W-61/qwen3-8b-base-new-dpo-ultrafeedback-4xh200-batch-128-q_t-0.45-s_star-0.3-20260430-143919-margin
收藏Hugging Face2026-04-30 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/W-61/qwen3-8b-base-new-dpo-ultrafeedback-4xh200-batch-128-q_t-0.45-s_star-0.3-20260430-143919-margin
下载链接
链接失效反馈官方服务:
资源简介:
---
dataset_info:
features:
- name: epoch
dtype: float64
- name: step
dtype: int64
- name: batch_size
dtype: int64
- name: mean
dtype: float64
- name: std
dtype: float64
- name: min
dtype: float64
- name: p10
dtype: float64
- name: median
dtype: float64
- name: p90
dtype: float64
- name: max
dtype: float64
- name: pos_frac
dtype: float64
- name: sample
sequence: float64
- name: npy
dtype: string
splits:
- name: train
num_bytes: 606267
num_examples: 477
download_size: 507528
dataset_size: 606267
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# W-61/qwen3-8b-base-new-dpo-ultrafeedback-4xh200-batch-128-q_t-0.45-s_star-0.3-20260430-143919-margin
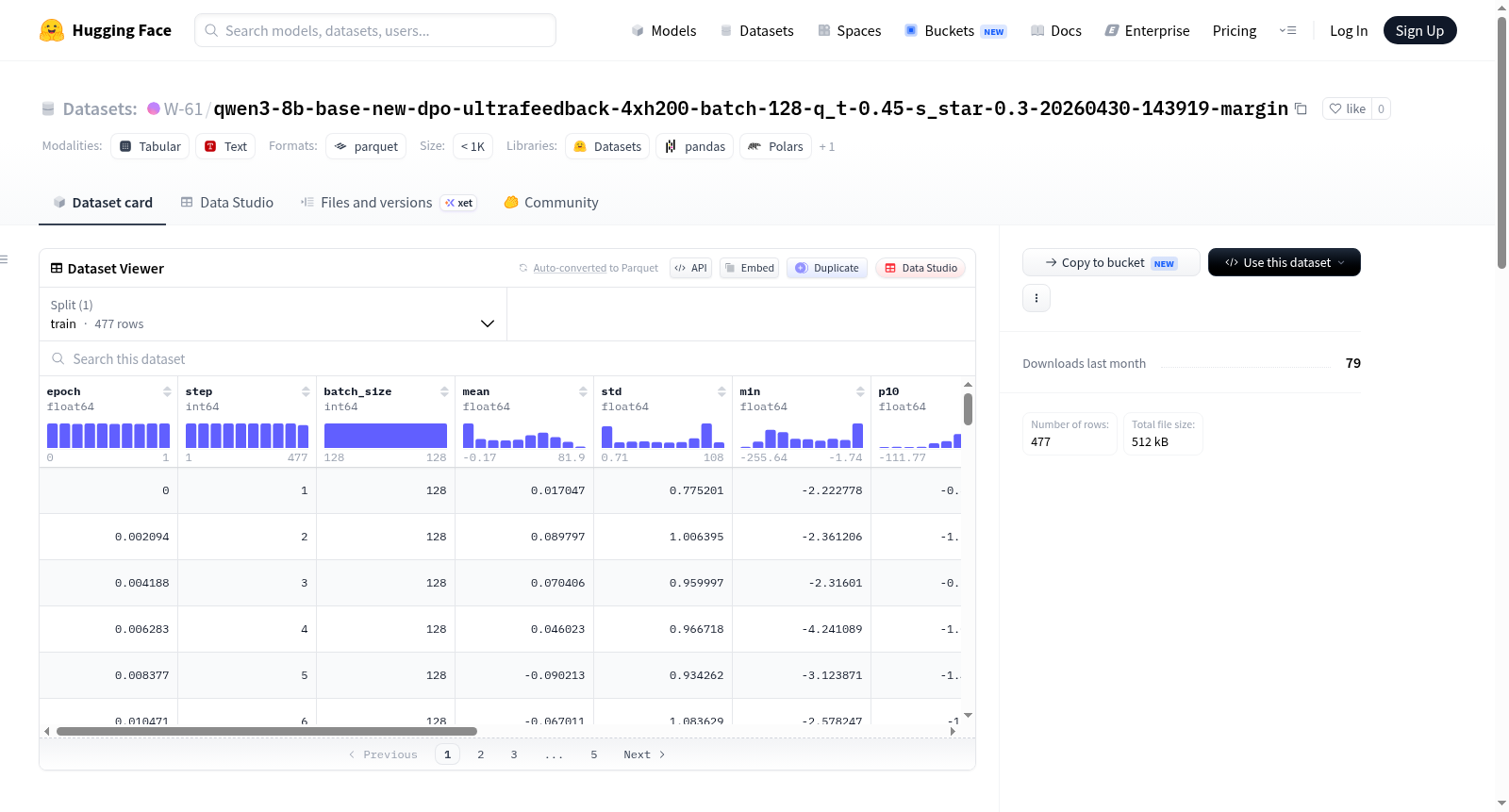
Per-step margin summary statistics exported from a New-DPO training run.
