ChongyanChen/VQAonline
收藏Hugging Face2024-04-19 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/ChongyanChen/VQAonline
下载链接
链接失效反馈官方服务:
资源简介:
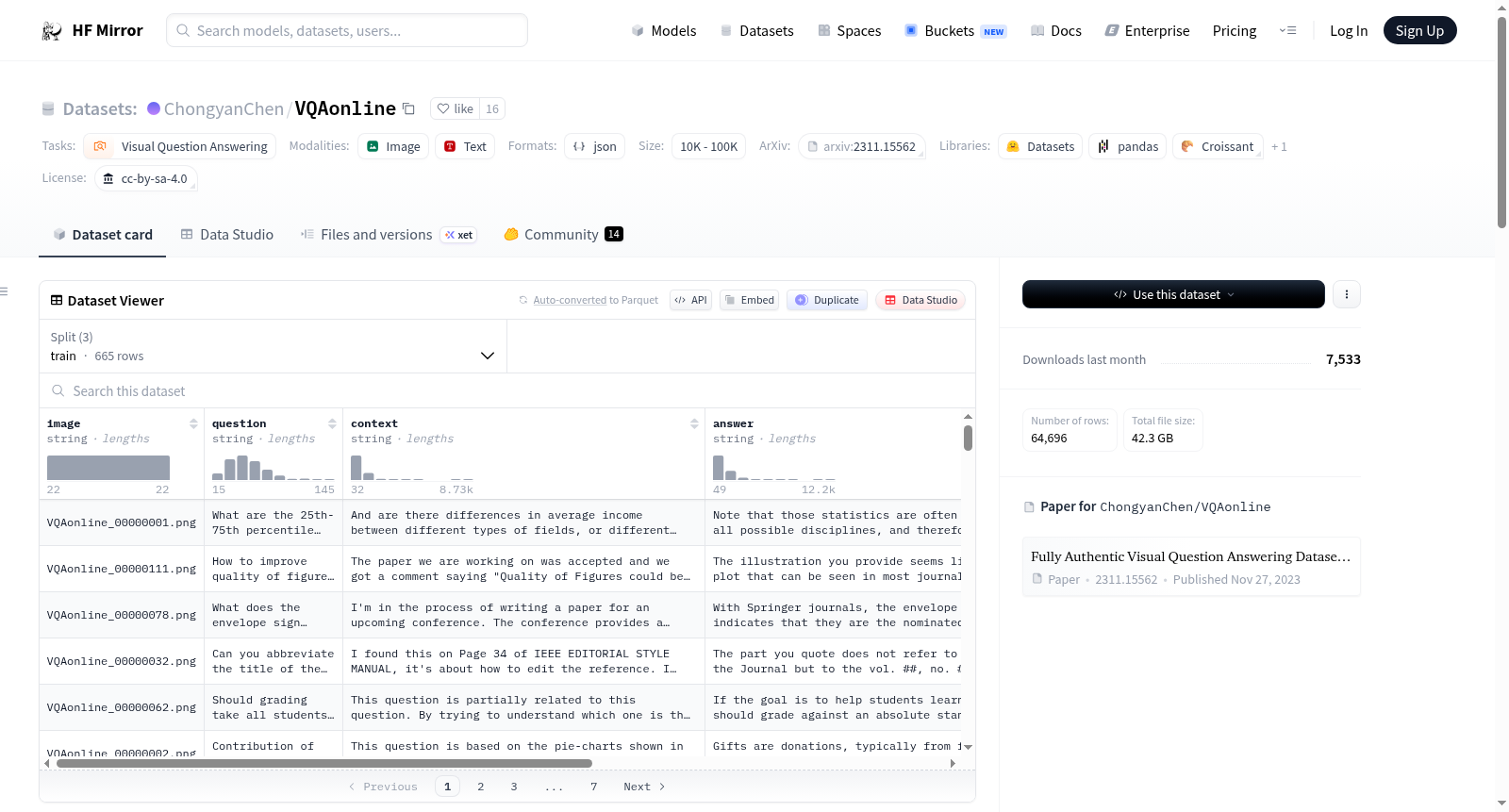
VQAonline是第一个所有内容均源自真实使用案例的视觉问答(VQA)数据集。该数据集包含来自在线问答社区(如StackExchange)的64K个视觉问题。与之前的数据集不同,VQAonline包含:(1)澄清问题的真实上下文,(2)提问者从社区提供的所有答案中验证为可接受的答案,(3)答案长度显著更长(例如,平均173字,而之前的工作通常为11字或更少),(4)每个视觉问题的用户选择主题来自105个不同的主题,揭示了数据集的固有多样性。数据集总共有64,696个视觉问题,分为训练集(665个问题)、验证集(285个问题)和测试集(63,746个问题)。问题和答案以json文件形式提供,图像文件分为7个文件夹存放。
VQAonline是第一个所有内容均源自真实使用案例的视觉问答(VQA)数据集。该数据集包含来自在线问答社区(如StackExchange)的64K个视觉问题。与之前的数据集不同,VQAonline包含:(1)澄清问题的真实上下文,(2)提问者从社区提供的所有答案中验证为可接受的答案,(3)答案长度显著更长(例如,平均173字,而之前的工作通常为11字或更少),(4)每个视觉问题的用户选择主题来自105个不同的主题,揭示了数据集的固有多样性。数据集总共有64,696个视觉问题,分为训练集(665个问题)、验证集(285个问题)和测试集(63,746个问题)。问题和答案以json文件形式提供,图像文件分为7个文件夹存放。
提供机构:
ChongyanChen
原始信息汇总
VQAonline
数据集描述
VQAonline 是首个所有内容源自真实使用场景的 VQA 数据集。该数据集包含 64,000 个视觉问题,来源于在线问答社区(即 StackExchange)。
VQAonline 与先前的数据集不同,具有以下特点:
- 包含澄清问题的真实上下文。
- 包含提问者验证为可接受的社区提供的答案。
- 答案较长,平均 173 个单词,而先前工作通常为 11 个单词或更少。
- 每个视觉问题都有用户选择的 105 个不同主题,揭示了数据集的内在多样性。
数据集结构
VQAonline 数据集总共包含 64,696 个视觉问题。数据集设计支持少样本设置,具体划分如下:
