chcp-training-data
收藏Hugging Face2026-01-21 更新2026-01-22 收录
下载链接:
https://huggingface.co/datasets/yotamabramson/chcp-training-data
下载链接
链接失效反馈官方服务:
资源简介:
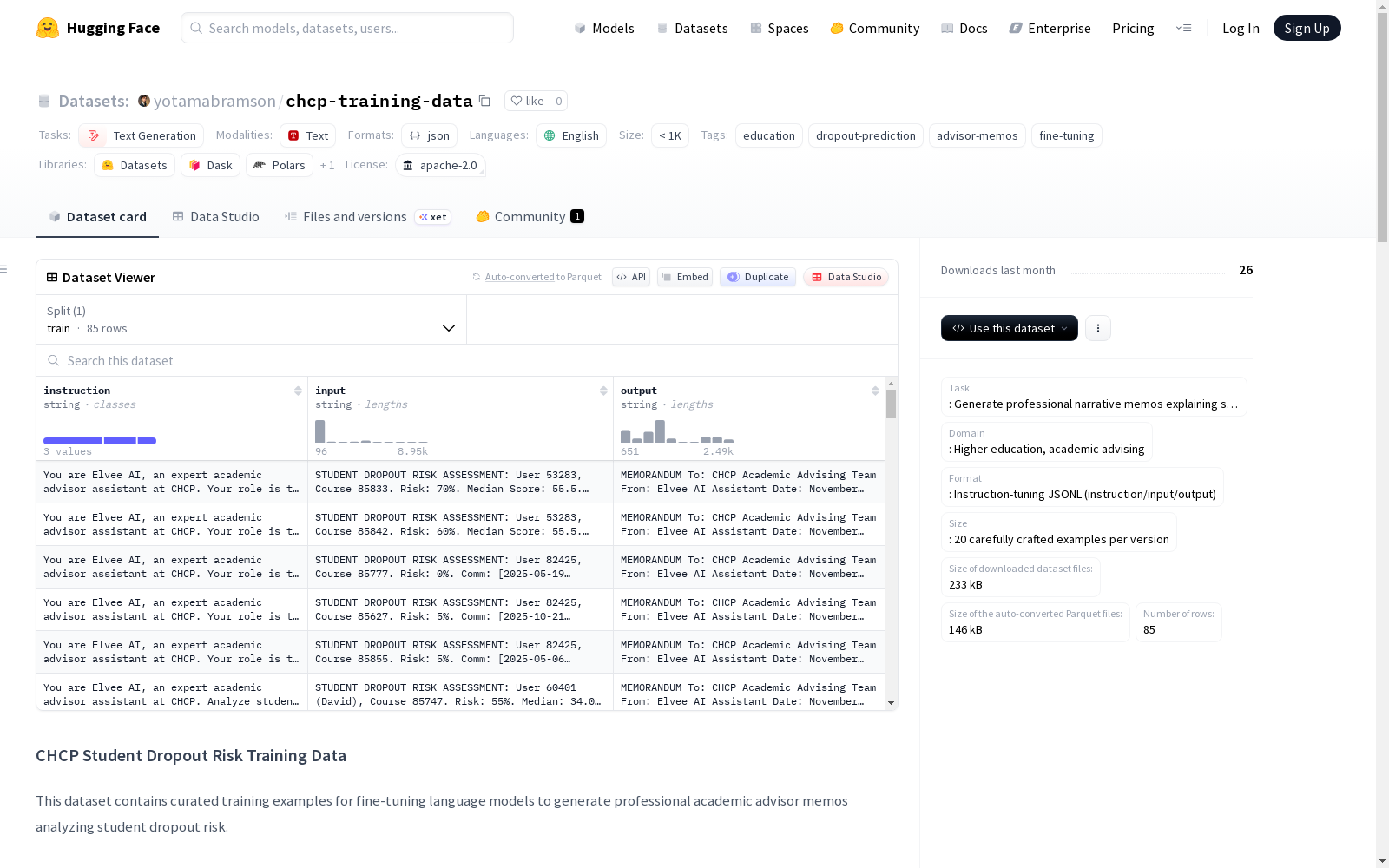
该数据集包含精心策划的训练示例,用于微调语言模型,生成专业的学术顾问备忘录,分析学生辍学风险。数据集适用于高等教育和学术咨询领域,格式为指令调优的JSONL(指令/输入/输出)。每个版本包含20个精心制作的示例。V1版本采用通用的专业备忘录格式,用于初始LoRA实验的基线训练数据;V2版本采用严格的专业叙述格式,解决了模型失败模式,是高质量的训练数据。V2版本还应用了多项约束,如不使用列表或编号项、精确引用、逻辑合成连接数据点、原型分类等。
创建时间:
2026-01-20
原始信息汇总
CHCP Student Dropout Risk Training Data 数据集概述
数据集基本信息
- 许可证: Apache 2.0
- 任务类别: 文本生成
- 语言: 英语
- 标签: 教育、辍学预测、顾问备忘录、微调
- 规模类别: n<1K
数据集描述
- 任务: 生成专业的学术顾问备忘录,用于分析学生辍学风险
- 领域: 高等教育、学术指导
- 格式: 指令微调 JSONL(指令/输入/输出)
- 规模: 每个版本包含20个精心制作的示例
版本信息
V1 - 原始数据集
- 文件:
V1/explanations_lora_V1.jsonl - 创建时间: 2025年11月
- 格式: 通用专业备忘录格式
- 用途: 用于初始LoRA实验的基线训练数据
V2 - 黄金数据集
- 文件:
V2/explanations_lora_V2.jsonl - 创建时间: 2026年1月
- 格式: 严格的专业叙述格式
- 用途: 用于解决模型失败模式的高质量训练数据
V2 应用约束:
- ✅ 无列表或编号项目 - 全部为流畅段落
- ✅ 无提示标题镜像
- ✅ 带有括号日期
[2025-11-01]的精确引用 - ✅ 连接数据点的逻辑综合
- ✅ 原型分类(静默失败者、独立学习者等)
- ✅ 一致的签名:"Elvee AI Assistant"
数据格式
每个JSONL行包含: json { "instruction": "模型的系统提示", "input": "包含通信记录的学生风险评估数据", "output": "预期的专业备忘录解释" }
使用方法
使用 Transformers/PEFT:
python from datasets import load_dataset
加载 V2(黄金数据集)
dataset = load_dataset("yotamabramson/chcp-training-data", data_dir="V2")
