prachuryyaIITG/FiNERVINER
收藏Hugging Face2026-05-02 更新2026-03-29 收录
下载链接:
https://hf-mirror.com/datasets/prachuryyaIITG/FiNERVINER
下载链接
链接失效反馈官方服务:
资源简介:
FiNERVINER是一个高质量的细粒度命名实体识别数据集,专为印度东北部地区的脆弱语言创建,采用注释投影方法构建。包含的语言有:博多语(brx)、米佐语(lus)和曼尼普尔语(mni)。数据集分为训练集、开发集和测试集,并提供了详细的统计数据和注释者间一致性(IAA)分数。该数据集是AWED-FiNER生态系统的一部分,提供了示例用法和引用信息。
FiNERVINER is a high-quality fine-grained named entity recognition dataset created through annotation projection method for vulnerable languages of Indias North Eastern Region. The languages included are: Bodo (brx), Mizo (lus), and Manipuri (mni). The dataset is divided into train, development, and test sets, with detailed statistics and Inter-Annotator Agreement (IAA) scores provided. It is part of the AWED-FiNER ecosystem and includes sample usage and citation information.
提供机构:
prachuryyaIITG
搜集汇总
数据集介绍
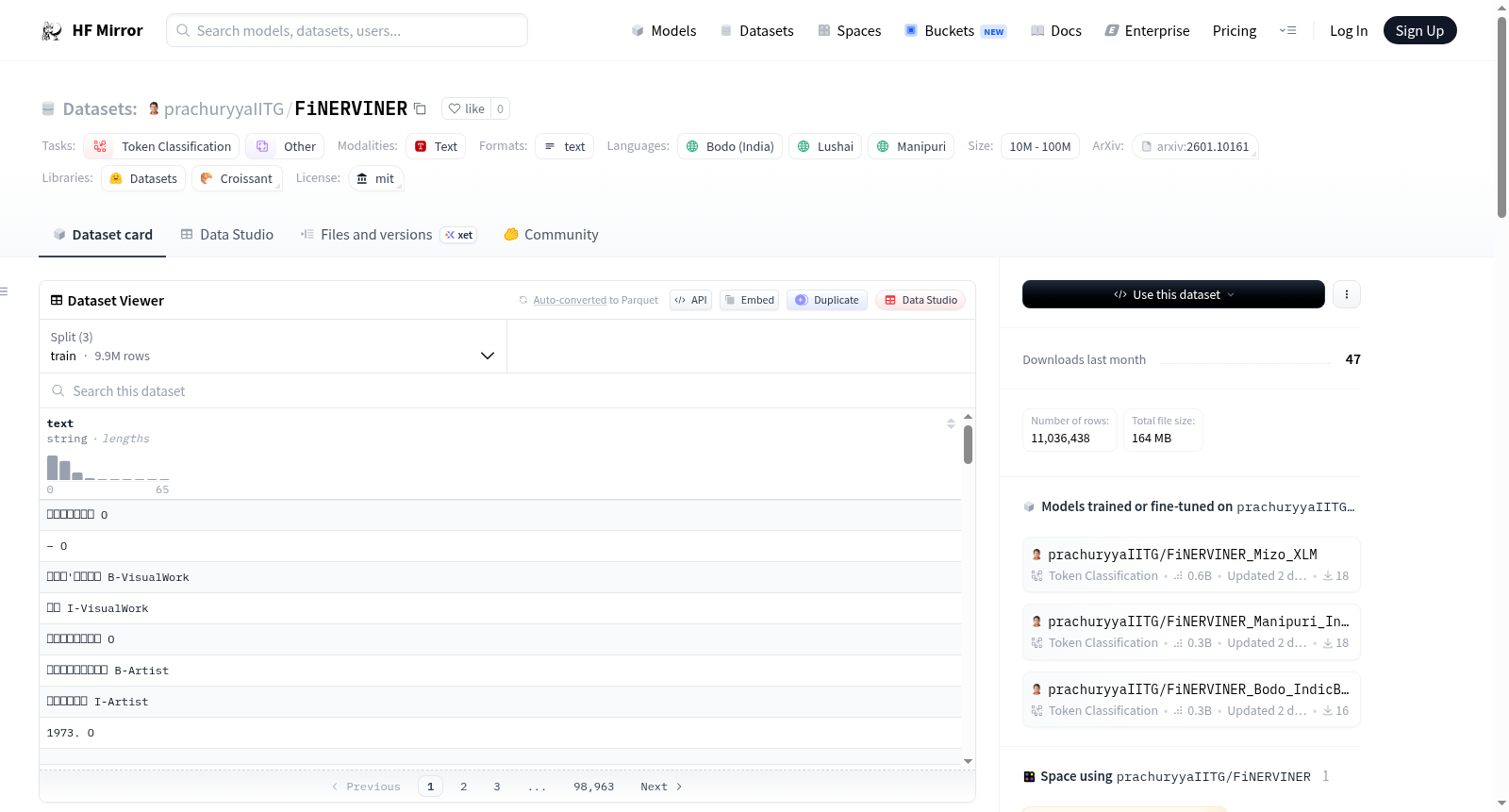
构建方式
FiNERVINER数据集采用注释投影方法构建,专门针对印度东北地区的三种脆弱语言——博多语、米佐语和曼尼普尔语。通过从高资源语言中迁移标注信息,结合跨语言对齐技术,该数据集在保持细粒度实体类别的同时,有效解决了低资源语言缺乏标注数据的问题。最终形成了包含训练集、开发集和测试集的完整数据划分,确保模型训练的可行性与评估的可靠性。
特点
该数据集的核心特点在于其高标注质量和精细的实体类别体系。三种语言的测试集均经过独立人工验证,标注者间一致性系数达到0.8以上(Cohen's κ),反映了标注结果的高度可靠性。数据集规模庞大,博多语、米佐语和曼尼普尔语的训练集分别包含21万、17万和24万句,实体数量均超过25万,为训练鲁棒的命名实体识别模型提供了充足的数据基础。
使用方法
FiNERVINER数据集可集成于AWED-FiNER智能体框架中使用。用户通过HuggingFace模型库加载预训练的专家模型,利用smolagents库中的CodeAgent和AWEDFiNERTool工具,即可对目标语言的文本进行细粒度命名实体识别。例如,输入博多语句子后,智能体将自动调用相应的专业模型完成实体抽取,无需手动配置语言或模型参数,极大简化了使用流程。
