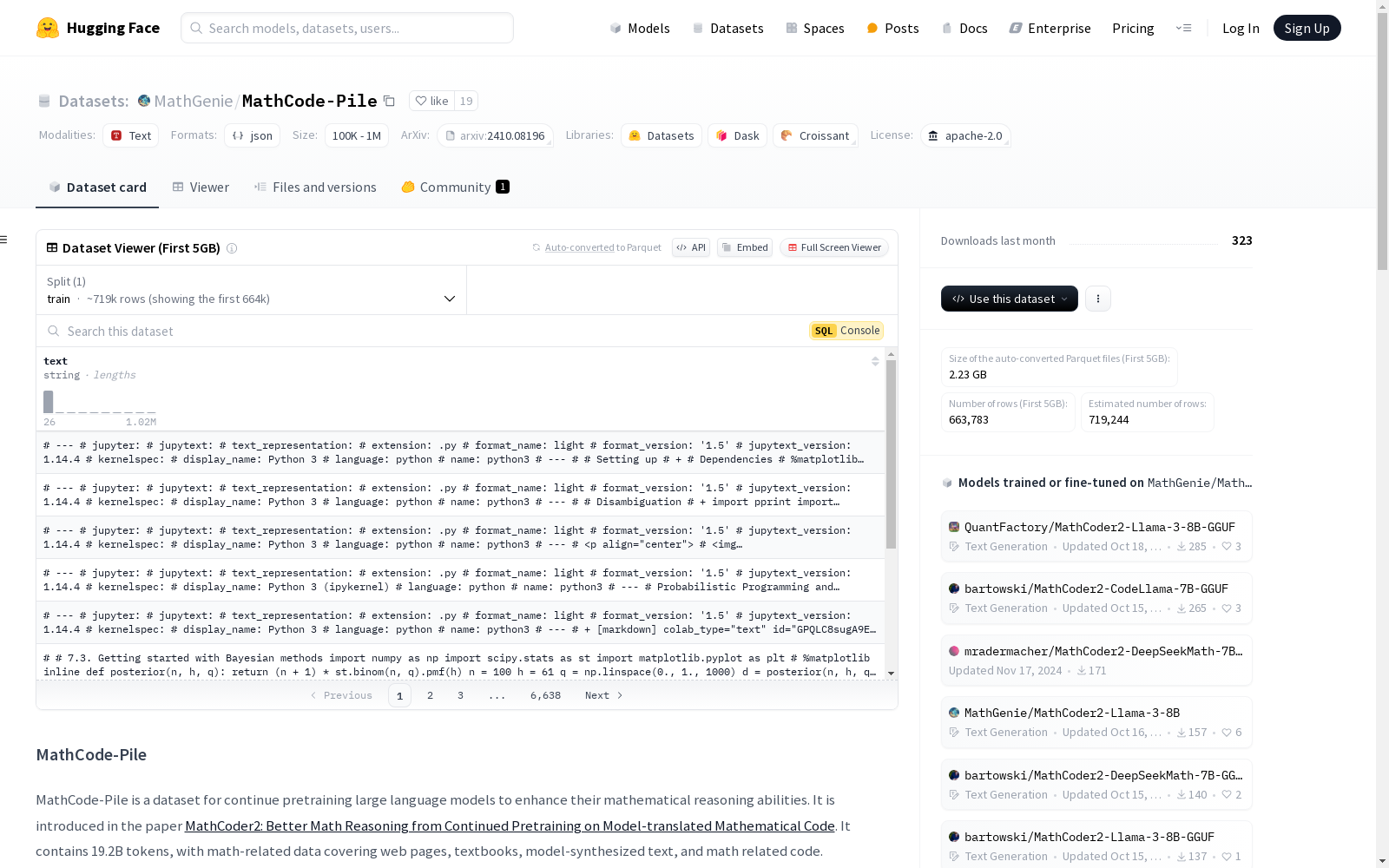
MathCode-Pile
收藏Hugging Face2024-10-11 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/MathGenie/MathCode-Pile
下载链接
链接失效反馈官方服务:
资源简介:
MathCode-Pile是一个用于继续预训练大型语言模型以增强其数学推理能力的数据集。该数据集包含19.2亿个token,涵盖了网页、教科书、模型合成的文本以及与数学相关的代码。数据集的组成部分包括过滤后的OpenWebMath、过滤后的CC-En-math和翻译后的数学代码,目前仅部分发布,其他部分已完全发布。数据集的完整版本将在论文被接受后发布,用户也可以使用数据处理代码生成完整数据集。数据集中的数学代码是通过一种新颖的方法生成的,该方法利用Llama-3.1-70B-Instruct模型提取LaTeX表达式及其相关上下文,并将其翻译成Python代码片段,最终生成包含数学推理步骤和相应代码的数据。
MathCode-Pile is a dataset designed for continued pre-training of large language models to enhance their mathematical reasoning capabilities. It contains 1.92 billion tokens, spanning webpages, textbooks, model-synthesized text, and mathematics-related code. The dataset comprises three core components: filtered OpenWebMath, filtered CC-En-math, and translated mathematical code. Currently, only a subset of the dataset has been publicly released, while the remaining portions have been fully made available. The full version of the dataset will be released upon acceptance of the associated research paper, and users can generate the complete dataset using the provided data processing code. The mathematical code within the dataset is generated through a novel methodology: this approach leverages the Llama-3.1-70B-Instruct model to extract LaTeX expressions and their associated contextual information, then translates these into Python code snippets, ultimately producing samples that incorporate both mathematical reasoning steps and their corresponding code.
