rahulvyasm/medical_insurance_data
收藏Hugging Face2024-03-26 更新2024-06-11 收录
下载链接:
https://hf-mirror.com/datasets/rahulvyasm/medical_insurance_data
下载链接
链接失效反馈官方服务:
资源简介:
---
license: mit
---
# Dataset Card for Medical Insurance Cost Prediction
The medical insurance dataset encompasses various factors influencing medical expenses, such as age, sex, BMI, smoking status, number of children, and region. This dataset serves as a foundation for training machine learning models capable of forecasting medical expenses for new policyholders.
Its purpose is to shed light on the pivotal elements contributing to increased insurance costs, aiding the company in making more informed decisions concerning pricing and risk assessment.
## Dataset Description
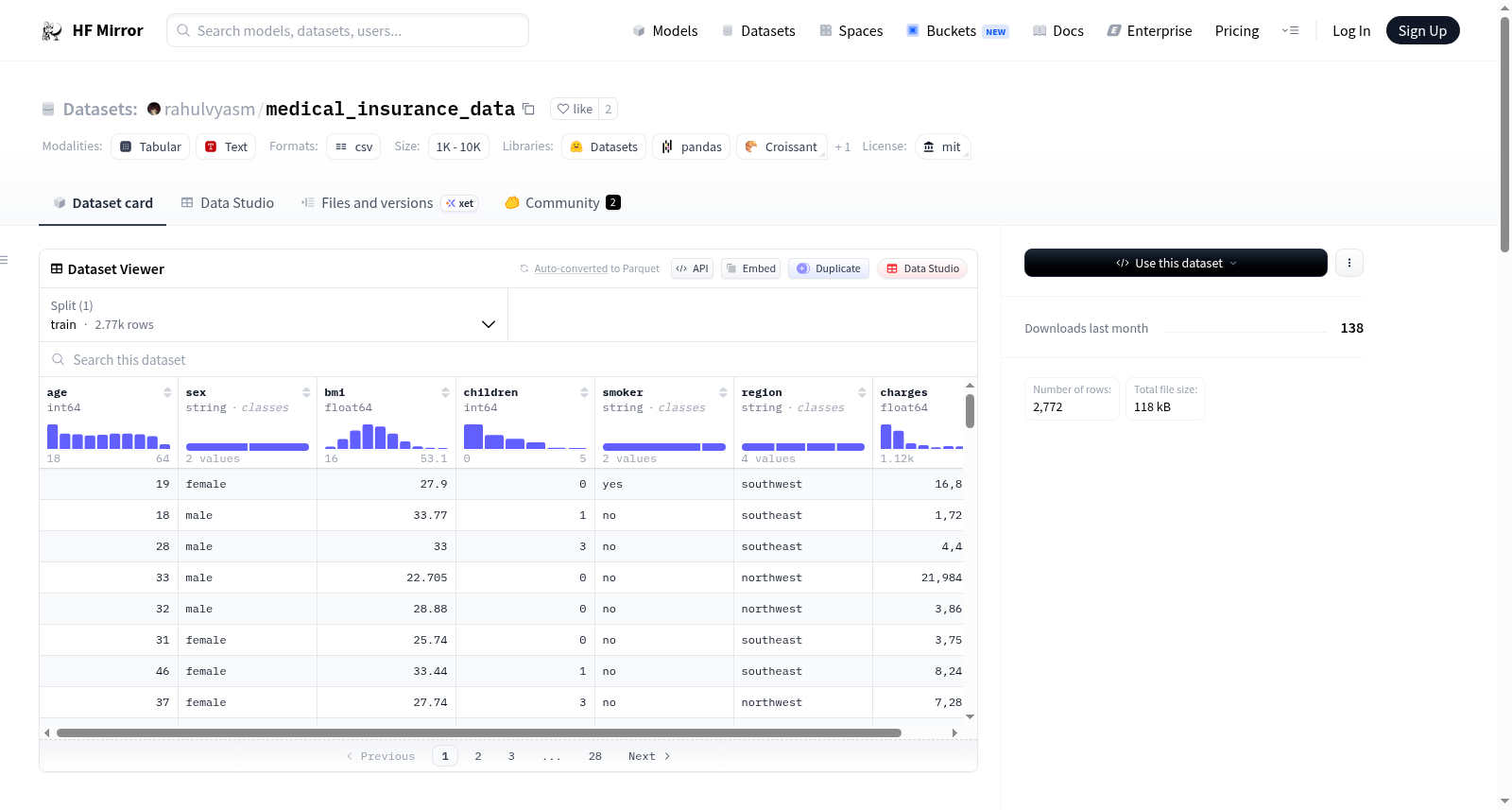
The dataset contains **2.7K rows** and **7 columns**
**Columns include**
1. Age
2. Sex
3. BMI (Body Mass Index)
4. Children
5. Smoker
6. Region
7. Charges
#### Table of Contents
- [Introduction](#introduction)
- [Problem Statement](#problem-statement)
- [Features](#features)
- [Technologies Used](#technologies-used)
- [Usage](#usage)
- [Installation](#installation)
- [Data Preparation](#data-preparation)
- [Model Training](#model-training)
- [Model Evaluation](#model-evaluation)
- [Model Serialization](#model-serialization)
- [Contributors](#contributors)
- [License](#license)
#### Introduction
Healthcare costs are a significant concern for individuals and families worldwide. Predicting medical insurance costs accurately can help insurance companies determine premiums and assist individuals in planning their healthcare expenses. This project focuses on building machine learning models to predict insurance costs based on demographic and health-related attributes.
#### Problem Statement
1. What are the most important factors that affect medical expenses?
2. How well can machine learning models predict medical expenses?
3. How can machine learning models be used to improve the efficiency and profitability of health insurance companies?
#### Features
- **Data Exploration**: Explore the dataset to understand its structure, identify missing values, and analyze the distribution of features.
