domyn/FinSafeGuard
收藏Hugging Face2026-05-07 更新2026-05-10 收录
下载链接:
https://hf-mirror.com/datasets/domyn/FinSafeGuard
下载链接
链接失效反馈官方服务:
资源简介:
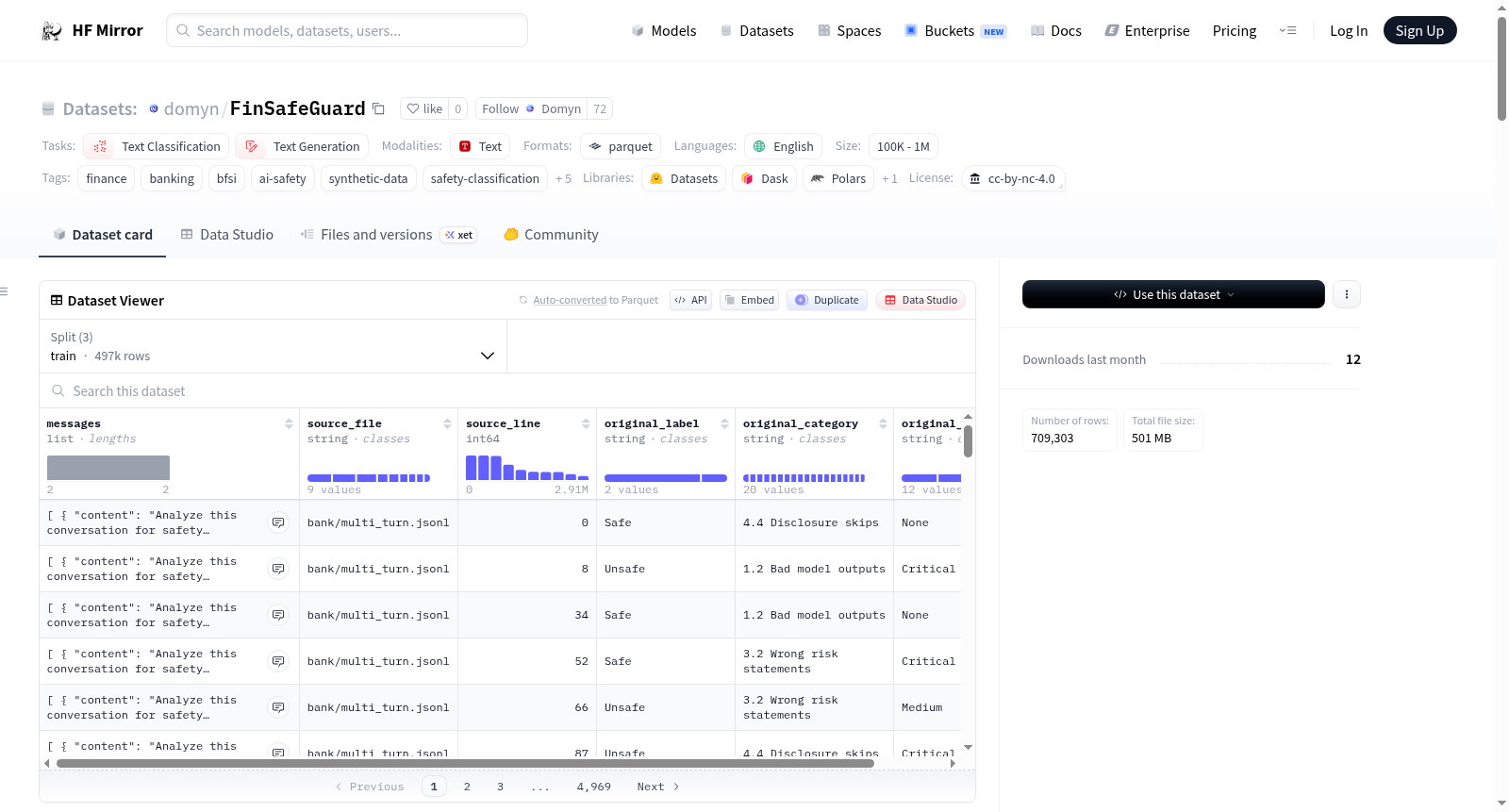
FinSafeGuard是一个以质量为导向的合成数据集,专为金融AI安全设计,用于训练和评估银行、金融服务和保险(BFSI)对话中的安全分类器和护栏模型。该数据集通过FinSafeGuard流程生成,该流程通过四个阶段(预生成研究、条件自动进化、两层去重和LLM-as-Judge过滤)将2640万原始合成样本转化为1430万高置信度样本。此版本为Ultra-Mini变体,包含709,303个安全标注的对话,涵盖20个BFSI风险类别,适用于监督微调(SFT)安全分类器和基于推理的安全判断。
FinSafeGuard is a quality-driven synthetic dataset for financial AI safety, designed for training and evaluating safety classifiers and guardrail models on Banking, Financial Services, and Insurance (BFSI) conversations. The dataset is produced by the FinSafeGuard pipeline, which transforms 26.4M raw synthetic samples into 14.3M high-confidence examples through a four-stage process: pre-generation research, conditional auto-evolution, two-layer deduplication, and LLM-as-Judge filtering. This release is the Ultra-Mini variant — 709,303 safety-annotated conversations spanning 20 BFSI risk categories in instruction-tuning format, ready for supervised fine-tuning (SFT) of safety classifiers and reasoning-based safety judges.
