arsalan-anwari/zer-data
收藏Hugging Face2026-05-01 更新2026-04-26 收录
下载链接:
https://hf-mirror.com/datasets/arsalan-anwari/zer-data
下载链接
链接失效反馈官方服务:
资源简介:
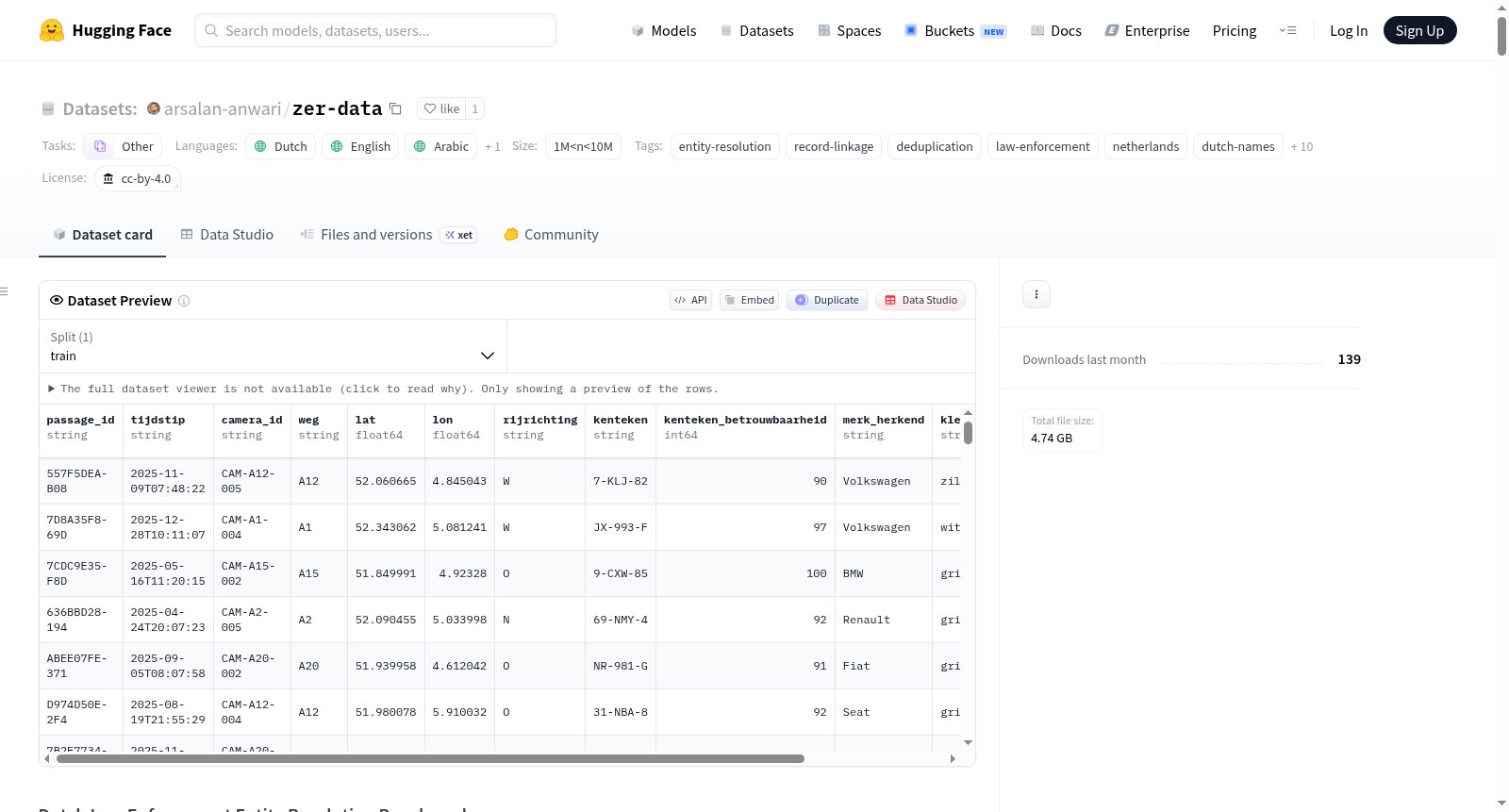
荷兰执法实体解析基准数据集是一个用于实体解析和记录链接研究的合成基准数据集集合,基于真实的荷兰和欧盟/欧洲经济区执法数据模式建模。该数据集旨在解决荷兰执法数据中的特定挑战,如荷兰名字复杂性、多文化名字变体、跨申根身份问题、ANPR OCR错误、估计出生日期、电信身份变动和金融网络结构。数据集包含多种类型的记录,每种记录都有详细的模式、真实配对格式和注入的错误模式,以复制现实世界的挑战。数据集提供多种规模,适用于不同的使用场景,所有数据均为100%合成,以避免隐私或法律问题。
The Dutch Law Enforcement Entity Resolution Benchmark is a collection of synthetic benchmark datasets for entity resolution and record linkage research, modelled on real Dutch and EU/EEA law enforcement data schemas. The dataset is designed to address specific challenges in Dutch law enforcement data, such as Dutch name complexity, multicultural name variation, cross-Schengen identity issues, ANPR OCR errors, estimated dates of birth, telecom identity churn, and financial network structure. The dataset includes multiple types of records, each with detailed schemas, ground truth formats, and injected error patterns to replicate real-world challenges. The dataset is available in various sizes, each suitable for different use cases, and all data is 100% synthetic to avoid privacy or legal concerns.
提供机构:
arsalan-anwari
搜集汇总
数据集介绍
构建方式
