x_dataset_193
收藏Hugging Face2025-07-23 更新2025-07-24 收录
下载链接:
https://huggingface.co/datasets/sesen01/x_dataset_193
下载链接
链接失效反馈官方服务:
资源简介:
Bittensor Subnet 13 X (Twitter)数据集是Bittensor Subnet 13去中心化网络的一部分,包含了来自X(前Twitter)的预处理数据。这些数据由网络矿工持续更新,提供实时推文流,用于各种分析和机器学习任务。数据集支持多种任务类型,如情感分析、趋势检测、内容分析和用户行为建模等。数据集主要是英文,但也支持多语言。每个数据实例代表一条推文,包括文本内容、情感或话题标签、话题标签列表、发布日期以及用户名和URL的编码形式。数据集不断更新,没有固定的划分,用户需根据数据的时间戳来创建自己的划分。数据来源于公共推文,对个人信息进行了编码保护。
创建时间:
2025-07-20
原始信息汇总
Bittensor Subnet 13 X (Twitter) Dataset 概述
基本信息
- 许可证: MIT
- 多语言支持: 多语言
- 数据来源: 原始数据
- 任务类别:
- 文本分类
- 标记分类
- 问答
- 摘要
- 文本生成
- 任务ID:
- 情感分析
- 主题分类
- 命名实体识别
- 语言建模
- 文本评分
- 多类分类
- 多标签分类
- 抽取式问答
- 新闻文章摘要
数据集描述
- 仓库: sesen01/x_dataset_193
- 子网: Bittensor Subnet 13
- 矿工热键: 5ED7qT5g935eaBkR7JA6Zd7Ja1z2wqYQdbzUq7UY2qcGwkJa
数据集摘要
该数据集是Bittensor Subnet 13去中心化网络的一部分,包含来自X(原Twitter)的预处理数据。数据由网络矿工持续更新,提供实时的推文流,适用于多种分析和机器学习任务。
支持的任务
- 情感分析
- 趋势检测
- 内容分析
- 用户行为建模
语言
主要语言为英语,但由于去中心化的创建方式,可能包含多语言内容。
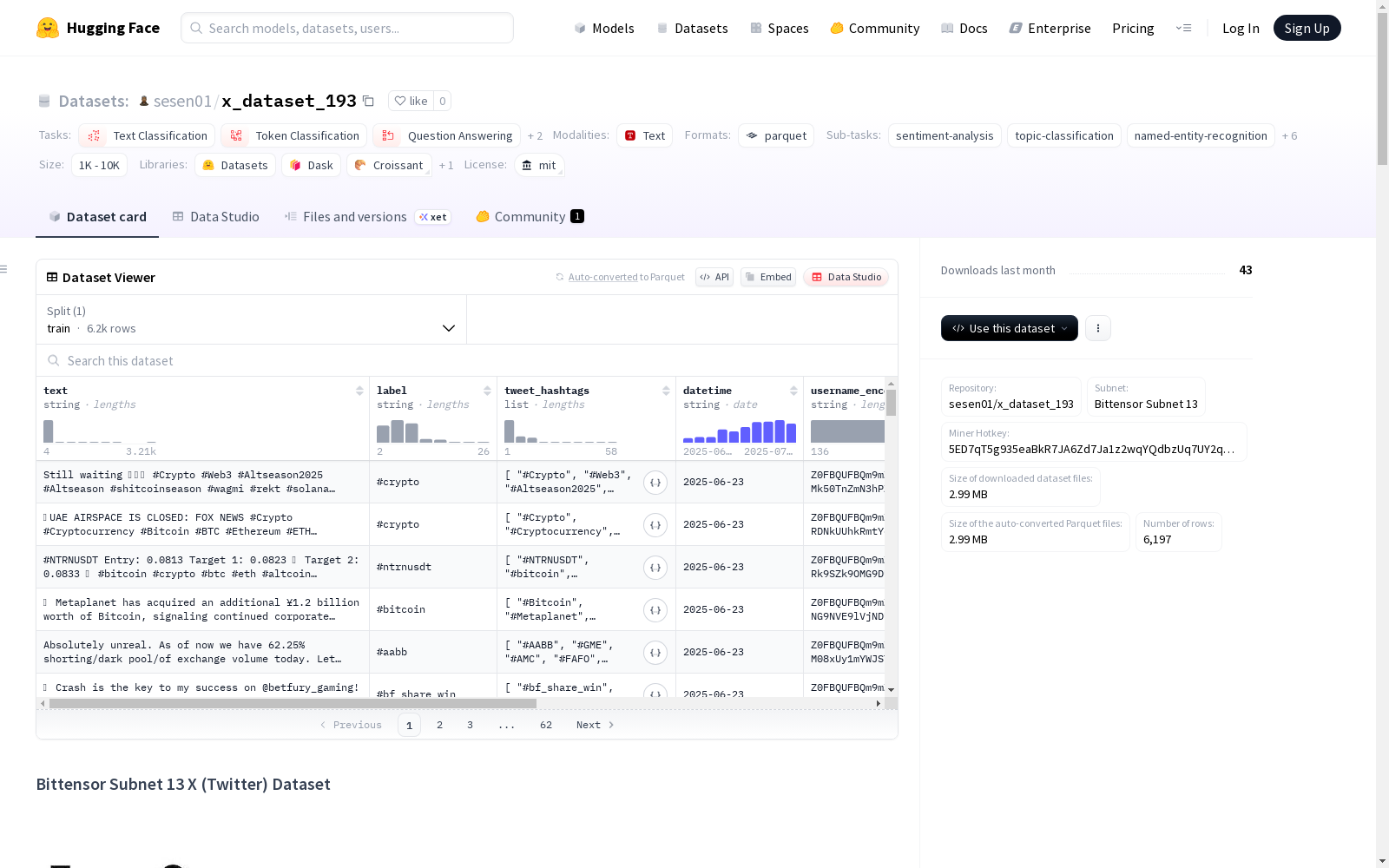
数据集结构
数据实例
每个实例代表一条推文,包含以下字段:
text(字符串): 推文的主要内容。label(字符串): 推文的情感或主题类别。tweet_hashtags(列表): 推文中使用的标签列表。如果没有标签则为空。datetime(字符串): 推文发布的日期。username_encoded(字符串): 用户名的编码版本,以保护用户隐私。url_encoded(字符串): 推文中包含的URL的编码版本。如果没有URL则为空。
数据分割
数据集持续更新,没有固定的分割。用户应根据自己的需求和数据的时戳创建自己的分割。
数据集创建
源数据
数据来自X(Twitter)的公开推文,遵循平台的服务条款和API使用指南。
个人和敏感信息
所有用户名和URL均被编码以保护用户隐私。数据集不包含故意添加的个人或敏感信息。
