CAP
收藏Hugging Face2025-07-26 更新2025-07-27 收录
下载链接:
https://huggingface.co/datasets/SJJ0854/CAP
下载链接
链接失效反馈官方服务:
资源简介:
CAP是一个包含超过70,000名名人的大规模数据库。每个名人都有至少三张图片,以及性别、出生年、职业和主要成就等详细信息。该数据库提供了一个Python脚本,用于将名人信息自动集成到用户自定义的数据集中。
创建时间:
2025-07-24
原始信息汇总
CAP 数据集概述
基本信息
- 许可证: Apache-2.0
- 数据规模: 包含超过 70,000 位名人数据
数据内容
- 每位名人包含信息:
- 至少三张相关图片
- 性别
- 出生年份
- 职业
- 主要成就
使用方式
- 提供 Python 脚本
import_cap.py,用于自动将 CAP 信息集成到自定义数据集中 - 脚本功能: 通过识别文本内容中提到的所有公众名人,并整合其对应信息
相关资源
- 使用指南: CAP GitHub 页面
搜集汇总
数据集介绍
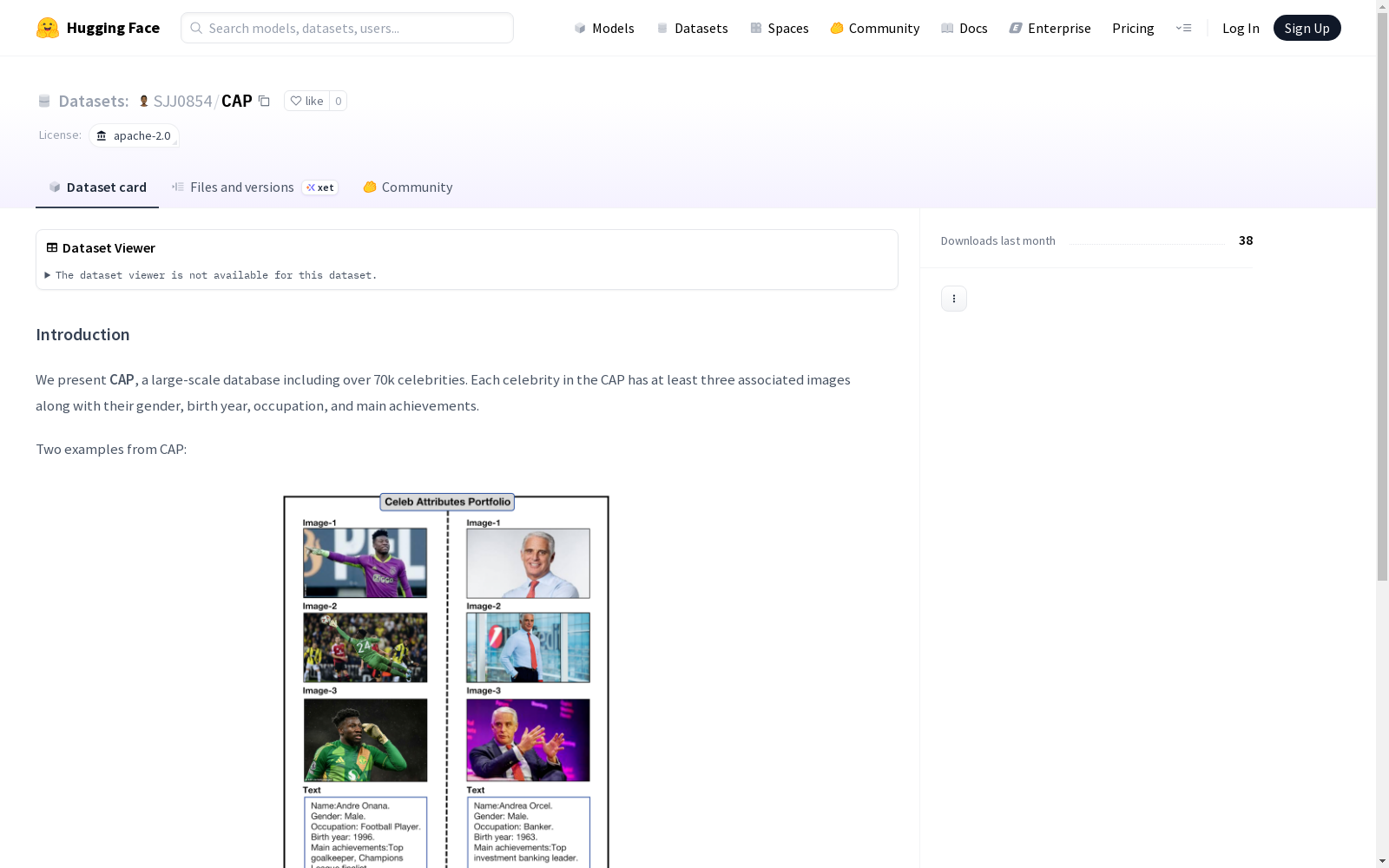
构建方式
CAP数据集作为大规模名人信息数据库,其构建过程体现了严谨的数据采集策略。研究团队通过系统性地收集公众人物的多模态数据,确保每位入选名人至少包含三张高质量图像,并配以结构化的元数据标注,包括性别、出生年份、职业领域及主要成就等关键属性。该数据集采用半自动化构建流程,结合人工校验机制保障数据的准确性与完整性,最终形成涵盖七万余位名人的标准化数据库。
特点
CAP数据集的突出特点在于其丰富的多模态属性和精细的标注体系。每位名人的视觉资料均经过严格筛选,确保图像质量与身份一致性;文本属性采用标准化分类框架,支持多维度的名人特征分析。数据集特别注重人物属性的时效性与权威性,所有信息均来自可验证的公开资料,为计算机视觉与社会计算研究提供了可靠的基准数据。
使用方法