该数据集基于荷兰及欧盟/欧洲经济区真实执法数据模式构建,但所有数据均为100%合成生成,不涉及任何真实个人、车辆、电话号码或犯罪记录。每个姓名、日期、车牌号、IBAN、IMSI等标识符均通过程序化方式生成,确保数据可自由使用、分享和发布而无隐私或法律顾虑。生成过程融合了来自荷兰商会(KvK)、人口登记(BRP)、申根信息系统(SIS II)、荷兰自动车牌识别(ANPR)摄像头、刑事前科系统(HKS)、国际刑警组织(Interpol)通知、电信通话记录(CDR)及金融情报单位(FIU)等多个来源的真实模式,并结合荷兰中央统计局(CBS)的人口统计分布数据,注入诸如姓名变体、OCR混淆、罗马化差异、估计出生日期及SIM卡更换事件等特定错误模式,以复现荷兰及跨境申根身份数据中的独特挑战。
特点
该数据集涵盖了执法领域中常见的多元身份识别挑战,包括荷兰姓名中tussenvoegsel前缀的省略与格式不一致、多元文化背景下的姓名拼写变体、跨申根国家的姓名顺序与罗马化差异、ANPR摄像头导致的车牌字符混淆、移民记录中估计出生日期的使用、电信身份变更带来的SIM卡更换与IMEI重用难题,以及金融交易中的网络结构特征。数据集提供从5万到100万条记录不等的多个规模层级,均使用确定性种子确保实验结果可复现。每个子数据集均附带详细的模式定义、真实匹配对及匹配类型标注,便于研究者针对特定错误模式进行深入分析。
使用方法
该数据集以CSV和JSON格式提供,每个子数据集包含对应的真实匹配对文件,用户可直接加载进行实体解析与记录链接研究。使用时可利用提供的字段信息构建匹配模型,如通过姓名、出生日期、地址等字段进行相似度计算,或针对特定错误模式设计模糊匹配算法。对于CDR等图结构数据,可用于社区检测与身份聚类分析。所有数据均采用标准化格式,易于集成至机器学习流水线中,并支持不同规模的数据集选择以适配开发、测试或性能基准测试需求。
背景与挑战
背景概述
实体解析(Entity Resolution)与记录链接(Record Linkage)是数据整合与知识发现领域的核心议题,在执法、金融反欺诈、公共卫生等场景中具有关键作用。然而,现有基准数据集(如DBLP-ACM、Febrl、Cora)多聚焦于学术文献或通用人口信息,未能模拟执法数据中特有的复杂身份解析挑战。为弥补这一空白,由荷兰研究机构于2023年创建的zer-data(Dutch Law Enforcement Entity Resolution Benchmark)数据集应运而生。该数据集基于荷兰及欧盟/欧洲经济区真实执法数据模式(包括KvK商事登记、BRP人口登记、SIS II申根信息系统、ANPR车牌识别、HKS犯罪前科、Interpol国际刑警通知、CDR通话记录、SIM注册及FIU金融情报报告)合成生成,旨在为执法背景下的实体解析研究提供标准化、可复现的基准。其影响力体现在:首次系统性地将荷兰及跨申根身份数据特有的命名规则、文牍错误、跨脚本对齐等难题纳入基准测试,推动了该领域从通用解析向领域特定解析的跨越。
当前挑战