使用注意事项
社会影响和偏见
用户应注意X(Twitter)数据中潜在的偏见,包括人口统计和内容偏见。该数据集反映了X上的内容和观点,不应被视为一般人群的代表样本。
限制
- 数据质量可能因去中心化的收集和预处理方式而有所不同。
- 数据集可能包含社交媒体平台典型的噪声、垃圾邮件或无关内容。
- 由于实时收集方法,可能存在时间偏差。
- 数据集仅限于公开推文,不包含私人账户或直接消息。
- 并非所有推文都包含标签或URL。
附加信息
许可信息
数据集在MIT许可证下发布。使用该数据集还受X使用条款的约束。
引用信息
如果使用该数据集进行研究,请按以下方式引用:
@misc{sesen012025datauniversex_dataset_193, title={The Data Universe Datasets: The finest collection of social media data the web has to offer}, author={sesen01}, year={2025}, url={https://huggingface.co/datasets/sesen01/x_dataset_193}, }
贡献
如需报告问题或贡献数据集,请联系矿工或使用Bittensor Subnet 13治理机制。
数据集统计
- 总实例数: 6197
- 日期范围: 2025-06-23T00:00:00Z 至 2025-07-23T00:00:00Z
- 最后更新时间: 2025-07-23T11:10:51Z
数据分布
- 带标签的推文: 100.00%
- 不带标签的推文: 0.00%
前10标签
| 排名 | 主题 | 总数 | 百分比 |
|---|---|---|---|
| 1 | #bitcoin | 940 | 15.17% |
| 2 | #btc | 742 | 11.97% |
| 3 | #crypto | 356 | 5.74% |
| 4 | #gold | 355 | 5.73% |
| 5 | #defi | 310 | 5.00% |
| 6 | #tao | 135 | 2.18% |
| 7 | #cryptocurrency | 131 | 2.11% |
| 8 | #eth | 71 | 1.15% |
| 9 | #web3 | 52 | 0.84% |
| 10 | #xrp | 47 | 0.76% |
更新历史
| 日期 | 新实例 | 总实例 |
|---|---|---|
| 2025-07-21T06:57:48Z | 5271 | 5271 |
| 2025-07-22T00:29:27Z | 374 | 5645 |
| 2025-07-22T17:52:26Z | 199 | 5844 |
| 2025-07-23T11:10:51Z | 353 | 6197 |
搜集汇总
数据集介绍
构建方式
在社交媒体分析领域,x_dataset_193数据集通过Bittensor Subnet 13去中心化网络构建,采用实时更新的方式收集并预处理来自X平台的公开推文。数据采集严格遵循平台服务条款及API使用规范,所有用户名和URL均经过编码处理以保护用户隐私。该数据集采用动态更新机制,确保研究者能够获取最新的社交媒体数据流。