- **Data Preprocessing**: Prepare the data by handling categorical variables, renaming columns, and scaling numerical features.
- **Model Training**: Utilize linear regression and ridge regression models to train predictive models on the prepared dataset.
- **Pipeline Construction**: Construct a data preprocessing pipeline to streamline the process of transforming input data for model training.
- **Model Evaluation**: Evaluate model performance using metrics such as R-squared score and mean squared error to assess predictive accuracy.
- **Model Serialization**: Save trained models and pipelines to disk using the pickle library for future use.
#### Technologies Used
- **Python**: Programming language used for data manipulation, analysis, and model implementation.
- **Libraries**: NumPy, Pandas, Seaborn, Matplotlib, and Scikit-learn for data handling, visualization, and machine learning tasks.
- **Machine Learning Models**: Linear Regression, Ridge Regression
- **Pickle**: Python library used for serializing trained models and pipelines to disk.
### Dataset Sources
From multiple online and offline datasets
## Problem Statement
1. What are the primary factors influencing medical expenses?
2. How accurate are machine learning models in predicting medical expenses?
3. In what ways can machine learning models enhance the efficiency and profitability of health insurance companies?
提供机构:
rahulvyasm
原始信息汇总
数据集概述
数据集名称
Medical Insurance Cost Prediction
数据集描述
该数据集包含2.7K行和7列,主要用于训练机器学习模型以预测新保单持有人的医疗费用。数据集涵盖了影响医疗费用的各种因素,如年龄、性别、BMI、吸烟状态、子女数量和地区。
数据集目的
旨在揭示导致保险成本增加的关键因素,帮助公司在定价和风险评估方面做出更明智的决策。
数据集结构
- 行数:2.7K
- 列数:7
- 列信息:
- Age
- Sex
- BMI (Body Mass Index)
- Children
- Smoker
- Region
- Charges
数据集用途
用于构建和训练机器学习模型,以预测基于人口统计和健康相关属性的医疗费用。
技术使用
- 编程语言:Python
- 库:NumPy, Pandas, Seaborn, Matplotlib, Scikit-learn
- 机器学习模型:线性回归、岭回归
- 模型序列化:使用Pickle库
许可证
MIT
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集是一个医疗保险成本预测数据集,包含2,772行和7列,涵盖年龄、性别、BMI、子女数、吸烟状态、地区和保险费用等关键特征。其目的是用于训练机器学习模型,以预测新投保人的医疗费用,并帮助保险公司进行定价和风险评估决策。
以上内容由遇见数据集搜集并总结生成