- 训练集:665 个视觉问题
- 验证集:285 个视觉问题
- 测试集:63,746 个视觉问题
问题、上下文和答案以 json 文件形式提供。图像文件被分为 7 个文件夹(从 images1 到 images7),每个文件夹包含 10,000 个图像文件,除了 "images7" 文件夹。
引用
bibtex @article{chen2023vqaonline, title={Fully Authentic Visual Question Answering Dataset from Online Communities}, author={Chen, Chongyan and Liu, Mengchen and Codella, Noel and Li, Yunsheng and Yuan, Lu and Gurari, Danna}, journal={arXiv preprint arXiv:2311.15562}, year={2023} }
搜集汇总
数据集介绍
构建方式
在视觉问答研究领域,VQAonline数据集的构建标志着一次重要的范式转变。该数据集从在线问答社区StackExchange中系统性地收集了64,696个真实的视觉问题,确保了所有内容均源自实际应用场景。构建过程不仅提取了用户提出的原始问题与对应图像,还精心保留了澄清问题的真实上下文信息,并收录了提问者从社区众多答案中验证为可接受的长篇解答。这种构建方式使得数据集天然具备了丰富的语境和用户验证的答案质量。
使用方法
为顺应基础模型在上下文少样本学习方面的进展,该数据集在结构上进行了针对性设计。它被划分为包含665个样本的训练集、285个样本的验证集以及多达63,746个样本的测试集,旨在有效支持少样本学习场景的研究。使用者可通过克隆指定仓库获取数据,问题、上下文和答案存储于JSON文件中,而图像文件则分置于七个文件夹内以便管理。这种划分方式便于研究者直接利用其进行模型在真实、复杂视觉问答任务上的评估与调优。
背景与挑战
背景概述
视觉问答(VQA)作为跨模态人工智能的核心研究方向,旨在使模型能够理解图像内容并回答自然语言问题。传统VQA数据集多基于人工构造或特定场景,其内容往往缺乏真实世界的复杂性与多样性。2024年,由德克萨斯大学奥斯汀分校的研究团队Chongyan Chen等人创建的VQAonline数据集,首次从在线问答社区StackExchange中采集全部内容,标志着VQA研究向真实应用场景的重要迈进。该数据集包含约6.4万个视觉问题,每个问题均附带用户提供的上下文、经社区验证的长篇答案以及105个多样化主题标签,不仅丰富了数据的语义层次,也为少样本学习与基础模型评估提供了更贴近实际需求的基准。