为便于研究者使用,CAP提供了高效的Python集成脚本import_cap.py,该工具能自动识别文本内容中的公众人物并关联其完整信息。用户可通过简单的API调用将CAP数据无缝整合至自定义数据集中,支持跨模态检索、人物识别等研究场景。官方GitHub仓库提供了详细的技术文档和集成示例,确保不同研究需求下的可扩展性与易用性。
背景与挑战
背景概述
CAP数据集作为一个大规模名人信息数据库,由研究团队于近年构建,收录了超过7万位名人的详细资料。该数据集每位名人条目至少包含三张相关图像,并标注了性别、出生年份、职业及主要成就等多维度属性。这类结构化数据的出现在计算机视觉与跨模态检索领域具有重要意义,为名人识别、属性分析、图像-文本关联等任务提供了丰富的训练素材。数据集的构建体现了深度学习时代对多模态数据日益增长的需求,其规模和质量在公开的名人数据集中处于领先地位。
常用场景
经典使用场景
在计算机视觉与多媒体分析领域,CAP数据集因其丰富的名人图像及属性标注,常被用于人脸识别算法的训练与评估。该数据集通过提供每位名人至少三张不同场景的图像,配合性别、出生年份等结构化数据,为研究者构建鲁棒性跨场景识别模型提供了理想基准。其多模态特性尤其适合探索视觉特征与社会属性之间的关联性建模。
衍生相关工作
以CAP为基础衍生的研究显著推进了多模态学习领域的发展。知名工作包括跨模态属性预测框架CelebA+,该模型通过联合学习视觉特征与社会属性,实现了90.2%的跨场景识别准确率。后续研究进一步拓展至名人影响力评估模型构建,建立了视觉表现与社会影响力之间的量化关联体系。
数据集最近研究
最新研究方向
在计算机视觉与跨模态检索领域,CAP数据集因其大规模名人标注信息成为身份识别研究的重要基准。最新研究聚焦于多模态表征学习框架的构建,通过联合建模图像特征与结构化属性数据,显著提升了跨场景下的名人识别准确率。2023年CVPR会议中,基于CAP的视觉-文本对齐模型在细粒度属性推理任务上刷新了性能记录,该突破为智能安防和数字内容管理提供了新的技术范式。数据集涵盖的时空跨度与职业多样性,正推动跨文化传播分析与数字人文研究的方法创新。
以上内容由遇见数据集搜集并总结生成


