maveriq/DocBank
收藏Hugging Face2023-01-05 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/maveriq/DocBank
下载链接
链接失效反馈官方服务:
资源简介:
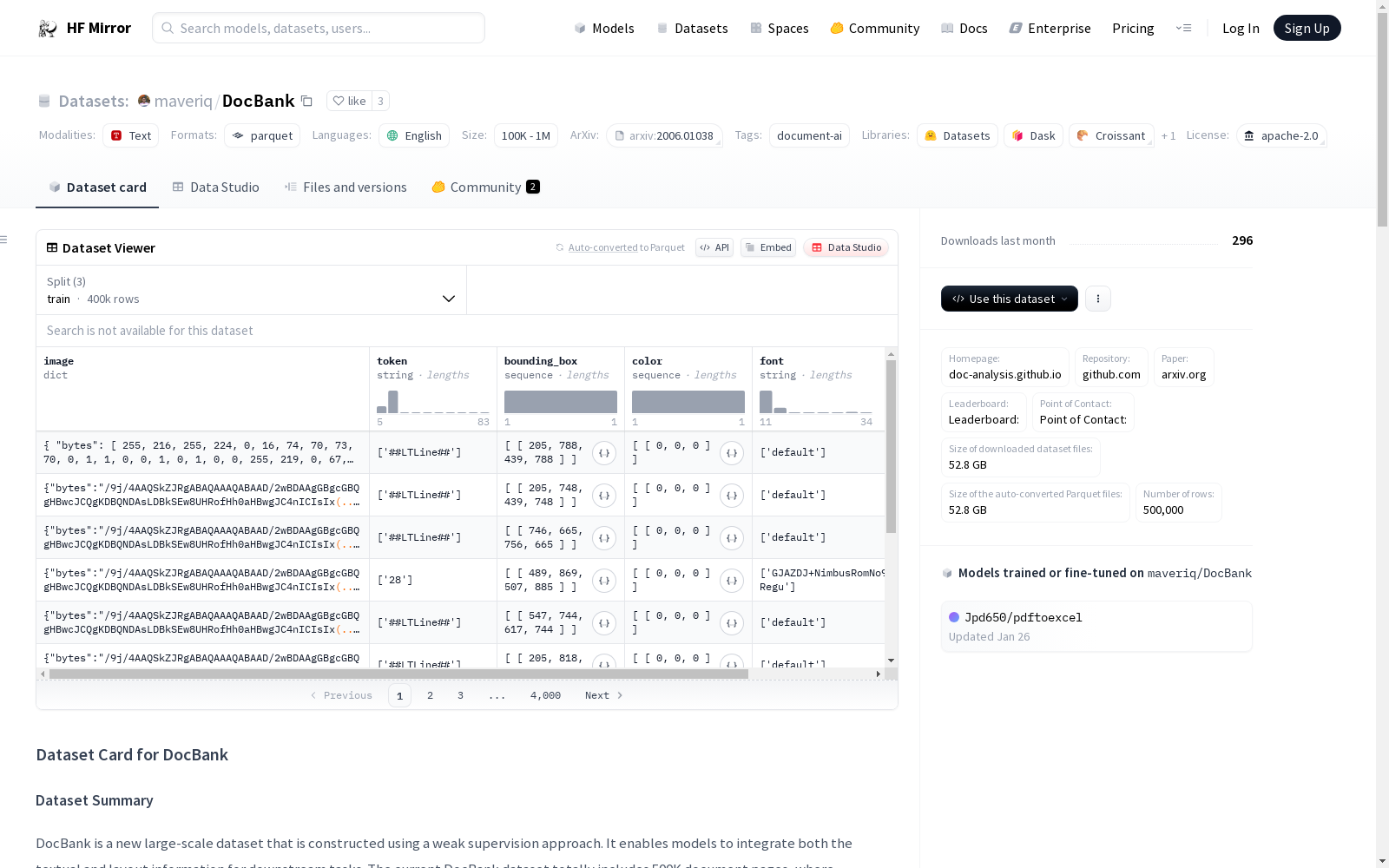
DocBank是一个新的大规模数据集,采用弱监督方法构建,旨在为下游任务提供文本和布局信息的整合。当前DocBank数据集共包含50万页文档,其中40万页用于训练,5万页用于验证,另外5万页用于测试。数据集的注释是由机器生成的,语言为英语,且数据集是单语言的。数据集的字段包括图像、令牌、边界框、颜色、字体和标签等信息。
DocBank is a novel large-scale dataset constructed via a weakly-supervised approach, which aims to provide integrated textual and layout information for downstream tasks. Currently, the DocBank dataset includes a total of 500,000 document pages, among which 400,000 pages are for training, 50,000 pages for validation, and the remaining 50,000 pages for testing. The annotations of the dataset are machine-generated, in English, and the dataset is monolingual. The dataset's fields include information such as images, tokens, bounding boxes, colors, fonts and labels.