## Source Run
- Model repo id: `W-61/qwen3-8b-base-new-dpo-ultrafeedback-4xh200-batch-128-q_t-0.45-s_star-0.3-20260430-143919`
- Base model: `/workspace/dynamic-dpo-v4/base_models/qwen3-8b-base-sft-ultrachat-4xh200-batch-128`
- Training run name: `qwen3-8b-base-new-dpo-ultrafeedback-4xh200-batch-128-q_t-0.45-s_star-0.3-20260430-143919`
- W&B project: `qwen3-new-dpo-ultra-4xh200-batch-128`
- Trainer type: `new_dpo`
- Margin log path: `/workspace/dynamic-dpo-v4/outputs/qwen3-8b-base-new-dpo-ultrafeedback-4xh200-batch-128-q_t-0.45-s_star-0.3-20260430-143919/margin_logs`
- Margin log steps: `1`
- Margin save full arrays: `True`
- Published split: `train`
- Rows: `477`
## Margin Training Arguments
- beta: `0.01`
- f_divergence_type: `reverse_kl`
- f_alpha_divergence_coef: `1.0`
- s_star: `0.3`
- eta: `0.1`
- q_t (`q_target`): `0.45`
## Columns
- `epoch`
- `step`
- `batch_size`
- `mean`
- `std`
- `min`
- `p10`
- `median`
- `p90`
- `max`
- `pos_frac`
- `sample` (per-example margins for the effective batch on that logged step)
- `npy` (optional path to the saved full margin array when `margin_save_full=true`)
## Dataset Mixer
```json
{
"HuggingFaceH4/ultrafeedback_binarized": 1.0
}
```
This dataset contains per-step margin summary statistics exported from a New-DPO training run. It includes various features such as epoch, step, batch_size, mean, std, min, p10, median, p90, max, pos_frac, sample, and npy. The dataset originates from a training run with model repo ID W-61/qwen3-8b-base-new-dpo-ultrafeedback-4xh200-batch-128-q_t-0.45-s_star-0.3-20260430-143919 and uses HuggingFaceH4/ultrafeedback_binarized as the dataset mixer.
提供机构:
W-61
搜集汇总
数据集介绍
构建方式
该数据集源自对Qwen3-8B基座模型进行New-DPO训练过程的深度剖析,通过记录每一训练步中正负样本间的边际统计量而构建。具体而言,在基于UltraFeedback二值化偏好数据的训练进程中,系统以每步为间隔,将有效批次内每个样本的边际(即模型对偏好对间的对数概率差)进行采集,并计算其均值、标准差、分位数及正样本比例等统计特征。当参数配置为保存完整数组时,边际数据亦以npy格式存档,以便后续细粒度分析。训练采用4张H200 GPU、批大小为128的超参数配置,共计产生477条训练记录。
使用方法
