Reddit Health Online Talk (RedHOT)
收藏arXiv2023-02-08 更新2024-06-21 收录
下载链接:
https://sominw.com/redhot
下载链接
链接失效反馈官方服务:
资源简介:
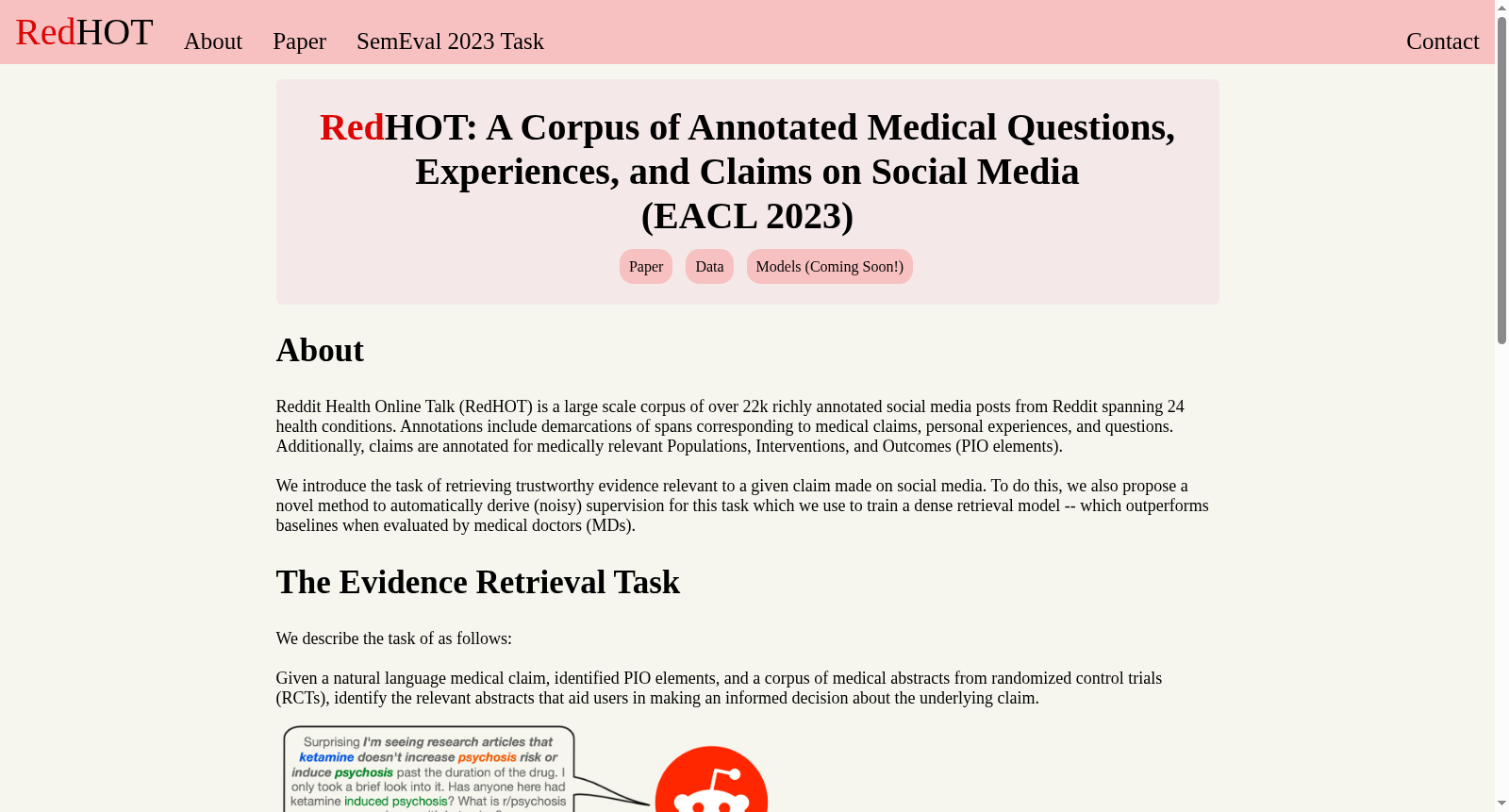
Reddit Health Online Talk (RedHOT) 是一个包含22,000条来自Reddit的丰富标注社交媒体帖子的数据集,涵盖24种健康状况。该数据集由东北大学的研究团队创建,旨在支持处理健康相关社交媒体帖子的模型开发。数据集中的帖子不仅标注了医疗声明、个人经历和问题,还进一步对识别的声明进行了细粒度标注,如患者群体、干预措施和结果(PIO元素)。RedHOT数据集的应用领域包括帮助社区管理员识别和移除含有医疗错误信息的帖子,以及为个人健康决策提供相关背景证据。
Reddit Health Online Talk (RedHOT) is a richly annotated social media post dataset containing 22,000 posts sourced from Reddit, covering 24 health conditions. This dataset was created by a research team from Northeastern University to support the development of models for processing health-related social media posts. Posts in the dataset are not only annotated with medical claims, personal experiences and questions, but also carry fine-grained annotations for the identified claims, such as Patient Population, Intervention, and Outcome (PIO elements). Application scenarios of the RedHOT dataset include assisting community moderators in identifying and removing posts containing medical misinformation, as well as providing relevant contextual evidence for personal health decision-making.