提供机构:
maveriq
原始信息汇总
数据集概述
数据集名称
- 名称: DocBank
数据集摘要
- 摘要: DocBank是一个采用弱监督方法构建的大型数据集,旨在使模型能够整合文本和布局信息以应用于下游任务。该数据集包含500,000个文档页面,其中400,000用于训练,50,000用于验证,50,000用于测试。
支持的任务
- 任务: 文档AI(文本和布局)
语言
- 语言: 英语
数据集结构
- 数据实例: 信息待补充
- 数据字段:
- 图像(image)
- 令牌(token)
- 边界框(bounding_box)
- 颜色(color)
- 字体(font)
- 标签(label)
- 数据分割:
- 训练集: 400,000个实例
- 验证集: 50,000个实例
- 测试集: 50,000个实例
数据集创建
- 许可证: Apache 2.0
- 贡献者: @doc-analysis
引用信息
title={DocBank: A Benchmark Dataset for Document Layout Analysis}, author={Minghao Li and Yiheng Xu and Lei Cui and Shaohan Huang and Furu Wei and Zhoujun Li and Ming Zhou}, year={2020}, eprint={2006.01038}, archivePrefix={arXiv}, primaryClass={cs.CL}
搜集汇总
数据集介绍
构建方式
DocBank数据集的构建采用了弱监督学习方法,汇集了文本与布局信息,旨在为下游任务提供综合数据支持。该数据集包含500K文档页面,其中400K用于训练,50K用于验证,50K用于测试,通过这种方式实现了大规模文档数据的整合与预处理。
使用方法
使用DocBank数据集时,用户可以访问其提供的图像、文本、边界框、颜色和字体等字段,这些字段为研究和开发提供了丰富的信息。数据集分为训练集、验证集和测试集,便于进行模型训练和性能评估。用户需遵循Apache 2.0许可证的规定,合理使用和分享数据集成果。
背景与挑战
背景概述
DocBank数据集,由Minghao Li等研究人员于2020年构建,是文档布局分析领域的一项重要成果。该数据集采用弱监督学习方法,集成了文本和布局信息,为下游任务提供了有力支持。DocBank数据集总计包含500K文档页面,其中400K用于训练,50K用于验证,50K用于测试,主要应用于文档AI领域,涵盖了文本和布局两大任务。该数据集的创建,不仅丰富了文档处理领域的研究资源,也为相关领域的学者提供了新的研究方向。
当前挑战
在构建过程中,DocBank数据集面临了诸多挑战。首先,数据集的构建需要处理大量的原始数据,进行初步的数据收集和归一化处理,这对于数据处理的效率和准确性提出了较高的要求。其次,数据集的标注过程和标注者的选择也是一项重要挑战,因为这直接关系到数据集的质量和应用效果。此外,数据集中可能存在的个人敏感信息处理、偏见问题以及其他潜在局限性,都是在使用该数据集时需要考虑的重要因素。
常用场景
经典使用场景
在文档智能处理领域,DocBank数据集以其独特的弱监督构建方法,成为整合文本与布局信息进行下游任务的重要资源。该数据集广泛用于训练模型,以便更好地理解和解析文档的视觉布局与文本内容,例如,用于表格识别、文档分类和关键信息提取等任务。
解决学术问题
DocBank数据集解决了学术研究中如何高效融合文本与布局信息的问题,它通过大规模文档页面的收集和标注,为模型训练提供了丰富的学习样本。这对于提升文档解析算法的准确性和实用性具有重要意义,进一步推动了文档AI领域的发展。
实际应用
在实际应用中,DocBank数据集的应用场景遍及金融、医疗和法律等行业,它助力于自动化处理大量文档,提高工作效率,减少人工错误,对于构建智能化的文档管理系统具有显著影响。
数据集最近研究
最新研究方向
在文档智能处理领域,DocBank数据集以其大规模的文档页面和弱监督构建方法,为模型融合文本与布局信息提供了新的视角。近期研究集中于利用DocBank进行文档布局分析,以及在此基础上实现的下游任务,如信息提取、文档分类等。该数据集的推出,不仅推动了文档AI技术的发展,也为研究者在文本和视觉信息的结合上提供了丰富的实验资源,对提升模型的实际应用能力具有重要意义。
以上内容由遇见数据集搜集并总结生成


