olmOCR-mix-1025
收藏Hugging Face2025-10-22 更新2025-10-22 收录
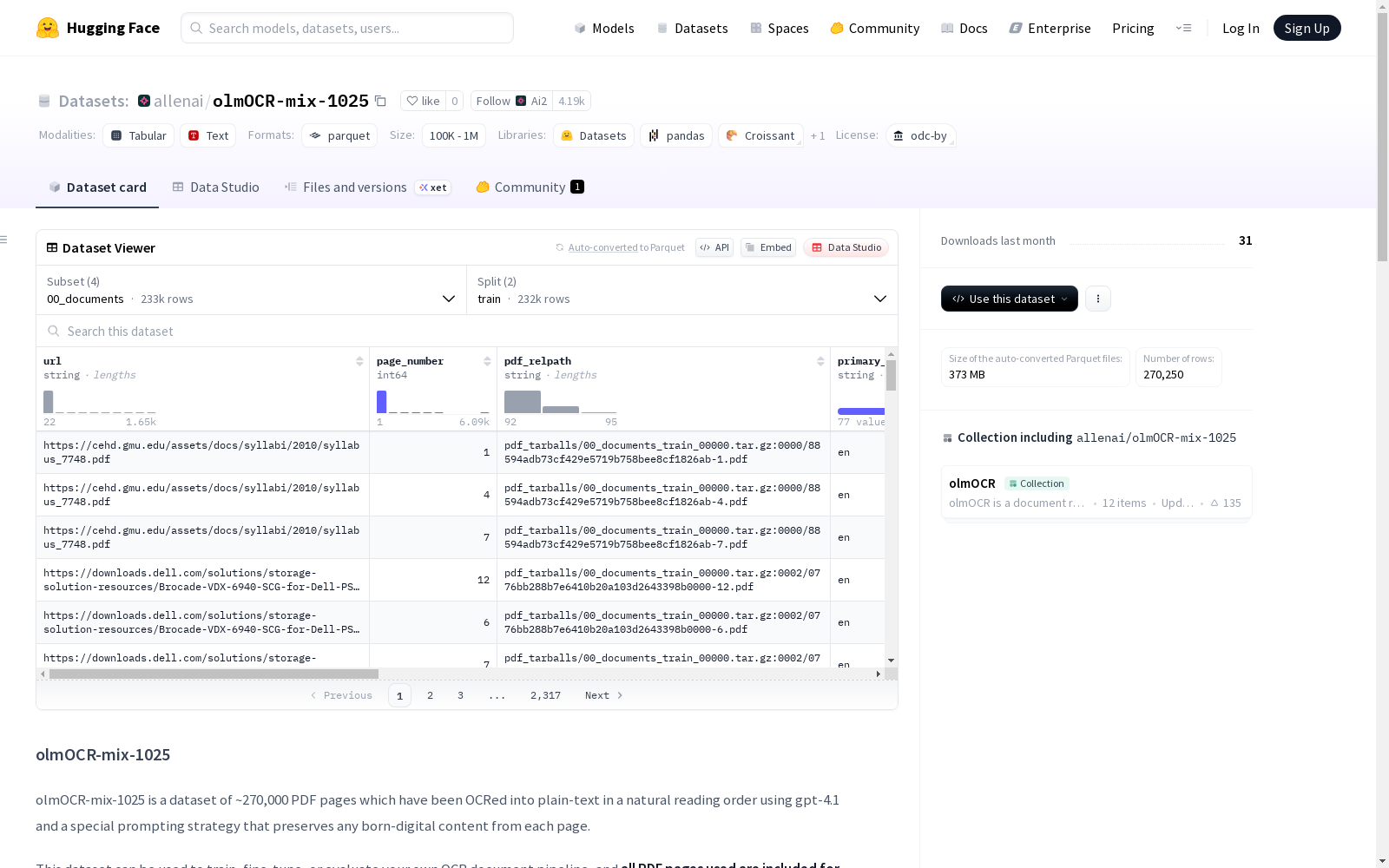
下载链接:
https://huggingface.co/datasets/allenai/olmOCR-mix-1025
下载链接
链接失效反馈官方服务:
资源简介:
olmOCR-mix-1025是一个包含约270,000个PDF页面的数据集,这些页面已被使用gpt-4.1和特殊提示策略OCR识别为自然阅读顺序的纯文本,并保留了页面上的原生数字内容。该数据集可用于训练、微调或评估OCR文档管道。
提供机构:
Allen Institute for AI
创建时间:
2025-10-08
原始信息汇总
olmOCR-mix-1025 数据集概述
数据集简介
olmOCR-mix-1025 是一个包含约270,000个PDF页面的数据集,这些页面使用gpt-4.1和特殊提示策略进行了OCR处理,转换为自然阅读顺序的纯文本,并保留了每页的原始数字内容。
数据集构成
配置结构
- 00_documents: 训练集231,668条,评估集1,122条
- 01_books: 训练集16,575条,评估集899条
- 02_loc_transcripts: 训练集9,891条,评估集98条
- 03_national_archives: 训练集9,828条,评估集169条
数据统计
| 子集 | 训练集 | 评估集 | 总计 |
|---|---|---|---|
| 00_documents | 231,668 | 1,122 | 232,790 |
| 01_books | 16,575 | 899 | 17,474 |
| 02_loc_transcripts | 9,891 | 98 | 9,989 |
| 03_national_archives | 9,828 | 169 | 9,997 |
| 总计 | 267,962 | 2,288 | 270,250 |
语言分布
00_documents
- 英语: 94.46%
- 西班牙语: 0.58%
- 法语: 0.46%
- 印尼语: 0.45%
- 德语: 0.42%
01_books
- 英语: 91.28%
- 法语: 0.54%
- 拉丁语: 0.31%
- 德语: 0.27%
- 印地语: 0.12%
02_loc_transcripts
- 英语: 98.21%
- 西班牙语: 0.59%
- 法语: 0.46%
- 德语: 0.45%
- 意大利语: 0.11%
03_national_archives
- 英语: 99.82%
- 西班牙语: 0.12%
- 法语: 0.02%
- 瑞典语: 0.01%
- 德语: 0.01%
改进特性
- 使用gpt-4.1处理的更清晰输出
- 使用[和(进行更一致的数学公式格式化
- HTML格式的表格替代- 图像的基本替代文本
- 更多手写和历史文档
使用方法
使用olmocr工具包提取数据: bash pip install olmocr python -m olmocr.data.prepare_olmocrmix --dataset-path allenai/olmOCR-mix-1025 --destination ~/olmOCR-mix-1025-extracted --subset [子集名称] --split [分割类型]
数据来源
00_documents和01_books: PDF页面渲染后通过Chat GPT 4.1进行高质量转录02_loc_transcripts和03_national_archives: 来自美国国会图书馆和国家档案馆的历史文档,经过ChatGPT清理转录文本
许可证
本数据集采用ODC-BY许可证,遵循Ai2的负责任使用指南,仅供研究和教育用途。