加载 V1(原始数据集)
dataset = load_dataset("yotamabramson/chcp-training-data", data_dir="V1")
训练 LoRA:
bash python train_lora.py --base-model Qwen/Qwen2.5-3B-Instruct --training-data yotamabramson/chcp-training-data --data-version V2 --epochs 3
模型结果
基于此数据训练的模型:
yotamabramson/chcp-qwen3b-V1- 基于V1数据训练yotamabramson/chcp-qwen3b-V2- 基于V2黄金数据集训练yotamabramson/chcp-llama8b-V2- 基于V2数据训练的Llama-8B模型
引用
如果您在研究中使用了此数据集,请引用: bibtex @dataset{chcp_training_2026, title={CHCP Student Dropout Risk Training Data}, author={[Your Name]}, year={2026}, publisher={HuggingFace}, url={https://huggingface.co/datasets/yotamabramson/chcp-training-data} }
许可证
Apache 2.0
相关链接
- 代码仓库: https://github.com/yourusername/chcp-project
- 训练模型: https://huggingface.co/yotamabramson
- 学术论文: 即将发布
搜集汇总
数据集介绍
构建方式
在高等教育领域,学生辍学风险预测是提升学术支持效能的关键课题。该数据集通过精心设计的指令调优框架构建,采用JSONL格式,每条记录均包含指令、输入与输出三个结构化字段。构建过程历经两个版本迭代:初始版本V1提供了通用专业备忘录格式的20个示例,作为基线训练数据;而优化版本V2则严格遵循专业叙事规范,消除了列表项与提示头镜像,并引入了精确的日期引用与逻辑合成,确保生成内容具备流畅的段落连贯性与统一的签名格式。
使用方法
为便于研究者高效利用该数据集,其使用方式已与主流深度学习工具链深度集成。用户可通过Hugging Face的datasets库直接加载指定版本,例如加载V2黄金数据集时仅需调用相应数据目录。在模型训练层面,数据集支持参数高效微调技术,如LoRA,用户可基于预训练模型如Qwen2.5-3B-Instruct进行多轮迭代训练。实践表明,经V2数据微调的模型在生成专业叙事备忘录方面表现显著提升,为教育技术领域的自动化顾问系统开发提供了可靠的数据基础。
背景与挑战
背景概述
