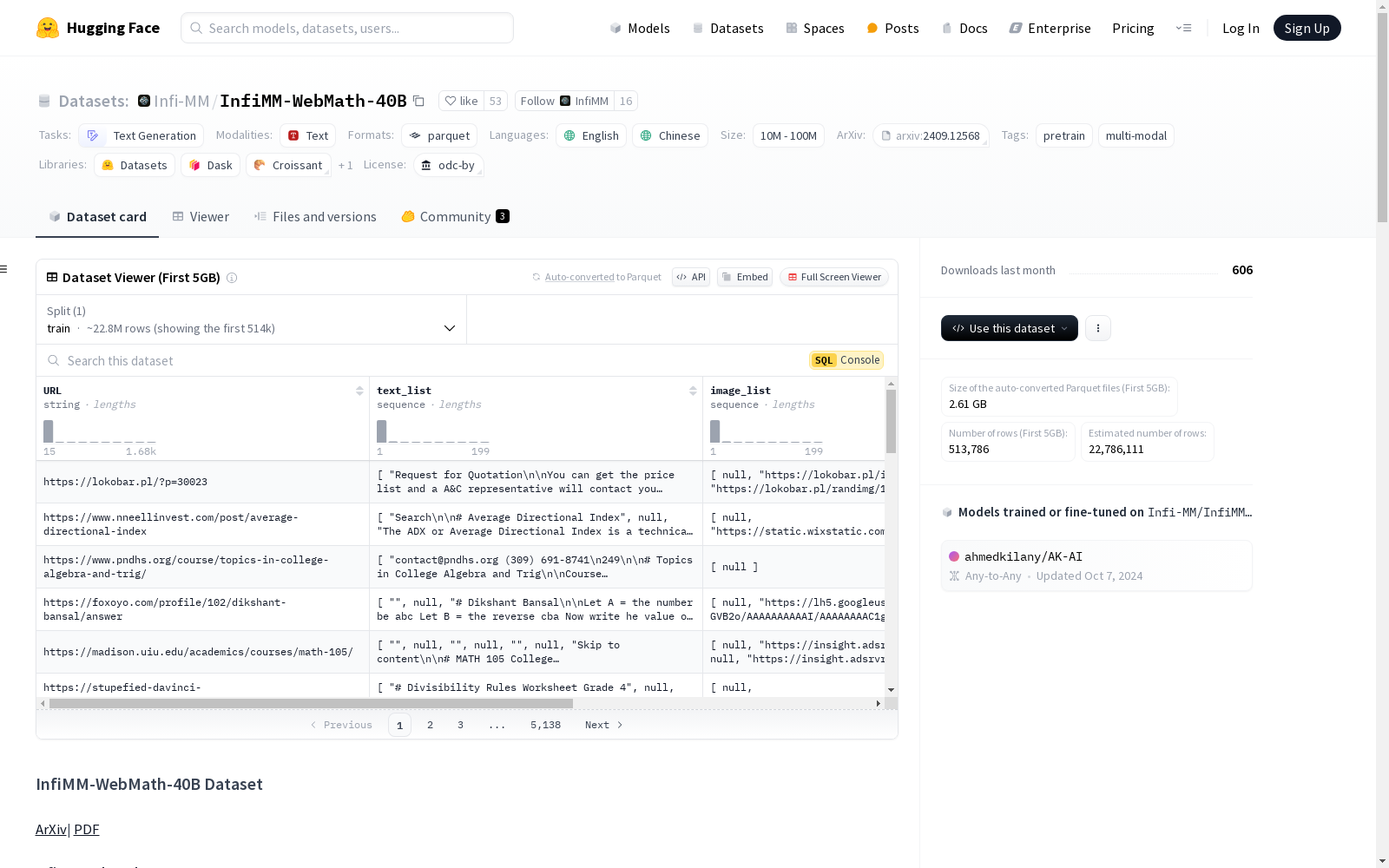
InfiMM-WebMath-40B
收藏InfiMM-WebMath-40B 数据集
概述
InfiMM-WebMath-40B 是一个大规模的开源多模态数据集,专门设计用于数学推理任务。该数据集结合了文本和图像,从网络文档中提取,以推进多模态大语言模型(MLLMs)的预训练。数据集旨在支持涉及理解和处理文本及视觉元素(如图表、图形和几何图)的复杂推理任务。
数据集组成
- 2400万 网络文档。
- 8500万 图像URL。
- 400亿 文本标记。
这些文档来自 Common Crawl 数据快照(2019-2023),经过筛选以专注于高质量的数学和科学内容,涵盖英语和中文。
数据结构
数据集以捕捉文本和图像原始顺序的格式组织,确保两种模态之间的准确交错。结构如下:
json { "URL": "...", # 源文档的URL。 "text_list": [...], # 提取的文本段列表,如果元素是图像则为None。 "image_list": [...], # 图像URL列表,如果元素是文本段则为None。 "metadata": {...} # 包含提取过程信息的元数据(如处理细节、时间戳)。 }
文本和图像的交错
text_list 和 image_list 设计为并行数组,保持文档的顺序。这种交错结构允许模型重建原始文档的流程:
- 如果
text_list[i]包含文本,则image_list[i]为None,表示该位置的内容是文本。 - 如果
text_list[i]为None,则image_list[i]包含该位置文档中的图像URL。
这种文本和图像的交错确保了基于该数据集训练的模型能够以人类的方式处理内容,遵循文本解释和伴随视觉辅助之间的逻辑流程。
数据收集和过滤流程
InfiMM-WebMath-40B 数据集通过一个全面的多阶段过滤和提取过程创建,从 Common Crawl 存储库中的超过 1200 亿网页开始。关键步骤如下:
- 语言过滤:第一步涉及过滤英语和中文内容。使用 Trafilatura 从网页中提取文本,并使用 LangDetect 高效识别语言,确保仅保留相关多语言内容。
