msu-ceco/agxqa_v1
收藏Hugging Face2024-08-17 更新2024-06-29 收录
下载链接:
https://hf-mirror.com/datasets/msu-ceco/agxqa_v1
下载链接
链接失效反馈官方服务:
资源简介:
AgXQA 1.1数据集是一个小规模的问答数据集,专注于农业扩展领域,特别是灌溉相关的问题。该数据集包含超过2100个问题,主要涉及美国中西部的灌溉主题,特别是大豆和玉米作物。数据集的结构包括训练集、验证集和测试集,分别包含1503、353和330个样本。数据集的创建旨在提高NLP模型在理解和提取农业水文实践相关信息方面的性能。数据集的注释过程遵循了Rajpurkar等人的指南,并由农业领域的专家进行质量控制和验证。
The Agricultural eXtension Question Answering Dataset (AgXQA 1.1) is a small-scale, SQuAD-like QA dataset targeting the Agriculture Extension domain, particularly focusing on irrigation-related questions. The dataset contains over 2,100 questions primarily related to irrigation topics in the Midwest US, with a focus on soybean and corn crops. The dataset structure includes training, validation, and test sets with 1,503, 353, and 330 samples respectively. The creation of this dataset aims to enhance the performance of NLP models in understanding and extracting relevant information about agro-hydrological practices. The annotation process followed guidelines from Rajpurkar et al. and was quality-controlled and validated by experts in the agricultural field.
提供机构:
msu-ceco
原始信息汇总
数据集概述
数据集基本信息
- 名称: AgXQA 1.1
- 语言: 英语 (
en) - 许可证: MIT
- 任务类别: 问答 (Question Answering)
- 任务ID:
- 封闭领域问答 (Closed-Domain QA)
- 抽取式问答 (Extractive QA)
- 规模: 1K < n < 10K
- 标签:
- 农业 (Agriculture)
- 农业扩展 (Extension)
- 灌溉 (Irrigation)
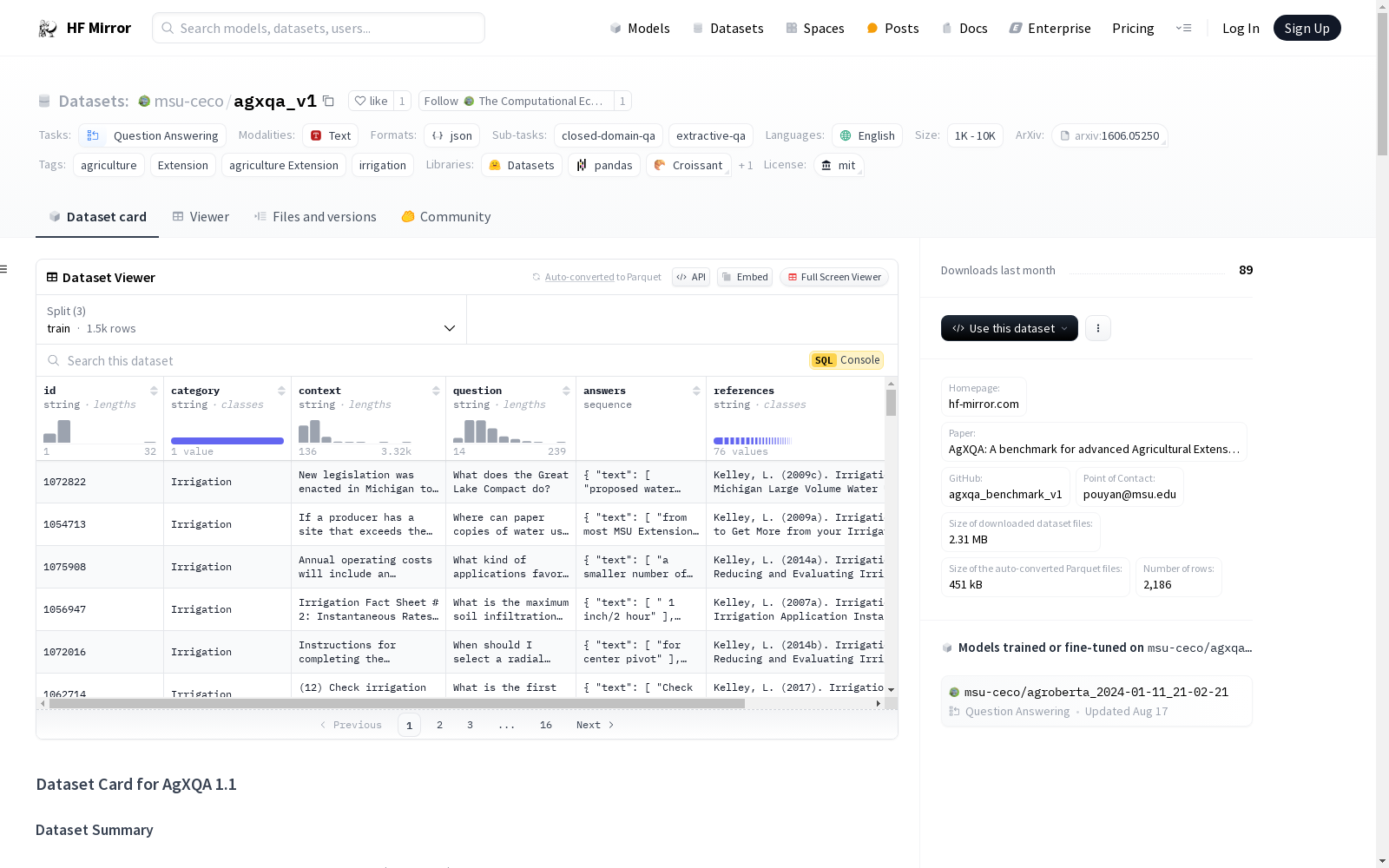
数据集结构
数据实例
- id: 字符串类型
- category: 字符串类型
- context: 字符串类型
- question: 字符串类型
- answers: 字典类型,包含以下字段:
text: 字符串类型answer_start: 整数类型 (int32)
- references: 字符串类型
数据分割
- 训练集: 1503 条数据
- 验证集: 353 条数据
- 测试集: 330 条数据
数据集创建
数据来源
- 原始数据: 从农业扩展语料库 (AEC1.1) 中提取的约600个段落
- 数据生产者:
- CECO 负责监督QA对的创建和标注
- 原始段落/上下文的生产者信息请参见 AEC1.1 数据集卡片
标注过程
