CID_SID_IUPAC_PAIN
收藏Hugging Face2025-10-27 更新2025-10-28 收录
下载链接:
https://huggingface.co/datasets/ivanovaml/CID_SID_IUPAC_PAIN
下载链接
链接失效反馈官方服务:
资源简介:
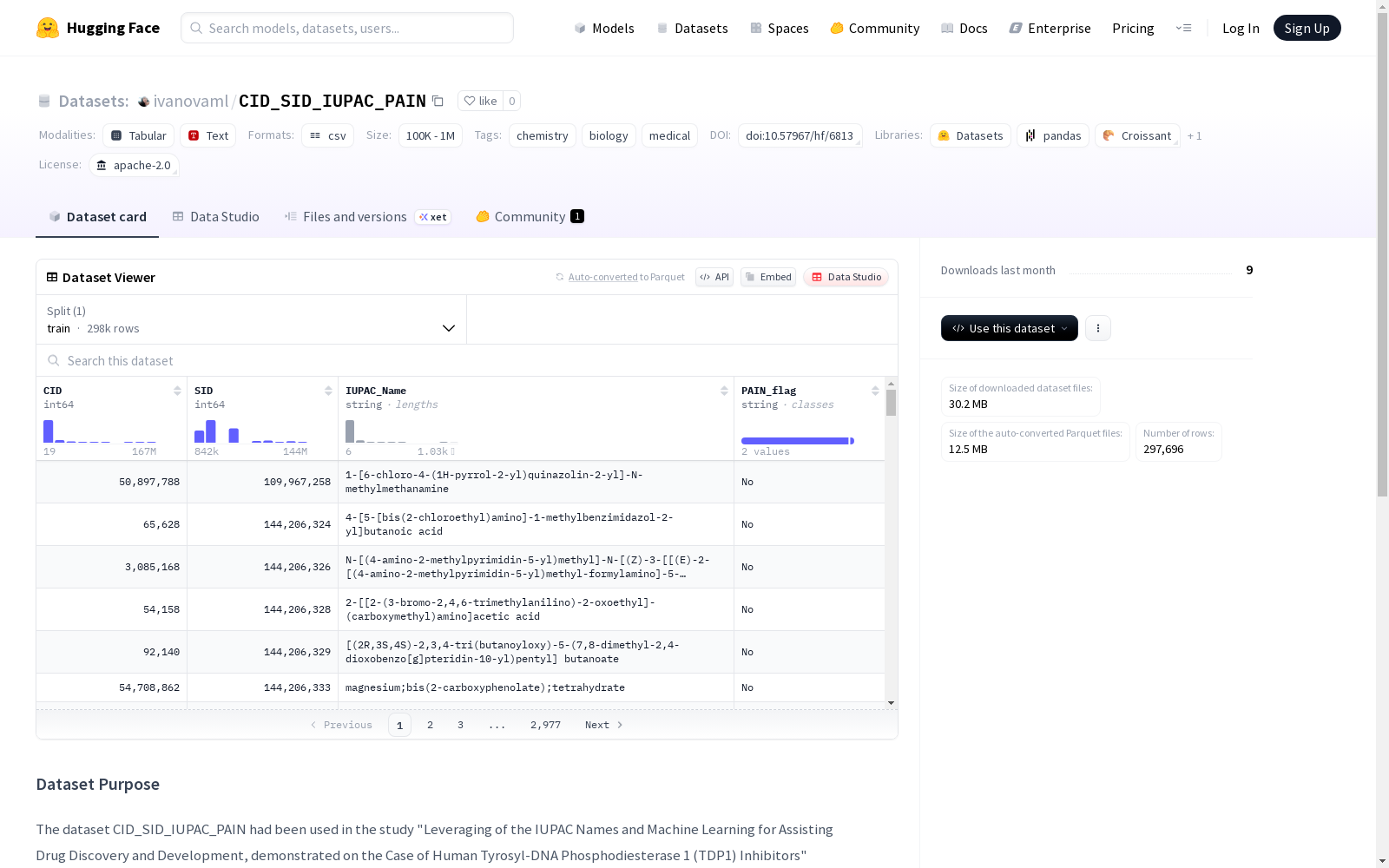
CID_SID_IUPAC_PAIN数据集包含297,696条记录,每条记录包括CID(PubChem标识符)、SID(PubChem标识符)、IUPAC名称和PAIN标志。该数据集用于研究通过利用IUPAC名称和机器学习技术来辅助药物发现和开发,特别是在人Tyrosyl-DNA磷酸二酯酶1(TDP1)抑制剂的研究案例中。
创建时间:
2025-10-27
原始信息汇总
数据集概述
基本信息
- 许可证: Apache-2.0
- 领域标签: 化学、生物学、医学
- 数据规模: 10万到100万条之间
数据集用途
本数据集用于研究《利用IUPAC名称和机器学习辅助药物发现与开发——以人酪氨酰-DNA磷酸二酯酶1(TDP1)抑制剂为例》,相关论文链接:https://doi.org/10.48550/arXiv.2503.05591
数据来源
数据样本来源于PubChem AID 686978生物测定实验,该实验专注于"人酪氨酰-DNA磷酸二酯酶1(TDP1)抑制剂的定量高通量筛选:无CPT条件下的细胞qHTS",实验链接:https://pubchem.ncbi.nlm.nih.gov/bioassay/686978
技术工具
- 使用RDKit化学信息学工具包
- 使用FilterCatalog进行化合物筛选
- 源代码地址:https://github.com/articlesmli/IUPAC_ML_model_TDP1/blob/main/IUPAC_ML_model/PAIN_IUPAC_checker.ipynb
数据集详情
- 总行数: 297,696
- 列结构:
- CID(PubChem化合物标识符)
- SID(PubChem物质标识符)
- IUPAC名称
- PAIN标记
搜集汇总
数据集介绍
构建方式
在药物发现领域,CID_SID_IUPAC_PAIN数据集源自PubChem生物测定AID 686978的实验样本,该测定专注于高通量筛选人类酪氨酰-DNA磷酸二酯酶1(TDP1)抑制剂。通过整合PubChem标识符(CID和SID)与IUPAC命名法,并利用RDKit化学信息学工具进行PAIN(泛化干扰化合物)标记处理,确保了数据在化学结构表征上的准确性和一致性,从而构建出一个涵盖297,696条记录的综合性资源。
使用方法
