EuroWeb-2512
收藏EuroWeb-2512 数据集概述
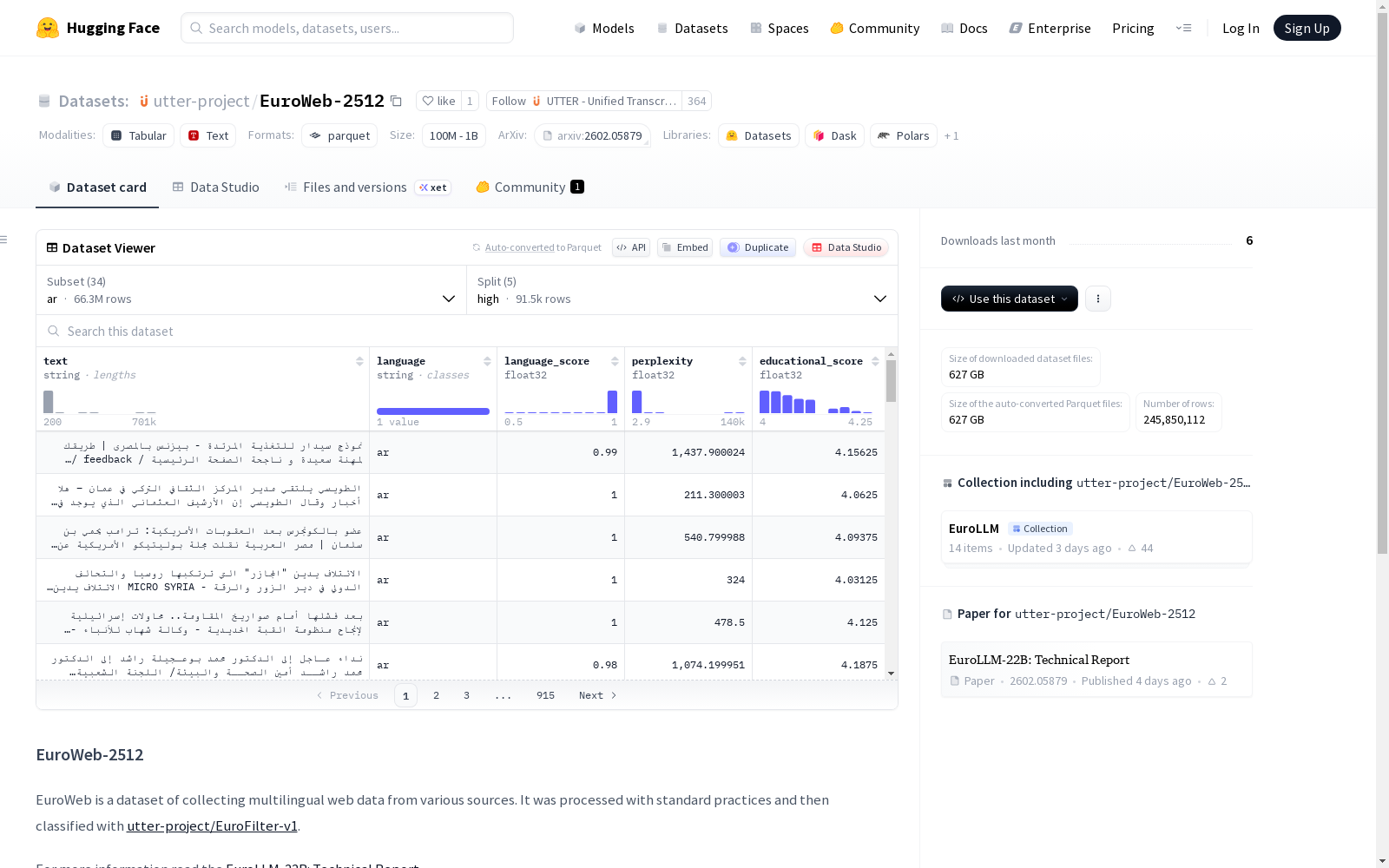
数据集基本信息
- 数据集名称: EuroWeb-2512
- 数据集地址: https://huggingface.co/datasets/utter-project/EuroWeb-2512
- 数据集描述: EuroWeb 是一个从各种来源收集的多语言网络数据集。它经过标准实践处理,并使用 utter-project/EuroFilter-v1 进行分类。
数据集配置与结构
数据集按语言(config)和质量等级(split)组织,数据文件格式为 Parquet。
支持的语言配置
数据集包含以下 38 种语言配置:
- ar, bg, ca, cs, da, de, el, es, et, fi, fr, ga, gl, hi, hr, hu, it, ja, ko, lt, lv, mt, nl, no, pl, pt, ro, ru, sk, sl, sv, tr, uk, zh
数据质量划分
每种语言配置下,数据按以下 5 个质量等级进行划分:
- high
- medium_high
- medium
- medium_low
- low
文件路径模式
每个语言和质量等级对应的数据文件路径模式为:{语言代码}/{质量等级}/*.parquet
例如:
ar/high/*.parquetzh/medium/*.parquet
技术细节与来源
- 处理流程: 数据经过标准实践处理,并使用 EuroFilter-v1 模型进行分类。
- 相关资源: 更多信息请参阅 EuroLLM-22B: Technical Report。
引用信息
如需引用本数据集,请使用以下 BibTeX 条目: bibtex @misc{ramos2026eurollm22btechnicalreport, title={EuroLLM-22B: Technical Report}, author={Miguel Moura Ramos and Duarte M. Alves and Hippolyte Gisserot-Boukhlef and João Alves and Pedro Henrique Martins and Patrick Fernandes and José Pombal and Nuno M. Guerreiro and Ricardo Rei and Nicolas Boizard and Amin Farajian and Mateusz Klimaszewski and José G. C. de Souza and Barry Haddow and François Yvon and Pierre Colombo and Alexandra Birch and André F. T. Martins}, year={2026}, eprint={2602.05879}, archivePrefix={arXiv}, primaryClass={cs.CL}, url={https://arxiv.org/abs/2602.05879}, }