UVT-Explanatory-based-Vision-Tasks
收藏Hugging Face2025-02-12 更新2025-02-13 收录
下载链接:
https://huggingface.co/datasets/axxkaya/UVT-Explanatory-based-Vision-Tasks
下载链接
链接失效反馈官方服务:
资源简介:
UVT Explanatory Vision Tasks数据集包含1200万个'image input → explanatory instruction → output'三元组,旨在通过详细的语言转换来定义计算机视觉任务目标,以实现指令级别的零样本能力和对未见计算机视觉任务的强零样本泛化。
创建时间:
2025-01-30
搜集汇总
数据集介绍
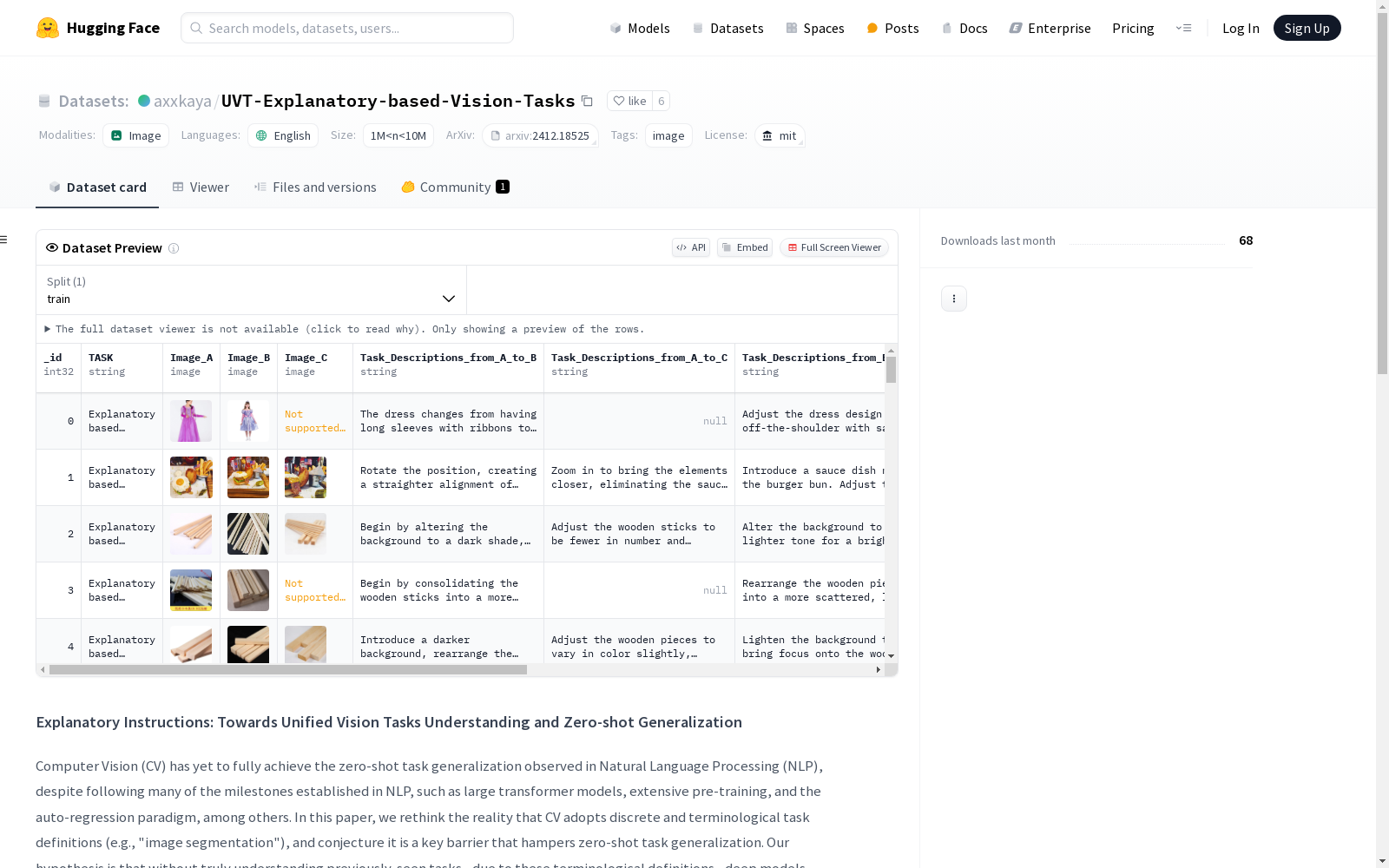
构建方式
UVT Explanatory Vision Tasks数据集的构建采用了一种新的方式,即通过详细的语言转换,将输入图像与输出之间的任务目标进行定义。该数据集包含了1200万个'image input → explanatory instruction → output'的三元组,这些三元组是通过将图像输入转化为解释性指令,再将指令转化为输出结果的方式构建而成的。
特点
该数据集的主要特点是引入了解释性指令,这为计算机视觉任务的理解和零样本泛化提供了新的途径。数据集中的图像和指令互为关联,形成了丰富的视觉任务描述,有助于模型学习到更深入的任务理解,从而实现指令级别的零样本能力。
使用方法
使用该数据集时,用户可以直接通过HuggingFace的库进行加载。加载后,数据集会以parquet格式存储,包含_id、TASK、Image_A、Image_B、Image_C以及多个描述从图像A到图像B、C,以及从B、C回到A、C的Task_Descriptions字段。用户可以根据自己的需求对这些字段进行相应的处理和使用。
背景与挑战
背景概述
