high_quality_open_web_content
收藏Hugging Face2024-10-10 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/RSS3-Network/high_quality_open_web_content
下载链接
链接失效反馈官方服务:
资源简介:
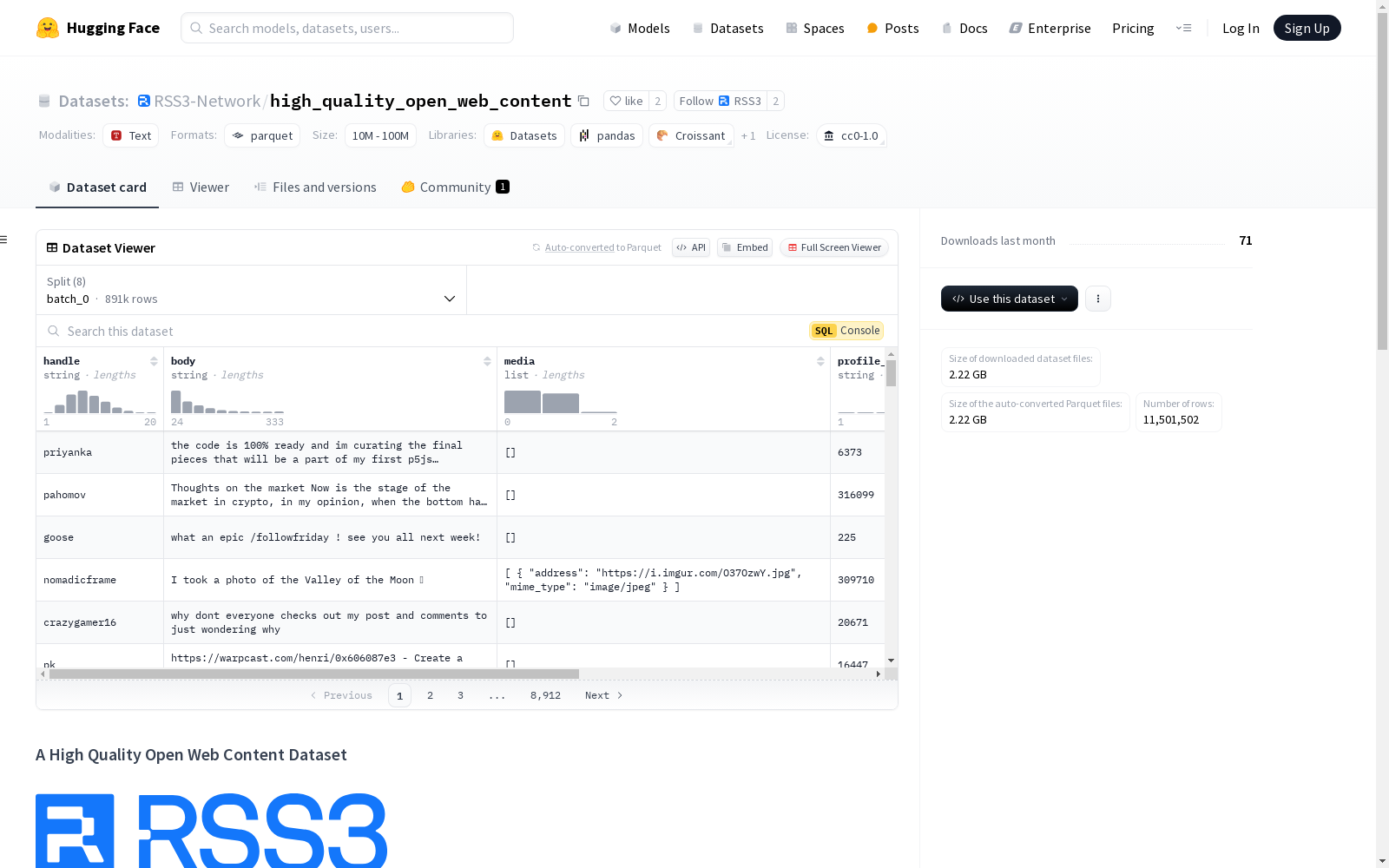
该数据集由RSS3网络策划,包含来自多个去中心化平台(如Farcaster和Lens)的大量内容。数据集由RSS3节点结构化和索引,并以结构化格式提供,便于访问和分析。数据集包含字段如作者的handle、帖子内容、媒体(包括媒体地址和MIME类型)、作者的profile_id、帖子的publication_id和时间戳。数据集分为多个批次,具有不同的数据大小和示例数量。该数据集采用CC0 1.0许可证,允许无限制使用,包括商业用途。内容归各自作者和平台所有,并以去中心化的方式提供,访问不受限制。
创建时间:
2024-10-09
原始信息汇总
高质量开放网络内容数据集
数据集概述
该数据集由RSS3网络策划,包含来自多个去中心化平台(如Farcaster和Lens)的大量内容。数据集经过RSS3节点的结构化和索引,并以结构化格式提供,便于访问和分析。
数据集字段
- handle: 作者在相应平台上的用户名。
- body: 帖子文本内容。
- media: 与帖子关联的媒体对象列表。
- address: 媒体的URL。
- mime_type: 媒体的MIME类型。
- profile_id: 作者在相应平台上的个人资料ID。
- publication_id: 帖子在相应平台上的发布ID。
- timestamp: 帖子在相应平台上的时间戳。如果不可用,则为RSS3节点索引和结构化数据的时间。
数据集配置
- config_name: default
- data_files:
- split: batch_0, path: data/batch_0-*
- split: batch_1, path: data/batch_1-*
- split: batch_2, path: data/batch_2-*
- split: batch_3, path: data/batch_3-*
- split: batch_4, path: data/batch_4-*
- split: batch_5, path: data/batch_5-*
- split: batch_6, path: data/batch_6-*
- split: batch_7, path: data/batch_7-*
数据集大小
- download_size: 2222667988 bytes
- dataset_size: 3449025521 bytes
数据集拆分
- batch_0: 220122462 bytes, 891118 examples
- batch_1: 885209133 bytes, 3000000 examples
- batch_2: 640808994 bytes, 2172208 examples
- batch_3: 924120947 bytes, 3000000 examples
- batch_4: 762173887 bytes, 2396247 examples
- batch_5: 7506223 bytes, 22735 examples