- 高召回率数学过滤:为了尽可能多地捕捉数学相关内容,我们采用了修改版的 Resiliparse 进行HTML解析。结合高召回率优化的 FastText 模型,这一阶段确保保留任何潜在的数学数据。
- 去重:使用 MinHash 进行模糊文本去重和网页URL精确匹配,以处理相邻的 Common Crawl 快照。
- 基于规则的过滤:这一步应用特定过滤规则以移除无关或低质量内容,如包含NSFW材料或样板“lorem ipsum”的文档,提高数据集的整体质量。
- 高精度数学过滤:使用高精度调优的 FastText 模型进行第二遍过滤,确保数据集中仅保留高度相关的数学内容。这一细化步骤进一步提高了数据集对数学推理任务的专注度和相关性。
- 图像过滤:最后,基于规则的过滤应用于图像,移除无关或多余的视觉元素(如标志、横幅),确保剩余图像与数学内容一致。
如何使用数据集
- 基础文本下载:数据集可作为一组带有交错文本和图像URL的网络文档下载。
- 图像下载:用户需要根据提供的图像URL下载图像。
许可证
InfiMM-WebMath-40B 数据集在 ODC-By 1.0 许可证下提供;用户还应遵守 CommonCrawl ToU:https://commoncrawl.org/terms-of-use/。我们不更改任何底层数据的许可证。
引用
@misc{han2024infimmwebmath40badvancingmultimodalpretraining, title={InfiMM-WebMath-40B: Advancing Multimodal Pre-Training for Enhanced Mathematical Reasoning}, author={Xiaotian Han and Yiren Jian and Xuefeng Hu and Haogeng Liu and Yiqi Wang and Qihang Fan and Yuang Ai and Huaibo Huang and Ran He and Zhenheng Yang and Quanzeng You}, year={2024}, eprint={2409.12568}, archivePrefix={arXiv}, primaryClass={cs.CV}, url={https://arxiv.org/abs/2409.12568}, }