搜集汇总
数据集介绍
构建方式
在文档数字化处理领域,olmOCR-mix-1025数据集的构建采用了创新的多源采集策略。该数据集通过GPT-4.1模型配合特殊提示策略,对约27万页PDF文档进行光学字符识别,将内容转换为保持自然阅读顺序的纯文本。针对不同来源的文档采用了差异化处理方案:对于常规文档和书籍类内容,直接通过模型进行高质量转录;而对于美国国会图书馆和国家档案馆的历史文献,则基于已有的人工标注转录进行智能化清洗,有效去除冗余文本。这种分层处理方式既保证了转录质量,又充分利用了现有高质量标注资源。
使用方法
在实践应用层面,该数据集为OCR技术研发提供了完整的解决方案。用户可通过Hugging Face平台直接访问包含元数据和文本转录的parquet文件,利用数据集查看器进行初步分析。对于模型训练需求,推荐使用专用的olmocr工具包进行数据预处理,通过命令行指令按子集和分割类型分别下载提取PDF文档至本地目录。数据集按照文档类型划分为四个独立配置,每个配置均包含训练集和评估集,支持用户根据具体需求选择性下载。这种分层设计既满足了大规模模型训练的数据需求,又为特定领域的精细化研究提供了便利。
背景与挑战
背景概述
光学字符识别技术作为文档数字化进程的核心环节,其发展历程始终面临着复杂版面分析与多语言文本识别的双重考验。olmOCR-mix-1025数据集由艾伦人工智能研究所于2024年构建,通过集成GPT-4.1先进语言模型与特殊提示策略,实现了27万页PDF文档的智能转录。该数据集涵盖文档、书籍、国会图书馆档案及国家档案馆史料四大子集,重点解决数字原生内容保留与历史文献数字化难题,为文档智能处理领域提供了高质量的基准数据支撑。
当前挑战
在文档智能处理领域,传统OCR系统常因版面结构复杂、数学公式多样及多语言混排等问题导致识别精度受限。olmOCR-mix-1025在构建过程中面临三大技术挑战:其一是保持数字原生内容的完整性,需通过特殊提示策略确保原始文档结构与语义一致性;其二是处理历史文献的退化现象,包括手写体识别与纸质文档的噪声干扰;其三是统一多源数据的标注标准,特别是在处理国会图书馆与国家档案馆的异构档案时,需要平衡转录准确性与格式规范性之间的张力。
常用场景
经典使用场景
在文档数字化处理领域,olmOCR-mix-1025数据集通过集成27万页PDF文档的OCR文本,为训练和评估光学字符识别模型提供了标准化基准。其多源数据配置覆盖了书籍、历史档案与政府文件等场景,特别适用于验证模型在复杂版式与多语言环境下的文本还原能力。数据集采用自然阅读顺序的转录策略,有效保留了数学公式、表格结构等数字原生内容,成为文档智能分析领域的重要实验平台。
解决学术问题
该数据集针对传统OCR技术在处理历史文献与多模态内容时的局限性,通过GPT-4.1生成的精准标注解决了文档结构重建、数学公式识别等核心难题。其包含的手写体样本与多语言分布特性,为跨时代文档的数字化保存提供了技术支撑,显著推进了数字人文研究中文本挖掘与知识图谱构建的深度。
实际应用
在文化遗产保护实践中,该数据集支撑的OCR技术已应用于美国国会图书馆与国家档案馆的文献数字化工程。通过自动化处理历史手稿与印刷文档,不仅加速了公共知识资源的开放获取,更为教育机构构建数字图书馆提供了高质量文本语料,有效促进了学术资源的普惠传播。
数据集最近研究
最新研究方向
在光学字符识别领域,olmOCR-mix-1025数据集凭借其27万页PDF文档的规模,正推动多模态文档理解技术的革新。前沿研究聚焦于利用GPT-4.1生成的精准文本标注,开发端到端的智能文档处理系统,尤其关注历史文献数字化保护与数学公式结构化解析。随着数字人文研究兴起,该数据集通过整合国会图书馆和国家档案馆的珍稀史料,为古籍自动校勘和跨语言文档分析提供了重要实验基础。其创新的HTML表格保留机制与手写体识别模块,正在重塑当代档案学研究的范式。
以上内容由遇见数据集搜集并总结生成