当前挑战
VQAonline数据集致力于解决真实场景中视觉问答的复杂性挑战,其核心问题在于如何让模型理解带有丰富上下文的长篇问题,并生成详尽、准确的答案,这超越了传统数据集中常见的简短问答模式。在构建过程中,研究团队面临多重挑战:一是从非结构化社区数据中提取高质量的视觉问题与对应图像,需确保内容的真实性与版权合规;二是处理答案长度显著增加带来的标注与评估困难,平均答案长度达173词,远高于以往数据集的11词以内;三是维护105个主题下的数据多样性,同时平衡训练、验证与测试集的划分,以支持少样本学习场景下的可靠评估。
常用场景
经典使用场景
在视觉问答领域,VQAonline数据集以其源自真实在线社区的内容,为研究提供了独特的实验平台。该数据集最经典的使用场景在于支持少样本学习设置,尤其适用于基于基础模型的上下文少样本学习研究。通过包含64,696个视觉问题,每个问题均附带用户提供的详细上下文和经过验证的长篇答案,研究者能够评估模型在真实、多样化主题下的理解和生成能力,推动视觉与语言融合任务的前沿探索。
解决学术问题
VQAonline数据集解决了传统视觉问答数据集中存在的若干局限性,如答案简短、语境缺失和真实性不足等学术问题。它通过引入来自StackExchange社区的认证答案和丰富上下文,增强了数据集的真实性和复杂性,使得研究能够更准确地模拟人类在开放环境中的问答交互。这一创新不仅提升了模型对长文本答案的处理能力,还为跨领域、多主题的视觉理解研究提供了可靠基准,促进了视觉问答系统向实用化方向发展。
实际应用
在实际应用层面,VQAonline数据集可广泛应用于智能辅助系统、在线教育平台和内容审核工具中。例如,在在线社区或教育场景中,系统可利用该数据集训练模型,自动回答用户基于图像的复杂问题,提供详细、可靠的解释,从而提升用户体验和效率。其涵盖的105个多样化主题确保了模型能够适应不同领域的需求,为开发更智能、交互性更强的视觉问答应用奠定了坚实基础。
数据集最近研究
最新研究方向
在视觉问答领域,VQAonline数据集的推出标志着研究重心向真实应用场景的迁移。该数据集源自在线问答社区StackExchange,其内容完全基于真实用户互动,为模型训练提供了前所未有的真实性。当前前沿研究聚焦于利用其长文本答案和多样化主题特性,探索少样本学习与上下文理解能力的提升。热点事件包括在基础模型框架下,如何有效整合多模态信息以应对复杂、开放的视觉问题。这一进展不仅推动了视觉语言模型向更实用、更人性化的方向发展,也为在线教育、智能辅助等实际应用奠定了坚实基础,具有深远的学术与工程意义。
以上内容由遇见数据集搜集并总结生成


