angrygiraffe/claude-opus-4.6-4.7-reasoning-8.7k
收藏Hugging Face2026-05-01 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/angrygiraffe/claude-opus-4.6-4.7-reasoning-8.7k
下载链接
链接失效反馈官方服务:
资源简介:
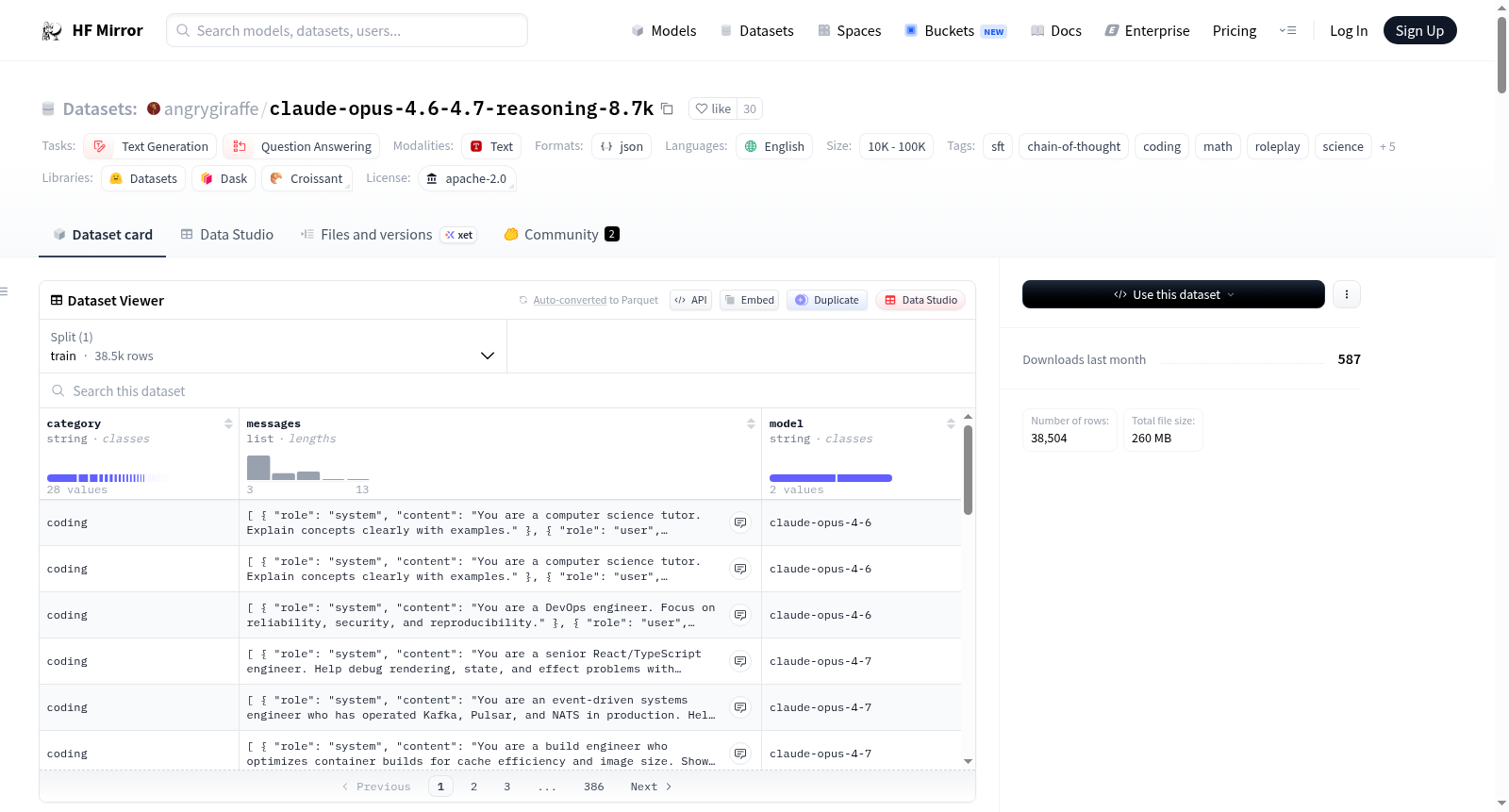
Claude Opus 4.6/4.7推理数据集是一个用于文本生成和问答任务的合成指令调优数据集,旨在教授语言模型如何思考而不仅仅是回答。数据集包含8,706个示例,覆盖28个类别,包括编码、数学、科学、人文、艺术、金融、医学、法律等多个领域。每个示例都包含一个<think>块,展示模型如何思考并生成回答。数据集分为四个子集:Full、Instruct、Roleplay和Code。数据集的特点是具有真实的思维链推理、专家级深度、自然用户声音、大量独特的系统提示和准确的角色扮演。数据集格式为OpenAI聊天格式(JSONL),语言为英语。
The Claude Opus 4.6/4.7 Reasoning Dataset is a synthetic instruction-tuning dataset designed for text-generation and question-answering tasks, aimed at teaching language models how to think, not just what to say. It contains 8,706 examples across 28 categories, including coding, math, sciences, humanities, arts, finance, medicine, law, and more. Each example includes a <think> block demonstrating the models reasoning process. The dataset is divided into four subsets: Full, Instruct, Roleplay, and Code. Key features include genuine chain-of-thought reasoning, expert-level depth, natural user voice, numerous unique system prompts, and character-accurate roleplay. The dataset is formatted in OpenAI chat format (JSONL) and is in English.