UVT-Explanatory-based-Vision-Tasks数据集是在计算机视觉领域向零样本任务泛化迈进的背景下创建的。该数据集由Shen Yang等研究人员于2024年提出,旨在通过提供详细的自然语言描述,将计算机视觉任务目标定义为输入图像到输出的转换,以克服传统术语式任务定义对零样本泛化的限制。该数据集包含了1200万个“图像输入→解释性指令→输出”的三元组,为训练具有指令级零样本能力的自动回归式视觉语言模型提供了丰富的资源。该数据集的构建不仅推动了计算机视觉领域任务理解的研究,也为零样本泛化提供了新的视角和方法。
当前挑战
在构建UVT-Explanatory-based-Vision-Tasks数据集的过程中,研究人员面临着多项挑战。首先,如何精确地定义和描述视觉任务的指令,以确保模型能够理解和执行这些任务,是一个关键问题。其次,数据集的规模和多样性对于模型的泛化能力至关重要,因此在收集和标注数据时,确保数据的质量和覆盖范围是一项艰巨的任务。此外,传统的计算机视觉任务定义方式根深蒂固,如何在现有的研究框架中引入和验证新的任务定义方式,也是研究过程中的一大挑战。
常用场景
经典使用场景
在计算机视觉领域,UVT-Explanatory-based-Vision-Tasks数据集的典型应用场景是辅助机器学习模型理解视觉任务的内在逻辑,进而实现零样本任务泛化。该数据集通过提供详细的、从输入图像到输出的语言转换说明,为模型提供了一种直观的任务定义方式。
解决学术问题
该数据集解决了计算机视觉中任务定义过于离散和术语化的问题,这一问题阻碍了模型在未见过的任务上的零样本泛化能力。通过使用基于解释的指令,模型能够真正理解之前见过的任务,从而在未见过的计算机视觉任务上展现出强大的零样本泛化能力。
衍生相关工作
该数据集的推出促进了相关领域的研究,如基于解释的指令学习、视觉任务统一理解以及零样本学习等。已有研究在此基础上探讨了如何通过语言描述来提高视觉模型的泛化能力,并取得了一系列创新成果。
以上内容由遇见数据集搜集并总结生成