zer-data数据集所解决的领域问题核心在于:执法实体解析需应对多重数据源间因命名习惯、记录错误、语言差异、设备生命周期变化等引发的身份碎片化挑战。具体挑战包括:1)荷兰名字中“tussenvoegsel”前缀(如van、de、van der)的省略或变体,与文化族群(如摩洛哥裔、土耳其裔)姓名拼写差异叠加,导致同一实体在多点录入时出现系统性变异;2)跨申根国家间姓名语序倒置(Benabdallah Fatima ↔ Fatima Benabdallah)及罗马化变体(Mohammed/Mohamed/Muhammad),使跨库链接高度依赖模糊匹配;3)ANPR车牌OCR错误呈现确定性字符混淆(0↔O、1↔I、8↔B等),需设计针对性纠错算法;4)移民记录中出生日期使用“YYYY-01-01”占位符,与精确日期形成年边界匹配难题;5)通信数据中SIM换卡、IMEI复用导致的身份继承与共享关系,要求图感知的解析策略。在数据集构建上,需精准注入上述错误模式并确保合成数据的人口统计分布与荷兰统计署(CBS)数据一致,同时通过确定性种子保证实验可复现性,对生成过程的工程严谨性提出了极高要求。
常用场景
经典使用场景
在执法与公共安全领域,zer-data数据集被广泛用于实体解析(Entity Resolution)与记录链接(Record Linkage)任务的基准测试。其经典使用场景涵盖荷兰及欧盟申根区警务数据的多源身份融合,包括从商会董事名册、人口登记、SIS II通缉系统、HKS犯罪前科档案、国际刑警组织通报、ANPR车牌识别、电信CDR记录到SIM用户注册的全链路身份匹配。研究者可借此模拟跨系统、跨语言、跨书写体系的实体对齐挑战,例如荷兰姓名中缀变体、多元文化姓名罗马化差异、车牌OCR字符混淆、出生日期估计值模糊、SIM卡更换导致的身份漂移等现实难题,从而验证和提升算法在复杂执法数据环境下的鲁棒性。
实际应用
在实际执法与公共安全工作中,zer-data数据集为多源情报融合系统提供了关键的验证基石。公安与司法机关可借助该数据集训练和评估自动身份解析流水线,例如将ANPR摄像头读取的可疑车牌与车辆注册数据库进行模糊匹配,或在SIS II与国际刑警组织通报之间发现跨系统通缉犯的别名关联。电信运营商和金融情报单元(FIU)可利用其模拟的SIM交换和异常交易报告场景,构建电话身份图谱与资金流向网络,用于识别洗钱、诈骗团伙中的马甲账户与共享设备。荷兰商会(KvK)与人口登记(BRP)子集则支持商业信息与人口数据的质量清洗,帮助政府机构在执法调查、边境管控与反恐协作中实现高效、精准的跨数据库身份确认。
衍生相关工作
zer-data数据集自发布以来,已催生了一系列面向执法场景的实体解析与图分析创新工作。研究者基于其模拟的CDR通信网络与SIM交换记录,开发了融合时序信息的图神经网络模型,能够有效追踪SIM卡更换后的身份连续性,并在社区检测任务中识别通信枢纽节点。针对ANPR子集中系统的OCR混淆模式,衍生出基于字符级编辑距离与注意力机制的端到端车牌纠错方法。在跨语言层面,其SIS II与国际刑警通报的双罗马化变体数据推动了多语种姓名匹配领域的研究,催生了融合音素编码与翻译嵌入的跨书写体系对齐模型。此外,部分工作将FIU异常交易子集与金融犯罪检测结合,探索了图对比学习在洗钱团伙挖掘中的潜力,进一步拓展了该数据集在安全敏感领域的研究边界。
以上内容由遇见数据集搜集并总结生成