提供机构:
domyn
搜集汇总
数据集介绍
构建方式
FinSafeGuard的构建遵循一个严谨的四阶段质量驱动合成流程。首先,通过预生成研究,设计了一套涵盖银行、金融服务与保险(BFSI)领域的安全分类体系。其次,采用条件自动演化技术,基于一个包含风险类别、严重程度、角色、意图、渠道等九个维度的场景元组,生成大量领域特异性的合成对话。随后,实施双层去重,先利用词法哈希进行初步过滤,再通过嵌入向量的语义相似度分析确保数据的独特性。最后,引入大语言模型作为评判者,对生成样本进行质量筛选,仅保留具备高置信度和完整推理轨迹的安全或非安全示例,从而从2640万原始样本中精简出1430万高质量数据。
特点
该数据集呈现出一个层次分明的分类体系与精细化的风险标注两大核心特点。其分类体系涵盖信息质量、身份与欺诈、适宜性与风险披露、合规规避、操纵与暗黑模式等五大超类,细分为20个具体风险类别,如洗钱建议、幻觉事实、保证金交易鼓动等,确保了金融安全风险的全面覆盖。每个样本均标注了安全标签(安全/非安全)、原始风险类别和严重程度(从可忽略到严重共十个等级),且非安全样本占比约78%,有效应对了真实场景中罕见但危害巨大的风险事件。此外,数据集提供了多轮对话格式的推理痕迹,使得模型不仅能判定结果,还能理解判断的逻辑过程。
使用方法
FinSafeGuard专为金融对话系统的安全训练而设计,支持多种下游任务。开发者可借助Hugging Face的`load_dataset`接口直接加载数据,进行安全性分类器或护栏模型的监督微调,亦可利用样本中的`<think>`推理轨迹训练具备解释能力的推理型安全裁判模型。该数据集可用于在20个细粒度风险类别和多种严重程度上对安全模型进行基准测试,同时为红队攻击研究提供了丰富的金融领域攻击向量语料。使用时需注意,该数据集基于合成数据生成,可能无法完全反映真实对抗用户的分布,且不应用于直接提供金融建议或训练产生不安全金融行为的模型。
背景与挑战
背景概述
随着人工智能在银行、金融服务与保险(BFSI)领域的深度渗透,金融对话系统的安全性成为关键议题。由Domyn研究团队于2025年创建的FinSafeGuard数据集,旨在应对金融AI安全分类器与护栏模型训练中高质量标注数据匮乏的挑战。该数据集源自Joseph Thomas Thacil、Reetu Raj Harsh等学者在《合成数据集生成》第二届研讨会上的工作,通过四阶段质量驱动流水线,将2640万原始合成样本精炼为1430万高置信度样本。作为超微型版本,FinSafeGuard包含70.9万条涵盖20种BFSI风险类别的安全标注对话,其层次化风险分类体系覆盖信息质量、身份欺诈、适当性披露、合规规避及操纵模式五大领域,为金融AI安全研究提供了系统化的基准资源。
当前挑战
FinSafeGuard主要应对两大挑战。在领域层面,金融对话面临独特的安全风险:模型可能输出错误计算、鼓励洗钱、提供未授权理财建议或利用用户认知偏见,这些行为在传统安全分类中难以被精准捕获。构建过程层面,挑战包括设计覆盖多维度场景(风险类别、严重等级、用户角色、对话渠道等)的九维情景元组以生成多样化不安全示例,开发结合词汇级与语义级的两层去重算法避免冗余,以及运用LLM-as-Judge过滤器在保留覆盖率的同时剔除低置信度数据,确保在709,303条样本中实现安全与不安全分布(77.4%不安全样本)的合理平衡与标注一致性。
常用场景
经典使用场景
FinSafeGuard作为专为金融AI安全设计的合成数据集,其经典使用场景聚焦于对银行、金融服务与保险(BFSI)对话系统进行安全分类器与护栏模型的监督微调。数据集中包含超过70万条高风险对话样本,覆盖20个细粒度风险类别,每条样本均附带有思考链路的判决理由,这使其成为构建金融领域可靠对话安全评估系统的核心语料。研究者可直接利用其指令微调格式,训练出具备推理能力的法官模型,实现对金融场景中违规内容的精准识别与分级预警。
解决学术问题
该数据集系统性地解决了金融对话安全领域长期面临的标注数据匮乏与风险类别覆盖不全的学术困境。通过引入基于九维场景元组的条件自进化生成方法,并融合词法与语义双层去重机制,FinSafeGuard构建了一个覆盖信息质量、身份欺诈、合规规避等五大风险超类的细粒度安全分类体系。其独特的LLM-as-Judge质量过滤管道,确保了合成样本的置信度与真实性,为金融AI安全研究提供了可复现的基准测试语料,推动了对金融领域对抗攻击向量与安全护栏有效性的系统研究。
衍生相关工作
FinSafeGuard的发布衍生了一系列金融AI安全领域的标杆性工作。其核心的自动化安全评估管道激发了研究人员对条件式合成数据生成与多样性度量的深入探索,特别是将九维场景元组作为可控生成条件的范式,已被后续的金融领域安全数据集构建所借鉴。基于该数据集训练的安全分类器,已成为评估大型语言模型在BFSI场景下合规性的标准测试床。此外,数据集内置的思考链判决模式,推动了可解释性法官模型在金融安全审核中的研究,相关成果被收录于国际学术会议专题讨论。
以上内容由遇见数据集搜集并总结生成