特点
作为多任务适配的社会化媒体语料库,x_dataset_193展现出鲜明的实时性与多模态特征。数据集包含文本内容、情感标签、主题分类等结构化字段,特别值得注意的是其完整保留的元数据信息,如带有时区标记的发布时间戳和加密处理的用户标识。数据分布呈现典型的长尾特征,加密货币相关主题标签占据显著比重,这为研究特定领域的社会传播模式提供了天然实验场。
使用方法
研究者可通过HuggingFace平台直接加载该数据集,建议结合时序特征建立自定义数据分割策略。鉴于数据的实时更新特性,推荐采用流式处理架构进行建模。典型应用场景包括构建端到端的情感分析模型,或利用主题标签网络进行传播动力学研究。使用时需注意数据采集的时间窗口效应,并建议配合去偏技术以消除社交媒体固有的选择偏差。
背景与挑战
背景概述
x_dataset_193作为Bittensor Subnet 13去中心化网络的重要组成部分,由Macrocosmos研究团队于2025年构建,专注于采集并预处理X平台(原Twitter)的实时社交媒体数据。该数据集依托区块链技术的分布式特性,通过全球矿工节点持续更新,为自然语言处理领域提供了动态研究素材。其核心价值在于解决了传统社交媒体数据集更新滞后、覆盖范围有限的问题,特别在加密货币和区块链话题的舆情分析方面展现出独特优势,已成为多任务学习时代跨领域研究的基准数据源之一。
当前挑战
该数据集面临双重技术挑战:在领域问题层面,社交媒体文本固有的噪声、语义模糊性及话题分布不均衡特性,对情感分析、命名实体识别等任务构成显著干扰;在构建过程中,去中心化采集机制导致数据质量波动,需设计复杂的清洗流程应对垃圾信息与重复内容。隐私保护要求下的用户名编码策略虽符合伦理规范,但增加了用户行为连续性分析的难度。此外,实时流数据的时间敏感性要求模型具备动态适应能力,这对传统静态评估范式提出了革新要求。
常用场景
经典使用场景
在社交网络分析领域,x_dataset_193数据集凭借其实时更新的特性,成为研究社交媒体动态的重要工具。该数据集最经典的使用场景包括情感分析和主题分类,研究人员通过分析推文内容和标签,揭示公众对特定话题的情感倾向和关注热点。尤其在加密货币和金融科技领域,该数据集为追踪市场情绪和行业趋势提供了宝贵的数据支持。
解决学术问题
该数据集有效解决了社交媒体数据挖掘中的多个学术难题。其标注字段和编码处理为研究者提供了结构化数据,克服了原始社交数据杂乱无章的障碍。通过连续更新的数据流,学者们能够开展时序分析,探究网络话题的演变规律。同时,多语言特性为跨文化传播研究创造了条件,而用户行为建模则助力于社交网络理论的验证与发展。
衍生相关工作
围绕该数据集已产生多项创新研究。在自然语言处理领域,有学者基于其开发了新型的情感分析模型。社交网络分析方面,衍生出基于时序的话题传播追踪方法。部分团队还结合图神经网络,构建了用户影响力评估系统。这些工作不仅拓展了数据集的学术价值,也为后续研究提供了方法论参考。
以上内容由遇见数据集搜集并总结生成


