creole-text-voice
收藏Hugging Face2025-03-29 更新2025-03-30 收录
下载链接:
https://huggingface.co/datasets/jsbeaudry/creole-text-voice
下载链接
链接失效反馈官方服务:
资源简介:
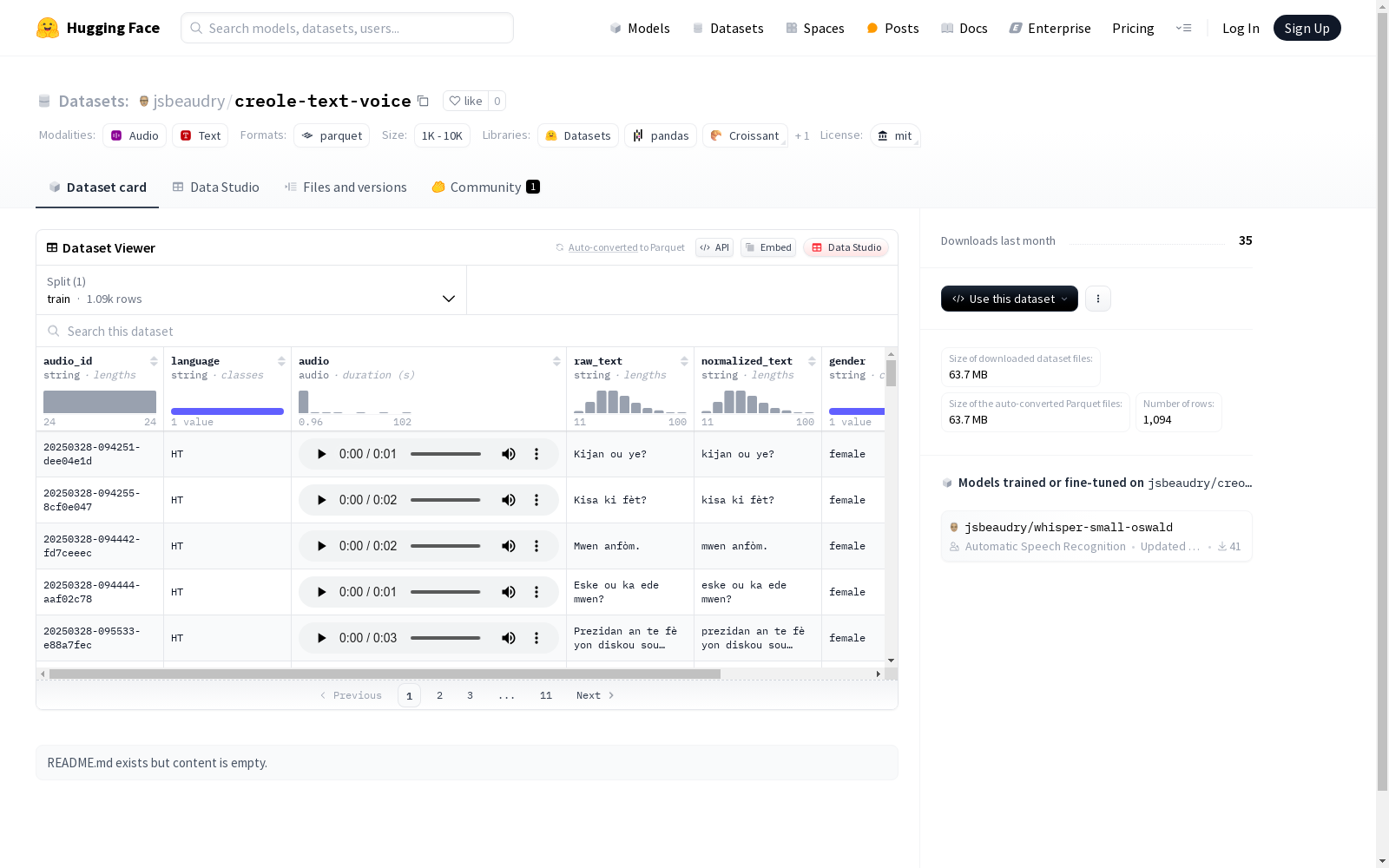
该数据集包含音频文件及其对应的文本信息,包括原始文本和标准化文本。数据集中的音频被标注了语言、性别和说话者ID。数据集仅包含训练集划分,共有1094个示例,总大小约为64026486.44字节。
创建时间:
2025-03-28
搜集汇总
数据集介绍
构建方式
在语言多样性研究领域,creole-text-voice数据集通过系统化采集克里奥尔语系的语音文本对构建而成。该数据集收录了1094条高质量语音样本,每条样本均包含原始音频文件及其对应的文本转录,并标注了语言变体、说话人ID、性别等元数据。数据采集过程严格遵循语言学规范,通过专业设备录制后经母语者校验,确保语音与文本的精确对齐。
特点
该数据集最显著的特征在于其多维度标注体系,每个样本均包含音频ID、语言类型、原始文本、归一化文本及说话人属性等结构化信息。语音数据覆盖多种克里奥尔语变体,采样率与位深度符合专业语音研究标准。文本层面对同一内容提供原始拼写与标准化拼写双版本,为研究语言变异现象提供了独特视角。说话人元数据的完整性使得该数据集特别适合口音识别和说话人特征分析任务。
使用方法
研究人员可通过HuggingFace平台直接加载数据集,其标准化的音频文件格式与文本标注可直接应用于自动语音识别(ASR)或文本转语音(TTS)系统训练。对于语言学研究,建议结合normalized_text字段分析语音文本对应关系。使用前需注意检查音频采样率与目标应用的兼容性,说话人ID字段可用于构建说话人验证任务的测试集。数据集采用MIT许可协议,允许在注明出处的前提下用于商业和非商业项目。
背景与挑战
背景概述