该数据集适用于研究与分析New-DPO训练机制的领域,使用者可直接通过HuggingFace Datasets库加载。加载后,可针对不同列进行探索性数据分析,例如绘制边际均值随训练步数的变化曲线以观察收敛行为,或利用分位数列检测边际分布形态的演变。若需复现训练过程的边际谱图,可借助sample列还原原始边际向量;而npy列则提供了访问完整边际数组的路径,便于进行大规模统计或深入可视化。数据集的训练集包含477个样本,适合作为小规模实验的验证基准。
背景与挑战
背景概述
在大型语言模型(LLM)的后训练对齐领域,直接偏好优化(DPO)及其变体已成为替代强化学习从人类反馈(RLHF)的重要范式。然而,传统DPO在训练动态稳定性和奖励过拟合方面仍面临挑战。为此,Qwen团队于2025年4月30日发布了基于Qwen3-8B-Base模型进行新型DPO训练的边际统计数据集。该数据集由W-61研究机构创建,核心研究问题在于通过逐步骤的边际(margin)统计量分析,揭示新DPO训练过程中偏好差距的演化规律。该数据集记录了包含均值、标准差、百分位数及正例比例在内的477个训练步的详尽统计信息,为理解LLM对齐训练的微观动态提供了quantitative基础。其在HuggingFace上的发布,为偏好优化领域的可重复性研究提供了关键基准,并有望推动更稳定的对齐训练方法设计。
当前挑战
该数据集所解决的领域核心挑战在于传统DPO训练中奖励信号退化与训练不稳定性问题。具体而言,标准DPO缺乏对偏好差距的显式约束,易导致模型在过度优化时遗忘有益知识。新DPO通过引入边际目标函数与可控参数(如q_t=0.45、s_star=0.3)来动态调节偏好对比强度,从而缓解过拟合。在构建过程中,主要挑战包括:1)从UltraFeedback二值化数据集筛选高质量偏好对,确保训练信号可靠性;2)在4×H200 GPU环境下对8B参数模型进行128批量大小的稳定训练,平衡计算效率与损失收敛;3)对每个优化步的海量边际数值进行高效存储与聚合,定义包括百分位数在内的10项统计指标,以在压缩信息的同时保留分布形态特征,便于下游分析与可视化。
常用场景
经典使用场景
该数据集源自对通义千问3-8B基座模型进行New-DPO(新型直接偏好优化)训练的过程记录,聚焦于每一步训练中生成的‘边际统计量’(margin summary statistics)。其核心使用场景在于深度剖析与监测强化学习人类反馈(RLHF)训练的动态演化,特别是偏好优化过程中模型对正负样本区分度的变化趋势。通过分析每个训练步的均值、标准差、分位数及正样本比例等统计特征,研究者可以精准评估模型偏好的收敛状态,诊断训练稳定性问题,如边际值骤降或正样本占比异常波动,从而为超参数调优(如温度系数、KL散度系数)提供数据支撑。
解决学术问题
该数据集回应了直接偏好优化(DPO)领域一个关键却常被忽视的议题:如何在训练过程中有效度量模型偏好学习的进展与质量。传统研究多聚焦于最终性能指标,而忽略了中间过程中边际值分布所蕴藏的训练动态信息。该数据集通过系统记录每一步的边际统计量,为解决训练不稳定性、模式崩塌及奖励过度优化等经典难题提供了量化分析工具。其意义在于将偏好优化从‘黑箱’训练推向可解释、可监控的透明化流程,使得研究人员能够基于数据驱动的方法理解DPO变体的内在工作机制,极大推动了该领域实验方法论的科学化。
实际应用
在实际工业级大模型训练流水线中,该数据集可作为持续监控与智能告警的关键组件。训练团队可基于边际值序列构建自动化的训练健康度检测系统,一旦发现均值低于阈值或方差急剧扩大的异常步,立即触发回滚或自动调参流程,从而避免无效训练资源浪费。此外,该数据集的统计特征还可用于构建‘训练早期停止’策略,当正样本比例逼近1.0且边际值趋于收敛时,模型已完成有效偏好学习,及时终止训练可节省数小时的GPU算力。这一数据驱动的方法论已被多家AI实验室纳入RLHF训练的基础设施。
数据集最近研究
最新研究方向
该数据集紧扣大语言模型偏好对齐的前沿探索,聚焦于New-DPO(一种动态直接偏好优化)训练过程中的边际(margin)演化分析。通过记录Qwen3-8B基座模型经UltraFeedback数据微调后,在DPO阶段每步训练中的平均边际、分位数及正样本占比等统计量,为理解偏好优化算法的收敛动态提供了细粒度的量化视角。当前研究热点正从静态偏好对齐转向动态调控策略,例如通过调整目标优势比(q_target)与最优策略系数(s_star)来缓解奖励过拟合与多样性退化。该数据集将训练流程中477步的边际分布完整开源,极大地促进了对New-DPO中自适应温度与散度约束效果的实证检验,对构建更鲁棒、更贴合人类偏好的对话模型具有重要方法论意义。
以上内容由遇见数据集搜集并总结生成