在高等教育领域,学生辍学风险预测与干预是提升教育质量与公平性的核心议题。CHCP学生辍学风险训练数据集由研究人员于2025年11月至2026年1月间构建,旨在为语言模型微调提供高质量的专业学术顾问备忘录生成范例。该数据集聚焦于通过叙事性文本生成,将学生的风险评估数据转化为结构严谨、逻辑连贯的学术分析报告,从而辅助教育工作者进行精准决策。其核心研究问题在于探索如何利用生成式人工智能技术,自动化处理复杂的教育数据解释任务,推动教育咨询向数据驱动与个性化方向发展,对教育技术与学术支持系统的智能化演进具有显著影响力。
当前挑战
该数据集旨在解决高等教育中学生辍学风险分析与解释的挑战,其核心任务是从结构化的学生评估数据中生成专业、流畅且具有说服力的叙事性备忘录。这一领域问题的挑战在于模型需深度理解教育数据的内在关联,并遵循严格的学术写作规范,避免机械化罗列信息,实现数据点之间的逻辑合成与归因分析。在构建过程中,研究人员面临数据质量与格式一致性的挑战,初期版本存在列表化表述、提示头镜像等问题,后续通过引入严格的叙事格式约束、精确的引用规范以及学生原型分类,才得以构建出高质量的黄金数据集,确保生成文本的专业性与可读性。
常用场景
经典使用场景
在高等教育领域,学生流失风险预测是提升学业支持效能的关键环节。CHCP数据集通过精心构建的指令微调范例,为语言模型提供了生成专业学术顾问备忘录的标准化训练场景。该数据集最经典的使用场景在于,利用少量高质量样本对预训练模型进行参数高效微调,例如采用LoRA技术,使模型能够依据学生的风险评估数据与沟通记录,自动撰写结构严谨、逻辑连贯的叙事性分析报告,从而模拟资深顾问的决策推理过程。
解决学术问题
该数据集直接回应了教育数据科学中一个核心挑战:如何将离散的学生行为数据转化为具有解释性的专业叙事文本。它解决了传统方法在生成连贯、无列表化段落文本上的困难,通过强制模型进行逻辑合成与原型分类,推动了可控文本生成技术在教育领域的应用。其意义在于建立了从结构化数据到专业叙述的可靠映射,为研究教育领域的小样本指令微调、模型失败模式修正以及叙事生成的可解释性提供了宝贵的基准资源。
实际应用
在实际应用层面,基于此数据集训练的模型能够集成到高校的学生成功预警系统中。学术顾问或学生支持部门可利用此类模型,快速生成针对特定学生的个性化风险分析备忘录,辅助识别如‘静默失败型’或‘独立学习者’等不同学业困境原型。这不仅能提升早期干预的效率,将顾问从繁重的文书工作中解放出来,更能确保风险分析的标准化与专业性,为制定精准的学业支持策略提供数据驱动的决策依据。
数据集最近研究
最新研究方向
在高等教育与学术咨询领域,人工智能辅助学生风险预测正成为研究热点。基于CHCP学生辍学风险训练数据的最新研究,聚焦于利用指令微调技术优化语言模型生成专业咨询备忘录的能力。前沿探索方向包括通过高质量、严格格式化的V2版本数据,解决模型在合成逻辑推理、文献精确引用及学生类型分类等方面的失败模式,旨在提升模型输出的专业性与可解释性。此类研究不仅推动了教育领域大模型在细粒度文本生成任务中的应用,也为实现个性化、数据驱动的学术干预提供了关键技术支持,具有显著的实践意义。
以上内容由遇见数据集搜集并总结生成