- batch_6: 335272 bytes, 842 examples
- batch_7: 8748603 bytes, 18352 examples
许可证
该数据集采用CC0 1.0许可证。
搜集汇总
数据集介绍
构建方式
该数据集由RSS3网络精心构建,汇集了来自多个去中心化平台(如Farcaster和Lens)的丰富内容。通过RSS3节点的结构化处理和索引,数据集以易于访问和分析的格式呈现。所有内容均来源于RSS3网络的数据子层,确保了数据的广泛覆盖和高质量。
特点
数据集包含多个关键字段,如作者在平台上的句柄(handle)、帖子正文(body)、关联的媒体列表(media)、作者的个人资料ID(profile_id)、发布ID(publication_id)以及时间戳(timestamp)。这些字段为研究者和开发者提供了多维度的信息,便于进行深入分析和应用开发。此外,数据集还支持通过RSS3网络进行更精细的过滤和控制,增强了数据的可用性。
使用方法
该数据集适用于多种应用场景,包括但不限于微调大型语言模型、训练推荐系统等。用户可以通过HuggingFace平台直接下载数据集,或通过RSS3网络访问以获取更灵活的数据筛选选项。RSS3还提供了SDK和框架,帮助开发者构建基于该数据集的AI解决方案。数据集采用CC0 1.0许可,允许用户自由使用、修改和分发,适用于商业和非商业用途。
背景与挑战
背景概述
high_quality_open_web_content数据集由RSS3 Network精心构建,旨在收集并整理来自去中心化平台(如Farcaster和Lens)的高质量网络内容。该数据集通过RSS3节点进行结构化处理和索引,便于用户访问和分析。数据集的核心研究问题在于如何高效地从去中心化平台中提取、整理和利用开放网络内容,以支持大规模语言模型的微调、推荐系统的训练等应用。RSS3生态系统的项目已广泛利用该数据集,推动了去中心化内容在人工智能领域的应用与发展。
当前挑战
该数据集在构建过程中面临多重挑战。首先,去中心化平台的内容分布广泛且格式多样,如何高效地提取和整合这些内容是一个技术难题。其次,数据集的规模庞大,如何在不损失数据质量的前提下进行高效存储和索引也是一个关键问题。此外,由于内容来自不同的平台,确保数据的版权合规性和合法性同样具有挑战性。最后,如何在实际应用中有效利用这些数据,尤其是在训练大规模语言模型和推荐系统时,如何确保数据的多样性和代表性,也是该数据集面临的重要挑战。
常用场景
经典使用场景
在自然语言处理领域,high_quality_open_web_content数据集被广泛应用于语言模型的微调和优化。其丰富的文本内容和多样的媒体资源为研究者提供了高质量的训练数据,特别是在处理社交媒体和去中心化平台上的文本时,该数据集能够有效提升模型的上下文理解和生成能力。
实际应用
在实际应用中,high_quality_open_web_content数据集被用于构建智能推荐系统和个性化内容生成工具。例如,社交媒体平台可以利用该数据集训练推荐算法,为用户提供更精准的内容推送。同时,企业也可以基于此数据集开发定制化的语言模型,用于自动化客服和内容创作。
衍生相关工作
该数据集催生了一系列相关研究工作,特别是在去中心化平台内容分析和语言模型优化领域。例如,基于该数据集的研究成果已被应用于改进Farcaster和Lens等平台的内容推荐算法。此外,一些研究团队还利用该数据集开发了新的文本分类和情感分析模型,进一步推动了自然语言处理技术的发展。
以上内容由遇见数据集搜集并总结生成