- 标注工具: Deepset的标注工具
- 标注指南: 遵循 Rajpurkar et al. (2016) 的指南,创建类似SQuAD的数据集
- 标注者: 三名标注者,其中两名具有农业背景,由两名水资源和灌溉研究专家监督
个人和敏感信息
- 原始段落中包含的扩展教育者的姓名和电子邮件地址已被替换为
x - 每个段落都引用了其来源文章
数据使用注意事项
社会影响
- 数据集主要关注灌溉相关主题,建议不要在生产环境中使用,因为农业问题通常需要时间性和地理空间信息,而这些信息在当前版本中未涵盖
偏见讨论
- 数据集规模较小,仅包含灌溉相关主题,建议谨慎使用
- 发现三个包含URL的段落,这些是异常值,将在版本2中移除
其他信息
许可证信息
- 数据集在 [TO-DO] 许可证下发布
引用信息
- [TO-DO]
搜集汇总
数据集介绍
构建方式
AgXQA 1.1数据集的构建基于农业扩展领域的特定需求,旨在提升自然语言处理模型在理解和提取农业灌溉相关信息的能力。数据集从农业扩展语料库(AEC1.1)中提取约600段文本作为上下文,并遵循Rajpurkar等人的方法,利用Deepset的标注工具生成问答对。标注过程包括问题生成、答案收集和质量控制,由农业和环境领域的专家进行审核和验证,确保数据的准确性和相关性。
特点
AgXQA 1.1数据集的主要特点在于其专注于农业灌溉领域,涵盖了灌溉方法、调度、土壤水分监测等多个方面。数据集包含2.1K+个问答对,适用于封闭域和抽取式问答任务。此外,数据集的构建过程中特别考虑了数据多样性和覆盖范围,确保了问答对的地理和主题多样性。
使用方法
AgXQA 1.1数据集适用于训练和评估问答系统,特别是针对农业领域的自然语言处理模型。用户可以通过HuggingFace的datasets库加载数据集,并根据提供的训练、验证和测试集进行模型训练和评估。数据集的结构包括id、类别、上下文、问题、答案和参考文献等字段,便于用户进行数据处理和模型开发。
背景与挑战
背景概述
农业扩展问答数据集(AgXQA 1.1)是由MSU-CECO团队创建的一个小型SQuAD风格的问答数据集,专注于农业扩展领域。该数据集的创建旨在提升自然语言处理模型(如大型语言模型)在理解和提取与农业水文实践相关的信息方面的性能。AgXQA 1.1版本包含超过2.1千个与美国中西部灌溉主题相关的问题,主要关注大豆和玉米作物。该数据集的创建不仅填补了农业领域问答数据的空白,还为农业扩展领域的研究提供了宝贵的资源。
当前挑战
AgXQA 1.1数据集在构建过程中面临多项挑战。首先,数据集规模较小,仅包含灌溉相关主题,限制了其在实际应用中的广泛使用。其次,农业领域的问答需求通常涉及时间性和地理空间信息,而当前版本的数据集未能充分覆盖这些方面。此外,数据集中存在一些包含URL的段落,这些异常值可能影响模型的训练效果。未来版本需要解决这些问题,以提升数据集的实用性和覆盖范围。
常用场景
经典使用场景
在农业领域,AgXQA 1.1数据集的经典使用场景主要集中在农业扩展领域的问答系统开发。该数据集通过提供与灌溉相关的详细问题和答案对,帮助研究人员和开发者训练和评估自然语言处理模型,特别是针对农业特定知识的问答系统。这些模型能够有效地理解和提取关于农业灌溉实践的相关信息,从而为农业从业者提供准确和实用的指导。
解决学术问题
AgXQA 1.1数据集解决了农业扩展领域中自然语言处理模型性能不足的问题。通过提供高质量的、特定于农业灌溉知识的问题和答案对,该数据集促进了针对农业领域的问答系统的开发和优化。这不仅提升了模型的准确性和实用性,还为农业科学研究提供了新的工具和方法,推动了农业技术的进步和应用。
衍生相关工作
基于AgXQA 1.1数据集,研究者们开发了多种农业领域的自然语言处理模型,如AgRoBERTa。这些模型在农业问答任务中表现出色,显著提升了农业扩展服务的质量和效率。此外,该数据集还激发了更多关于农业数据集的创建和研究,推动了农业信息技术的整体发展,为农业领域的智能化和自动化提供了坚实的基础。
以上内容由遇见数据集搜集并总结生成


