rifat101/BnSentMix
收藏Hugging Face2026-04-30 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/rifat101/BnSentMix
下载链接
链接失效反馈官方服务:
资源简介:
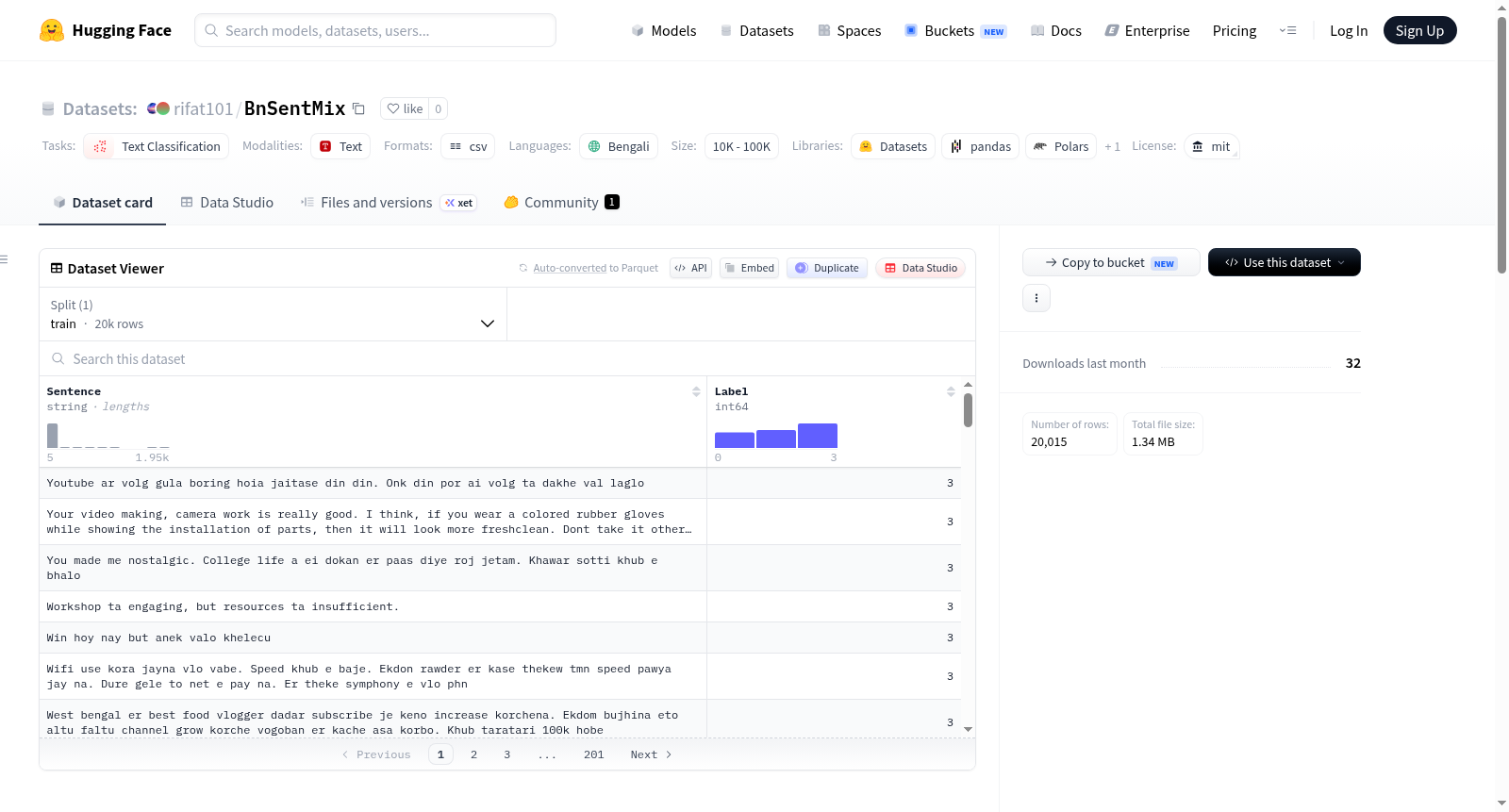
BnSentMix是一个多样化的孟加拉语-英语代码混合数据集,用于情感分析。数据集包含20,000个样本,数据来源于Facebook、YouTube和电子商务网站。情感标签分为4类:1:积极、2:消极、3:中性、4:混合。数据过滤使用了mBERT自动方法,由64名注释者进行标注,每个样本有2或3次注释(当出现平局时)。数据集统计信息包括平均字符长度62.77,最大字符长度1985,最小字符长度14,平均单词数11.65,最大单词数368,最小单词数4,唯一单词数37734,唯一句子数21873。
BnSentMix: A Diverse Bengali-English Code-Mixed Dataset for Sentiment Analysis. The dataset contains 20,000 samples collected from Facebook, YouTube, and E-commerce Sites. Sentiment labels include 1:Positive, 2:Negative, 3:Neutral, 4:Mixed. Data was filtered using mBERT automatically, annotated by 64 annotators with 2 or 3 annotations per sample (in case of ties). Dataset statistics show: Mean Character Length 62.77, Max Character Length 1985, Min Character Length 14, Mean Word Count 11.65, Max Word Count 368, Min Word Count 4, Unique Word Count 37734, Unique Sentence Count 21873.