提供机构:
angrygiraffe
搜集汇总
数据集介绍
构建方式
该数据集由Claude Opus 4.6和4.7模型在令牌配额消耗过程中逐步生成,全程由模型自主开发,未经过人工审查。构建过程横跨两个模型版本,每条样本均标注了来源模型。数据集以OpenAI聊天格式的JSONL文件组织,每条记录包含类别标签、模型标识符以及完整的消息序列。所有助手回复均嵌入了<think>推理块,模拟真实思考过程,而非简单复述答案。最终形成涵盖28个类别的8,706条样本,并划分为全量、指令、角色扮演和代码四个子集,便于针对性微调。
特点
该数据集以教授语言模型如何思考而非仅输出答案为核心理念,每条样本均包含150至500词的真实推理过程,展现了多角度权衡与结构规划。覆盖编码、数学、科学、人文、艺术、金融、医学等28个专业领域,回答达到专家级深度,例如编程解答涉及设计权衡,历史讨论触及史学辩论。用户消息风格自然,避免以What或How开头的机械提问。独有5,814种系统提示,赋予模型特定领域人设,避免千篇一律的通用助手角色。角色扮演样本忠于原著角色声音与世界观,文学水准较高。
使用方法
该数据集适用于监督微调与指令调优,旨在提升模型在复杂推理与多领域专业应答方面的能力。使用者可直接加载JSONL文件,提取messages字段用于标准训练流程,并利用category和model字段筛选特定领域或来源的数据子集。建议优先使用全量8,706条样本进行综合训练,也可根据任务需求选用指令子集(7,217条)强化通用能力,或选用代码子集(1,840条)聚焦编程与数学领域。多轮对话样本占39.7%,适合训练模型处理上下文依赖与动态追问。
背景与挑战
背景概述
该数据集诞生于2024年至2025年间,由一位匿名研究者利用Claude Max计划的剩余Token,在Claude Opus 4.6与4.7模型的迭代过程中逐步构建而成。其核心研究问题在于如何通过合成指令微调数据,教会语言模型如何进行真正的、深层的思考,而不仅仅是机械地输出答案。数据集覆盖了编程、数学、科学、人文、艺术等28个类别,总计8,706条样本,每条样本均包含一个150至500词的独立思考块,展现了模型在回答前对问题的多角度权衡与结构规划。该数据集在开源社区中具有独特影响力,它不包含任何拒绝回答或安全警告,纯粹专注于提升模型的能力上限,为后续的推理能力微调研究提供了高质量的合成数据基础。
当前挑战
该数据集所解决的领域问题在于,现有的指令微调数据多侧重于模型“说什么”,而非“如何思考”,导致模型在复杂推理任务中表现机械、缺乏深度。为此,数据集采用了完全合成的链式思考,要求模型模仿期望的思考过程来生成回应,而非简单的步骤分解。在构建过程中,挑战尤为显著:首先,数据集完全由Claude模型自主生成,未经人工审查,这要求生成过程必须精准控制以避免错误传播;其次,为模拟真实用户,用户消息的设计需突破常见的“What/How”开头模式,占比不得超过20%,这对数据多样性提出了极高要求;此外,5,814个独特的系统提示需覆盖28个专业领域,每个提示需具备领域特定性,避免通用模板,这大大增加了数据生成的复杂度与成本。
常用场景
经典使用场景
该数据集专为指令微调(Supervised Fine-Tuning, SFT)而设计,核心目标是教会语言模型如何推理,而非仅仅生成答案。其经典使用场景聚焦于链式思维(Chain-of-Thought)训练,通过为每个助手回复注入150至500词的<think>推理块,模拟真实的多角度权衡与响应结构规划过程。涵盖编程、数学、科学、人文、艺术、金融、医学、法律等28个专业类目,共计8706条高质量对话样本,其中约40%为多轮交互。研究者可据此构建具备深度推理能力的专家级对话系统,尤其适用于需要严谨分析、跨学科整合与创造性表达的复杂任务场景。
解决学术问题
该数据集直指当前大语言模型在复杂推理与专家级回应深度上的不足。传统微调数据集多聚焦于答案正确性,而忽视了推理过程的真实性与可迁移性。此数据集通过合成但结构化的链式思维内容,解决了模型在回答前缺乏多角度思考与策略规划的问题。其28个专业类目的精细划分,为跨学科推理能力评估提供了标准化基准,推动了从表面问答到深度认知的范式转变。研究显示,基于此类数据微调的模型在需要领域专业知识、创造性写作或复杂角色扮演的任务上,表现显著优于仅使用标准指令数据的对应模型。
衍生相关工作
该数据集催生了多类衍生研究方向。其一,基于领域分类(如代码、数学、角色扮演)的子集抽取工作,催生了专门化的微调基准,例如仅含编程与数学的code_train子集被用于强化代码生成模型的推理能力。其二,独特的5,814个系统提示词设计启发了提示词工程研究,探索如何通过多样化的角色与场景设定提升模型泛化性。其三,纯合成链式思维数据的有效性验证,推动了低成本推理数据自动生成方法的发展,形成了与人工标注数据集质量对比的系列研究。最后,多轮交互结构的分析为长程对话连贯性评估提供了新指标。
以上内容由遇见数据集搜集并总结生成