提供机构:
东北大学
创建时间:
2022-10-12
搜集汇总
数据集介绍
构建方式
RedHOT数据集从Reddit平台上的24个健康相关子版块中采集了约22,000条帖子,覆盖从常见到罕见的多种疾病。数据标注分为两个阶段:首先,众包工作者标记文本中的声明、个人经历和问题三类跨度;其次,对纯声明进一步标注人群、干预措施和结局(PIO)要素。标注通过Amazon Mechanical Turk完成,每篇帖子至少由三名工作者标注,最终通过多数投票聚合标签,并辅以专家内部标注进行质量验证。
使用方法
RedHOT可支持多种下游任务,核心应用包括三步流程:首先,利用序列标注模型(如BERT或CRF)识别帖子中的声明、问题和经历;其次,从声明中提取PIO元素;最后,基于提取的PIO和原始帖子,训练密集检索模型(如RedHOT-DER)从Trialstreamer数据库中检索相关临床证据。数据集以脚本形式发布,允许用户按需下载并匹配标注,同时要求研究者获得机构审查委员会批准后使用。
背景与挑战
背景概述
在社交媒体日益成为公众获取健康信息重要渠道的背景下,Reddit等平台为用户提供了讨论罕见疾病、分享治疗经验与症状轨迹的空间。然而,这些未经专业审核的内容也极易滋生医疗 misinformation,对公共卫生构成潜在威胁。为应对这一挑战,美国东北大学与埃森哲人工智能实验室的研究人员于2022年共同推出了Reddit Health Online Talk(RedHOT)数据集。该数据集精选了涵盖24种健康状况的约22,000条Reddit帖子,并对其中的医疗主张、个人经验与问题进行了精细标注。RedHOT的诞生填补了现有健康类社交媒体语料库在主题广度和自然语言真实性方面的空白,为开发自动识别与验证医疗主张的语言技术提供了关键资源,对推动医学信息学与自然语言处理领域的交叉研究具有里程碑式意义。
当前挑战
RedHOT数据集面临的首要挑战是医疗 misinformation 的自动识别与可信证据检索。社交媒体上大量未经证实的因果主张(如声称某种干预措施可治愈特定疾病)需要被精准定位,并关联到随机对照试验等权威医学文献,以支持或驳斥其真实性。然而,现有检索模型常因候选文献数量庞大且语义重叠而性能受限。其次,数据构建过程亦充满困难:非专业众包工作者对复杂医学术语的标注一致性较低,导致噪声数据难以完全消除;同时,为训练密集检索模型而生成的伪标注数据可能引入系统性偏差,使模型在真实场景中的泛化能力受到制约。此外,跨24种健康状况的标注范围虽广,但英语单一语种与有限社区样本的选择仍限制了数据集的代表性。
常用场景
经典使用场景
RedHOT数据集为社交媒体健康文本的细粒度语义解析提供了重要资源。在自然语言处理领域,研究者常利用该数据集训练序列标注模型,以精准识别Reddit帖子中蕴含的医疗主张、个人经验与疑问三类信息单元。其经典使用场景聚焦于从非结构化用户生成内容中抽取因果关系陈述,例如区分“纯主张”(如“某种干预可治愈某疾病”)与基于个人经历的主张,从而为后续的医学信息可信度评估奠定基础。
解决学术问题
该数据集系统性地解决了社交媒体中健康信息混杂带来的学术挑战。通过提供覆盖24种健康状况的22000条标注帖子,RedHOT使研究者能够建模医疗主张的自动检测与结构化解析,尤其针对PIO元素(人群、干预、结局)的抽取。这填补了现有语料库覆盖范围窄、缺乏自然主张标注的空白,推动了从社交平台中自动提取可验证医学声明的研究,为大规模健康谣言识别与证据检索提供了关键基准。
实际应用
在实际应用中,RedHOT支持构建辅助内容审核的工具,帮助社区管理员快速识别并标记可能包含医疗误导的帖子。例如,系统可自动提取用户声称的“某药物导致某症状”的主张,并检索相关临床试验摘要进行比对。此外,该数据集可用于开发面向患者的健康信息导航系统,通过区分个人经验与客观主张,降低普通用户被不实医疗信息误导的风险,提升在线健康社区的公共信任度。
数据集最近研究
最新研究方向
在社交媒体健康信息日益成为公众决策重要参考的背景下,RedHOT数据集聚焦于从Reddit平台提取并标注医疗主张、个人经验与疑问,尤其关注其中隐含的因果关系。当前前沿研究围绕该数据集展开的多模态信息验证与证据检索任务,紧密关联社交媒体虚假健康信息泛滥的热点事件,例如疫情期间未经证实的疗法传播。通过引入PIO元素(人群、干预、结局)的细粒度标注,RedHOT推动了从非结构化用户生成内容中自动识别医疗主张并匹配可信临床试验证据的技术发展,其意义在于为内容审核与公共卫生信息治理提供可扩展的基准工具,助力遏制误导性健康信息的扩散。
相关研究论文
- 1RedHOT: A Corpus of Annotated Medical Questions, Experiences, and Claims on Social Media东北大学 · 2023年
以上内容由遇见数据集搜集并总结生成