提供机构:
rifat101
搜集汇总
数据集介绍
构建方式
BnSentMix数据集源自社交媒体与电商平台,涵盖Facebook、YouTube及在线购物网站的评论文本,共计两万条样本。数据采集后,采用多语言BERT模型进行自动化清洗与初步过滤,以去除噪声及非相关内容。随后,邀请64名标注者对每条样本进行情感标注,每位样本至少由两人独立标注,若出现分歧则引入第三人裁决,最终确立积极、消极、中立与混合四类情感标签,确保了标注的一致性与可靠性。
特点
该数据集最大的特色在于其语言混杂性,融合了孟加拉语与英语的代码混合现象,真实反映了孟加拉语社群在数字平台上的自然语言使用习惯。样本长度与词汇量分布广泛,平均字符长度约63字,词汇总量高达37734个,展现了丰富的语言多样性。情感标签不仅包含常规的积极、消极与中立,还引入了混合情感类别,能够捕捉更细腻的情感表达,为细粒度情感分析研究提供了独特资源。
使用方法
BnSentMix作为文本分类数据集,适用于情感分析任务的模型训练与评估。研究者可直接加载该数据集,加载后每条样本包含文本内容与对应的情感标签。推荐使用预训练的多语言或孟加拉语-英语双语语言模型进行微调,以充分利用其代码混合特性。数据集已划分好训练与测试集,便于直接用于监督学习,也可作为基准测试集,评估模型在低资源语言混合场景下的情感理解能力。
背景与挑战
背景概述
在情感分析领域,多语种及代码混合数据集的匮乏长期制约着低资源语言的研究进展。BnSentMix数据集由Sadia Alam等研究者于2025年提出,旨在填补孟加拉语-英语代码混合情感分析的数据空白。该数据集汇集了来自Facebook、YouTube和电子商务网站的20,000条样本,通过基于mBERT的自动化过滤与64位标注者的双重验证,确保了标签的可靠性。作为首个大规模孟加拉语-英语代码混合情感分析数据集,BnSentMix为跨语言情感理解、多语种自然语言处理等研究提供了关键基准,显著推动了低资源语言在情感计算领域的发展。
当前挑战
BnSentMix所解决的领域挑战主要集中在代码混合文本的情感分析上,这类文本因语言交替、语法混杂而难以被传统模型有效处理。在构建过程中,研究者面临多重困难:首先,从非结构化社交媒体和电商平台收集的原始数据存在大量噪声,需设计自动化过滤流程以剔除无关内容;其次,确保64位标注者之间的一致性是一项挑战,尤其当样本出现标签平局时,需引入第三方仲裁;最后,数据长度分布极不均衡(短句仅14字符,长句达1985字符),这对后续模型训练的鲁棒性提出了额外要求。
常用场景
经典使用场景
BnSentMix数据集专为孟加拉语-英语代码混合文本的情感分析任务而设计,广泛应用于多语言自然语言处理研究。该数据集包含20,000条从Facebook、YouTube和电子商务网站采集的样本,每条文本均标注为积极、消极、中立或混合四类情感。其核心使用场景在于训练和评估能够处理代码混合语言的情感分类模型,例如基于mBERT的预训练模型微调,从而提升对孟加拉语和英语混杂表达的情感识别能力。研究者常利用该数据集探索跨语言情感分析、低资源语言建模以及代码混合文本的语义理解,其多样化的数据来源和标注策略确保了模型的泛化性与鲁棒性。
实际应用
在实际应用中,BnSentMix数据集助力构建面向孟加拉国及南亚地区的社交媒体监控系统和电商评论分析工具。企业可借助基于该数据集训练的模型自动识别用户对产品、服务或公共事件的情感倾向,例如追踪Facebook上关于品牌话题的积极或消极反馈,或分析YouTube评论中混合语言的情绪波动。此外,该数据集还支持政府和非政府组织监测公共卫生或社会运动中的公众情绪,尤其适用于孟加拉语和英语混杂的在线社区,从而为舆情预警和决策支持提供技术基础。
衍生相关工作
BnSentMix数据集衍生了一系列相关经典工作,包括代码混合语言情感分析的基准评估和多模型比较研究。领域内研究者基于该数据集开发了针对孟加拉语-英语的预训练语言模型微调策略,如BanglaBERT和XLM-R的适配版本,并探索了对抗训练、数据增强等技术以提升模型鲁棒性。此外,该数据集还催生了跨语言情感迁移学习的研究,例如将BnSentMix与英文情感数据集联合训练,验证了低资源到高资源语言的迁移效果。这些工作多发表在ACL等顶会Workshop中,促进了低资源语言自然语言处理社区的协作与创新。
以上内容由遇见数据集搜集并总结生成