使用CID_SID_IUPAC_PAIN数据集时,研究人员可通过RDKit库中的FilterCatalog模块进行PAIN标记验证,以过滤出具有潜在干扰特性的化合物。数据集支持直接导入至机器学习流程,用于构建预测模型,例如在TDP1抑制剂开发中评估化合物活性。相关源代码已在GitHub开源,便于用户复现分析步骤,并可根据CID和SID标识符链接至PubChem数据库获取补充实验数据,实现端到端的药物发现应用。
背景与挑战
背景概述
在药物发现与开发领域,高通量筛选技术已成为识别潜在生物活性分子的核心手段。CID_SID_IUPAC_PAIN数据集由研究团队于2024年构建,依托PubChem生物测定数据库中的AID 686978实验数据,专注于人类酪氨酰-DNA磷酸二酯酶1(TDP1)抑制剂的定量高通量筛选。该数据集整合了化合物标识符(CID与SID)、国际纯粹与应用化学联合会命名(IUPAC)及PAINS(泛筛选干扰化合物)标记,旨在通过机器学习和化学信息学方法优化先导化合物识别流程,显著提升了靶向药物开发的效率与准确性。
当前挑战
该数据集致力于应对药物发现中泛筛选干扰化合物的识别难题,此类分子易在生物测定中产生假阳性结果,严重制约候选药物的可靠性。构建过程中,研究人员需从海量PubChem数据中精确提取TDP1相关生物活性记录,并利用RDKit工具进行PAINS模式匹配,确保IUPAC名称与结构标识的一致性。数据整合涉及多源标识符的映射与标准化,以及化学命名规则的复杂解析,这些步骤均对计算资源与算法鲁棒性提出了较高要求。
常用场景
经典使用场景
在药物发现领域,该数据集通过整合化学结构与生物活性数据,为机器学习模型提供关键训练资源。其经典应用场景包括高通量筛选分析,特别是针对人类酪氨酰-DNA磷酸二酯酶1(TDP1)抑制剂的活性预测,有效加速了候选化合物的虚拟筛选流程。
解决学术问题
该数据集解决了药物化学中化合物活性预测的泛化难题,通过系统化标注PAINs(泛筛选干扰化合物)特征,显著降低了实验假阳性率。其意义在于构建了标准化评估框架,为靶向TDP1的抑制剂开发提供了可复现的计算基准,推动了计算化学与实验验证的深度融合。
实际应用
实际应用中,该数据集被制药企业用于先导化合物优化阶段,通过自动化识别结构警示基团,有效规避了药物研发中的脱靶风险。在学术实验室中,它支撑了化学信息学工具的开发,例如集成至RDKit工作流,实现了大规模化合物库的快速毒性预筛。
数据集最近研究
最新研究方向
在药物发现与开发领域,该数据集正推动化学信息学与人工智能的深度融合。前沿研究聚焦于利用IUPAC命名规则结合机器学习模型,精准预测人类酪氨酰-DNA磷酸二酯酶1(TDP1)抑制剂的活性与选择性。这一方向呼应了当前对抗癌靶点药物筛选的热点需求,通过解析化合物结构特征与生物活性关联,显著提升了高通量筛选的效率和可靠性。其应用不仅加速了先导化合物的优化进程,还为规避泛筛选干扰物(PAINS)等常见陷阱提供了数据支撑,对推动精准医疗与创新药物研发具有重要科学价值。
以上内容由遇见数据集搜集并总结生成