背景与挑战
背景概述
在自然语言处理领域,命名实体识别(NER)是信息抽取的核心任务之一,然而全球诸多语言,尤其是低资源语言,因其缺乏大规模高质量标注数据而长期处于研究边缘。针对这一困境,来自印度理工学院古瓦哈提分校的Prachuryya Kaushik与Ashish Anand教授于2026年构建了FiNERVINER数据集,旨在解决印度东北地区三种弱势语言——博多语(Bodo)、米佐语(Mizo)和曼尼普尔语(Manipuri)的细粒度命名实体识别问题。该数据集通过注释投影方法创建,总计包含超过63万条句子与近百万实体标注,其测试集的注释者间一致性(Cohen's κ)均达到0.81以上,展现了卓越的标注质量。作为AWED-FiNER生态系统的重要组成部分,FiNERVINER不仅为这些语言提供了首个细粒度NER资源,更为全球语言多样性保护与多语言AI研究树立了重要标杆。
当前挑战
FiNERVINER所解决的领域核心挑战在于,印度东北地区语言的弱势地位导致其缺乏基础标注资源,传统的NER系统在面对这些稀缺语料时性能急剧下降。数据集构建过程中面临两大关键难题:其一,由于这些语言均属于低资源语系,既无可直接利用的标注银行,也难以依靠人工大规模注释,研究团队不得不设计并采用创新的投影方法,将高资源语言的标注信息映射至目标语言,这要求算法能有效跨语言对齐实体边界与类别。其二,细粒度NER的实体类别划分较通用NER更为精细,在投影过程中易产生歧义与噪声,从而降低标注一致性;为应对此挑战,团队在后处理阶段引入了双重质检机制,确保最终数据集的IAA得分维持在0.8以上的高置信区间。
常用场景
经典使用场景
FiNERVINER作为面向印度东北部弱势语言的细粒度命名实体识别数据集,其经典使用场景聚焦于支撑低资源语言的序列标注任务。研究人员可基于该数据集训练和评估NER模型,精准识别博多语、米佐语和曼尼普尔语中的预定义实体类别。该数据集采用注释投影方法构建,确保标注质量和跨语言一致性,为模型在缺乏语法资源或大规模标注语料的情境下进行实体边界和类型预测提供了可靠基准,是推动弱势语言信息抽取研究的关键资源。
实际应用
在实际应用中,FiNERVINER支撑了面向印度东北部多语种社区的信息提取系统。它可用于自动化构建数字人文语料库,帮助整理地方语言文献中的地名、人名和组织机构信息。在公共安全与应急管理场景中,模型可从社交媒体或新闻报道中实时抽取关键实体,辅助灾害预警和舆情监测。此外,该数据集还为机器翻译和语音识别系统提供实体标注基准,促进从文本到语音的多模态应用落地,赋能约一千万母语使用者获取数字服务。
衍生相关工作
FiNERVINER催生了一系列相关研究,其中最突出的是AWED-FiNER生态系统,它整合了基于专家检测器的细粒度NER框架,并提供了交互式演示界面。研究者还以此为基础扩展至SampurNER——涵盖22种印度语言的细粒度NER数据集,发表于AAAI 2026。利用AWED-FiNER的智能体工具,学界得以开发跨36种语言、覆盖66亿母语者的通用NER系统。这些工作共同构建了从弱势语言基础资源到大规模多语言应用的完整研究链,推动了低资源NER的标准化和可复现性。
以上内容由遇见数据集搜集并总结生成