creole-text-voice数据集聚焦于克里奥尔语(Creole)的语音与文本对应关系研究,由国际语言技术研究团队于近年构建完成。该数据集涵盖了多种克里奥尔语变体,旨在解决低资源语言在语音识别与合成领域的数据稀缺问题。通过采集不同性别、年龄层发音人的语音样本及其对应文本标注,该资源为语言学家和人工智能研究者提供了分析克里奥尔语语音特征、开发多方言语音模型的重要基础。其跨方言的标注体系尤其促进了濒危语言的数字化保护进程,对计算语言学与人类语言学交叉研究具有显著推动作用。
当前挑战
克里奥尔语作为分散性语言族群,其语音数据收集面临方言变体复杂、发音规范不统一的固有难题。数据集构建过程中需克服录音环境噪声干扰、非标准拼写文本转写等技术障碍,同时平衡不同地域变体的样本代表性。在应用层面,该数据集需应对语音合成中声学模型对稀缺语种适应性不足的挑战,以及端到端语音识别系统处理克里奥尔语特有连读现象时的性能瓶颈问题。多说话人场景下的音色一致性控制与方言混合建模,进一步增加了基于该数据集的研究复杂性。
常用场景
经典使用场景
在语音识别与合成领域,creole-text-voice数据集因其包含多种克里奥尔语的音频与文本配对数据,成为研究低资源语言处理的宝贵资源。该数据集常用于训练跨语言的语音识别模型,特别是在克里奥尔语这类缺乏大规模标注数据的语言中,研究者通过迁移学习技术,将高资源语言的知识迁移至低资源语言场景。
实际应用
该数据集的实际价值体现在开发面向克里奥尔语地区的智能语音助手、自动字幕生成系统等应用场景。在加勒比海地区和印度洋群岛等克里奥尔语使用区域,基于该数据集构建的语音接口显著提升了医疗、教育等公共服务的信息可达性,助力消除数字鸿沟。
衍生相关工作
以creole-text-voice为基础衍生的经典工作包括克里奥尔语语音识别基准测试框架CreoleBench,以及跨语言语音合成系统CreoleTTS。这些工作不仅完善了低资源语言的技术评估体系,更催生了语音技术伦理研究中关于语言平等性的重要讨论,促进了技术普惠性研究的发展。
以上内容由遇见数据集搜集并总结生成