创建时间:
2024-09-30
原始信息汇总
MathCode-Pile 数据集概述
数据集简介
MathCode-Pile 是一个用于继续预训练大型语言模型以增强其数学推理能力的数据集。该数据集包含 19.2B 个标记,涵盖网页、教科书、模型合成的文本以及与数学相关的代码。目前,filtered-OpenWebMath、filtered-CC-En-math 和翻译后的数学代码仅部分发布,其他部分已完全发布。完整数据集将在论文接受后发布。
数据组成
MathCode-Pile 包含广泛的数学相关数据。各部分数据集的标记数量如下表所示:

数学代码生成
提出了一种生成大量配对的数学推理步骤及其相应 Python 代码的新方法。通过精心设计的提示,指导 Llama-3.1-70B-Instruct 模型提取 LaTeX 表达式及其相关上下文,包括每个表达式的条件和计算结果。然后,模型将每个推理步骤翻译成捕捉底层推理过程的 Python 代码片段。生成的 Python 代码片段被执行,只有那些成功运行并产生预期结果的代码片段被保留。通过将代码与相应的推理步骤配对,创建最终数据。
模型性能

搜集汇总
数据集介绍
构建方式
MathCode-Pile数据集的构建旨在通过持续预训练提升大型语言模型的数学推理能力。该数据集包含192亿个标记,涵盖了网页、教科书、模型合成的文本以及数学相关代码等多种数学相关数据。其核心创新在于提出了一种新颖的方法,通过将预训练语料库中的文本片段包装在精心设计的提示中,指导Llama-3.1-70B-Instruct模型提取LaTeX表达式及其相关上下文,并将其翻译为Python代码片段。生成的代码片段经过执行验证,确保其输出与预期结果一致,最终形成包含数学推理步骤及其对应代码的配对数据。
使用方法
MathCode-Pile数据集的使用方法主要围绕持续预训练大型语言模型展开。用户可以通过加载数据集中的数学相关数据和模型生成的代码配对数据,对模型进行进一步的预训练,以提升其数学推理能力。此外,数据集的处理代码也提供了生成完整数据集的途径,用户可以根据需要自定义数据集的规模和内容。通过这种方式,MathCode-Pile不仅为研究人员提供了一个强大的工具,还为模型的数学推理能力提升提供了新的可能性。
背景与挑战
背景概述
MathCode-Pile数据集由Zimu Lu等研究人员于2024年提出,旨在通过持续预训练提升大型语言模型的数学推理能力。该数据集包含192亿个标记,涵盖了网页、教科书、模型合成文本以及数学相关代码等多种数学相关数据。其核心研究问题在于如何通过模型翻译的数学代码增强语言模型的数学推理能力。MathCode-Pile的提出为数学与代码结合的领域提供了新的研究方向,推动了大型语言模型在数学推理任务中的性能提升。
当前挑战
MathCode-Pile数据集在构建过程中面临多重挑战。首先,如何从预训练语料库中提取数学推理步骤并生成对应的Python代码是一个复杂的技术问题,需要设计精确的提示词以确保生成的代码能够准确反映数学推理过程。其次,生成的Python代码片段必须通过执行验证,确保其输出与预期结果一致,这一过程对数据质量提出了严格要求。此外,数据集的部分内容尚未完全公开,数据完整性和可访问性仍需进一步优化。这些挑战不仅影响了数据集的构建效率,也对后续研究提出了更高的技术要求。
常用场景
经典使用场景
MathCode-Pile数据集主要用于继续预训练大型语言模型,以增强其在数学推理方面的能力。通过整合来自网页、教科书、模型生成的文本以及数学相关代码的多样化数据,该数据集为模型提供了丰富的数学推理训练素材,使其在处理复杂数学问题时表现更加出色。
解决学术问题
MathCode-Pile数据集解决了大型语言模型在数学推理任务中表现不足的问题。通过引入模型翻译的数学代码和多样化的数学相关数据,该数据集显著提升了模型在数学问题求解、公式推导和代码生成等方面的能力,为数学与计算机科学的交叉研究提供了有力支持。
实际应用
在实际应用中,MathCode-Pile数据集可广泛应用于教育技术、自动化数学问题求解以及代码生成等领域。例如,基于该数据集训练的模型可以辅助学生进行数学学习,帮助开发者自动生成数学相关的代码,或为科研人员提供高效的数学问题求解工具。
数据集最近研究
最新研究方向
在数学推理与代码生成领域,MathCode-Pile数据集的推出标志着大语言模型在数学能力提升方面的新突破。该数据集通过整合网页、教科书、模型合成文本及数学相关代码,构建了一个包含192亿个令牌的庞大语料库,特别强调了数学推理步骤与其对应Python代码的配对生成。这一创新方法不仅提升了模型对数学问题的理解与解决能力,还为数学教育与自动化编程提供了新的研究视角。随着MathCoder2等研究的深入,MathCode-Pile在推动大语言模型在数学推理、代码生成及跨学科应用中的潜力逐渐显现,成为该领域前沿研究的重要基石。
以上内容由遇见数据集搜集并总结生成


