular and transparent surfaces, which represent major failure cases for existing stereo networks. The acquisition pipeline of the dataset leverages a novel deep spatio-temporal stereo framework, enabling effortless and precise annotation of ground-truth disparities at sub-pixel accuracy. Additionally, the dataset provides manually annotated material segmentation masks and 15K unlabeled samples, designed to evaluate and train stereo methods that perform per-pixel single depth prediction, with primary applications in fields such as autonomous driving, obstacle avoidance, and robotic manipulation.
提供机构:
计算机科学与工程系(DISI),博洛尼亚大学,意大利
创建时间:
2022-06-10
搜集汇总
数据集介绍
构建方式
Booster Dataset 是一个针对深度立体视觉领域开放挑战而构建的高分辨率数据集。该数据集收集了64个不同室内场景的图像,每个场景包含多个具有挑战性的物体和表面,如镜子等。为了准确标注每个样本,研究人员实现了一个基于深度时空立体框架的半自动标注流程,该框架结合了从多个静态图像中计算出的视差估计,并利用了预训练的深度网络进行视差图的累积。此外,研究人员还进行了最终的手动清理,以去除异常值/伪影,并确保高质量的视差标签。
使用方法
Booster Dataset 可以用于评估和训练深度立体网络,以解决深度视觉中的开放挑战,例如非朗伯表面和高分辨率图像的处理。研究人员可以使用该数据集中的标注数据进行训练和测试,并评估不同网络在处理具有挑战性的物体和表面时的准确性。此外,该数据集还提供了未标注的样本,可以用于开发弱监督解决方案,以解决立体视觉中的开放挑战。
背景与挑战
背景概述
深度立体视觉作为图像深度估计的重要分支,长期以来一直被视为替代昂贵且侵入性主动传感器的理想选择。Booster数据集正是在这一背景下应运而生,旨在解决当前深度立体视觉领域面临的开放挑战。该数据集由Pierluigi Zama Ramirez等人于2022年创建,并于同年被IEEE Conference on Computer Vision and Pattern Recognition (CVPR)接受发表。Booster数据集的特点在于其高分辨率和挑战性的室内场景,其中包含大量非朗伯表面,例如镜面和透明表面,这些表面是导致现有深度立体网络失效的主要原因。为了准确地标注这些场景,研究者们采用了一种新的深度时空立体框架,该框架允许以亚像素精度进行简单的标注。Booster数据集共包含419个样本,这些样本来自64个不同的场景,并标注有密集的地面真实视差。每个样本都包括一个高分辨率对(12Mpx)以及一个不平衡对(左:12Mpx,右:1.1Mpx)。此外,还提供了手动标注的材料分割掩码和15K个未标记的样本。该数据集的发布为深度立体视觉领域的研究人员提供了一个新的基准,并揭示了现有深度网络在处理开放挑战方面的局限性。
当前挑战
Booster数据集的创建旨在解决深度立体视觉领域中的两个主要挑战:非朗伯表面和高分辨率图像。首先,非朗伯表面,例如镜面和透明表面,对大多数计算机视觉方法和深度立体视觉技术来说仍然是一个难题。匹配这些表面的像素点非常困难,并且在许多情况下可能构成一个固有的不适定问题。其次,当考虑更高分辨率的图像时,例如Middlebury 2014基准,通常会出现更高的误差。这些误差是由于图像尺寸(以及视差范围)更大,以及图像中遮挡和无纹理像素的数量更多造成的。此外,处理高分辨率图像还会引发计算复杂性问题,尤其是在部署深度网络时。Booster数据集通过提供大量标注的非朗伯表面样本,为深度学习模型提供了克服这些挑战的机会。
常用场景
经典使用场景
Booster Dataset 是一个用于深度立体视觉研究的基准数据集,它包含了室内场景的高分辨率图像,并标注了密集且精确的视差图。该数据集的独特之处在于包含了大量具有镜面和透明表面的物体,这些表面是导致现有立体视觉网络失败的主要原因。Booster Dataset 提供了两种设置:平衡设置(左图和右图分辨率相同)和非平衡设置(左图分辨率为 12Mpx,右图分辨率为 1.1Mpx)。此外,该数据集还提供了手动标注的材料分割掩码和 15K 个未标记的样本。
解决学术问题
Booster Dataset 解决了深度立体视觉领域中的两个主要挑战:非朗伯表面和高分辨率图像。对于非朗伯反射率,透明或镜面表面的匹配像素非常困难,这在许多情况下可能是一个固有的不适定问题。Booster Dataset 中的图像包含了大量具有这些特性的物体和表面,为研究人员提供了研究这一挑战的机会。对于高分辨率图像,Booster Dataset 中的图像尺寸更大,因此视差范围更大,导致图像中遮挡和无纹理像素的数量更多。此外,处理高分辨率图像还会带来计算复杂性问题。Booster Dataset 中的非平衡设置提供了第一个真实数据集,用于研究非平衡立体匹配问题。
实际应用
Booster Dataset 主要面向自动驾驶、避障和机器人操作等应用场景。该数据集中的非朗伯表面特性使得它在这些领域具有广泛的应用前景。此外,该数据集还可以用于研究高分辨率立体匹配和弱监督学习方法。
数据集最近研究
最新研究方向
在深度立体视觉领域,Booster Dataset 的出现为研究者们提供了一个新的挑战。该数据集专注于室内场景,并包含了大量具有挑战性的物体,如镜面和透明物体。这些物体对于当前最先进的立体网络来说是一个难题,因为它们通常具有非朗伯反射率和透明度,导致像素匹配困难。Booster Dataset 的一个显著特点是提供了密集和高精度的真实视差标注,这对于评估和训练立体方法至关重要。此外,该数据集还包含了手动标注的材料分割掩码,这有助于研究人员识别和关注难以匹配的材料。Booster Dataset 的发布为立体视觉领域的研究提供了新的方向,并为未来解决深度立体视觉中的开放挑战提供了启示。
相关研究论文
- 1Open Challenges in Deep Stereo: the Booster Dataset计算机科学与工程系(DISI),博洛尼亚大学,意大利 · 2022年
以上内容由遇见数据集搜集并总结生成


