读光-OCR-文本长度均匀分布的场景文字识别数据集-英文
收藏魔搭社区2026-01-09 更新2024-05-15 收录
下载链接:
https://modelscope.cn/datasets/iic/TUL
下载链接
链接失效反馈官方服务:
资源简介:
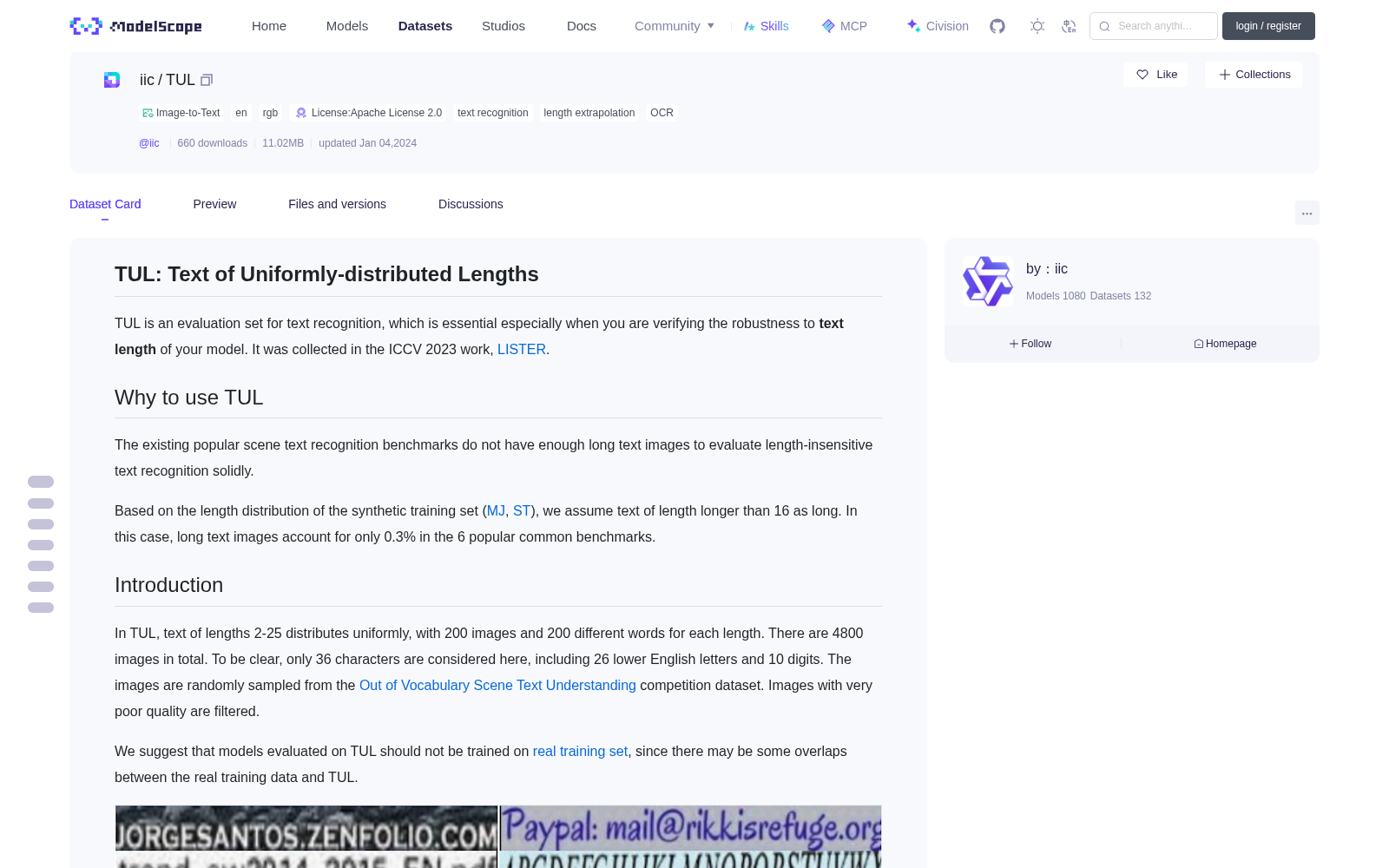
In the image (text line) dataset, text of lengths 2-25 distributes uniformly, with 200 images and 200 different words for each length. It can be used to evaluate length-insensitive text recognition.
本图像(文本行)数据集(image (text line) dataset)中,文本长度介于2至25的样本分布均匀,且每个长度对应200张图像与200个不同单词。该数据集可用于评估对文本长度不敏感的文本识别任务。
提供机构:
maas
创建时间:
2023-08-16
搜集汇总
数据集介绍
背景与挑战
背景概述
TUL是一个用于场景文字识别的评估数据集,专门设计用于验证模型对文本长度的鲁棒性。它包含4800张图像,文本长度从2到25均匀分布,每长度对应200张图像和200个不同单词,仅使用小写英文字母和数字。数据集以lmdb格式存储,建议评估时避免使用真实训练数据以防止重叠。
以上内容由遇见数据集搜集并总结生成


